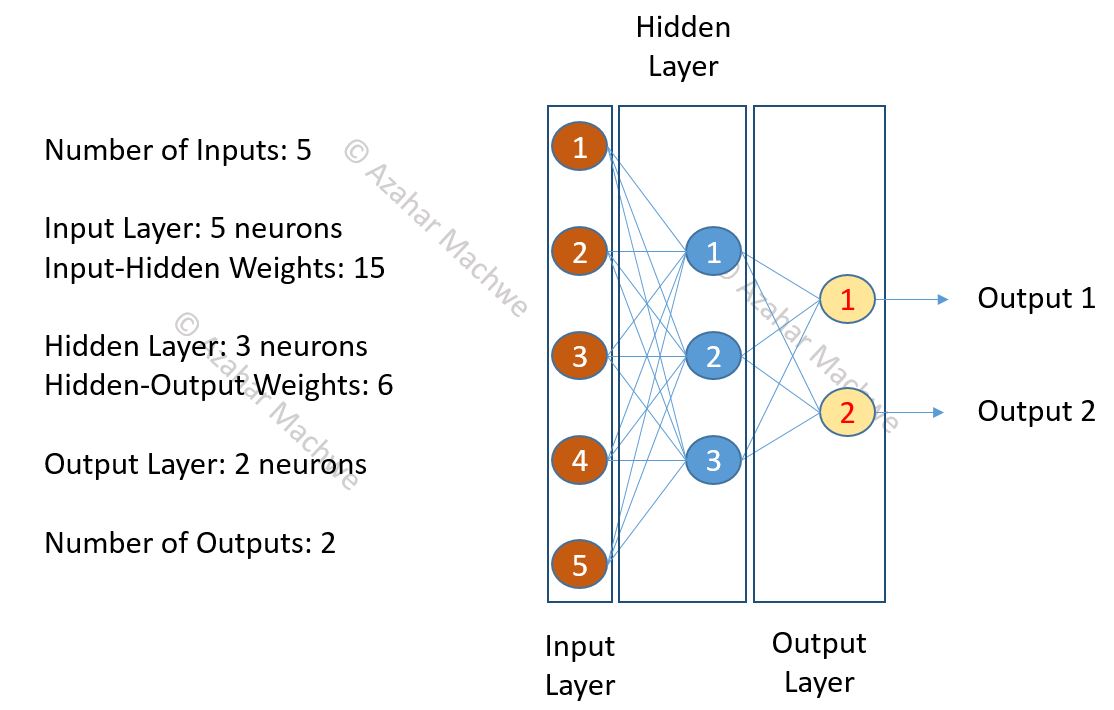
In the last post I described how we work with Multi-layer Perceptron (MLP) model of artificial neural networks. I had also shared my repository on GitHub (https://github.com/amachwe/NeuralNetwork).
I have now added a Single Perceptron (SP) and Multi-class Logistic Regression (MCLR) implementations to it.
The idea is to set the stage for deep learning by showing where these types of ANN models fail and why we need to keep adding more layers.
Single Perceptron:
Let us take a step back from a MLP network to a Single Perceptron to delve a bit deeper into its working.
The Single Perceptron (with a one output) acts as a Simple Linear Classifier. In other words, for a two class problem, it finds a single hyper-plane (n-dimensional plane) that separates the inputs based on their class.
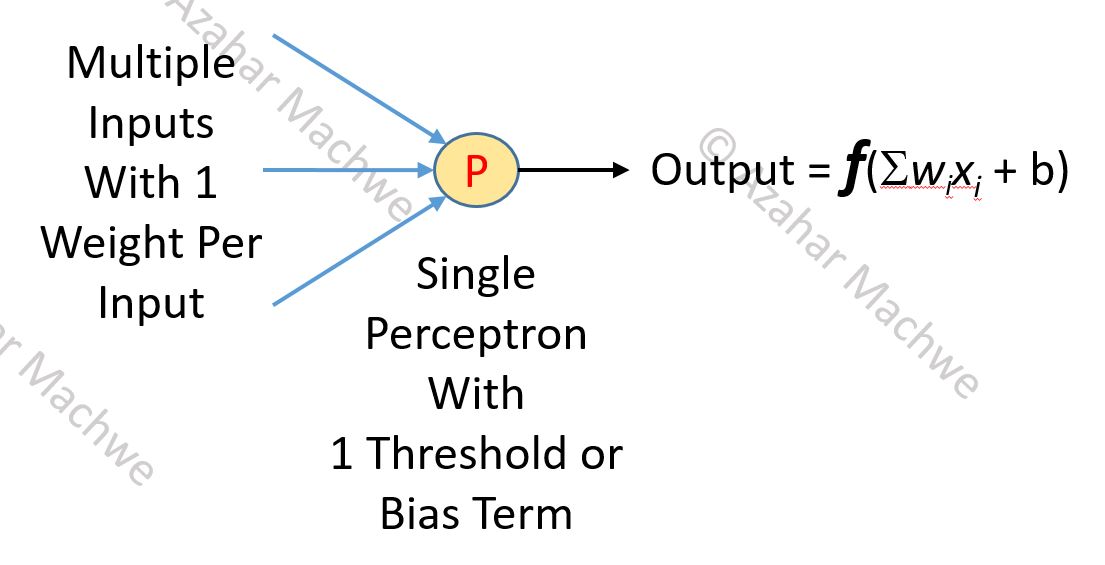
The image above describes the basic operation of the Perceptron. It can have N inputs with each input having a corresponding weight. The Perceptron itself has a bias or threshold term. A weighted sum is taken of all the inputs and the bias is added to this value (a linear model). This value is then put through a function f to get the actual output of the Perceptron.
The function f is an activation function with the simplest case being the so-called Step Function:
f(x) = 1 if [ Sum(weight * input) + bias ] > 0
f(x) = -1 if [ Sum(weight*input) + bias ] <= 0
Perceptron might look simple but it is a powerful model. Implement your own version or walk through my example (rd.neuron.neuron.perceptron.Perceptron) and associated tests on GitHub if you are not convinced.
At the same time not all two-class problems are created equal. As mentioned before, the Single Perceptron partitions the input space using a hyper-plane to provide a classification model. But what if no such separation exists?

The image above represents two very simple test cases: the 2 input AND and XOR logic gates. The two inputs (A and B) can take values of 0 or 1. The single output can similarly take the value of 0 or 1. The colourful lines represents the model which should separate out the two classes of output (0 and 1 – the white and black dots) and allow us to classify incoming data.
For AND the training/test data is:
- 0, 0 -> 0 (white dot)
- 0, 1 -> 0 (white dot)
- 1, 0 -> 0 (white dot)
- 1, 1 -> 1 (black dot)
We can see it is very easy to draw a single straight line (i.e. a linear model with a single neuron) that separates the two classes (white and black dots), the orange line in the figure above.
For XOR the training/test data is:
- 0, 0 -> 0 (white dot)
- 0, 1 -> 1 (black dot)
- 1, 0 -> 1 (black dot)
- 1, 1 -> 0 (white dot)
For the XOR it is clear that no single straight line can be drawn that can separate the two classes. Instead what we need are multiple constructs (see figure above). As the single perceptron can only model using a single linear construct it will be impossible for it to classify this case.
If you run a test with the XOR data you will find that the accuracy comes out to be 50%. That might sound good but it is the exact same accuracy if you were to guess one of the classes constantly and the classes were equally distributed. For the XOR case here, as the 0’s and 1’s are equally distributed if we kept guessing 0 or 1 constantly we would still be right 50% of the time.
To put this in contrast to a Multi Layer Perceptron which gives an accuracy of 100%. What is the main difference between a MLP and a Single Perceptron? Obviously the presence of multiple Perceptrons organised in layers! This makes it possible to create models with multiple linear constructs (hyper-planes) which are represented by the blue and green lines in the figure above.
Can you figure out how many units we would need as a minimum for this task? Read on for the answer.
Solving XOR using MLP:
If you used the logic that for the XOR example we need 2 hyper-planes therefore 2 Perceptrons would be required your reasoning would be correct!
Such a MLP network usually would be arranged in a 2 -> 2 -> 1 formation. Where we have two input nodes (as there are 2 inputs A and B), a hidden layer with 2 Perceptrons and a aggregation layer with a single Perceptron to provide a single output (as there is just one output). The input layer doesn’t do anything interesting except presents the values to both the hidden layer Perceptrons. So the main difference between this MLP and a Single Perceptron is that:
- we add 1 more processing unit (in the hidden layer)
- to aggregate the output to a single variable an aggregation unit (output layer)
If you check the activation of the individual Perceptrons in the hidden layer (i.e. processing layer) of a MLP trained for XOR you will find a pattern for the activation when presented with type 1 Class (A = B – white dot) and when presented with a type 2 Class (A != B – black dot). One possibility for such a MLP is that:
- For Class 1 (A = B – white dot): Both the neurons either activate or not (i.e. outputs of the 2 hidden layer Perceptrons are comparable – so either both are high or both are low)
- For Class 2 (A != B – black dot): The neurons activate asymmetrically (i.e. there is a clear difference between the outputs of the 2 hidden layer Perceptrons)
Conclusions:
Thus there are three takeaways from this post:
a) To classify more complex and real world data which is not linearly separable we need more processing units, these are usually added in the Hidden Layer
b) To feed the processing units (i.e. the Hidden Layer) and to encode the input we utilise an Input Layer which has only one task – to present the input in a consistent way to the hidden layer, it will not learn or change as the network is trained.
c) To work with multiple Hidden Layer units and to encode the output properly we need an aggregation layer to collect output of the Hidden Layer, this aggregation layer is also called an Output Layer
I would again like to bring up the point of input representation and encoding of output:
- We have to be careful in choosing the right input and output encoding
- For the XOR and other logic gate example we can simply map the number of bits to the number of inputs/outputs but what if we were trying to process handwritten documents – would you have one character per output? How would you organise the inputs given that the handwritten data can be of different length?
In the next post we will start talking about Deep Learning as we have provided two very important reasons for so-called shallow networks to fail.