So over the Christmas holidays I have been busy playing with my 4 x Raspberry Pi 3 (Model B) units which I have assembled into a stack. They each have a 16 GB Memory Card with Raspbian.
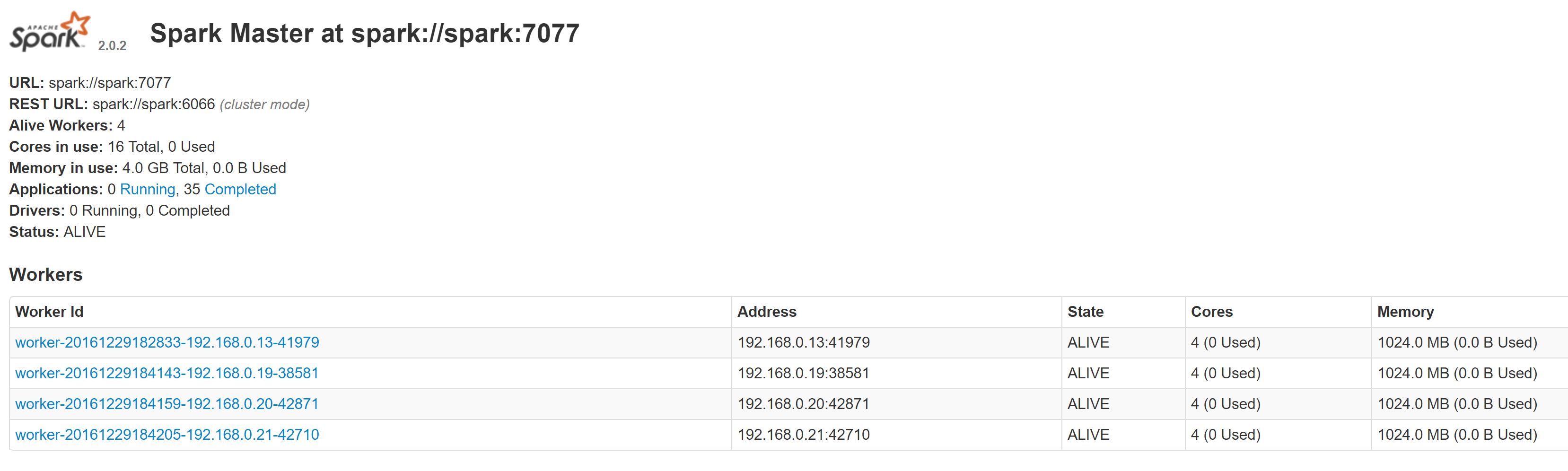
The Spark Master is running on a NUC (the Spark driver program runs there or I simply use the ‘spark-shell’).
If you want to make your own cluster here is what you will need:
- Raspberry Pi 3 Model B (I bought 4 of them – just the Pi’s – don’t bother with the ‘Kit’ because you won’t need the individual cases or power supplies).
- Rapbian on a Memory Card (16GB will work fine) for each Pi.
- A stacking plate set (one per Raspberry Pi to mount it) and one pair of ‘end plates’. This acts as a ‘rack’ for your Pi cluster. It also makes sure your Pi boards get enough ventilation and you can place the whole set neatly in a corner instead of having them lying around on the dining table!
- Multi-device USB power supply (I would suggest Anker 60W PowerPort with 6 USB ports – which can support up to 6 Pi 3’s) so that you end up with one power plug instead of one plug per Pi.
- To connect the Pi boards to the Internet (and to each other – for the Spark cluster) you will need a multi-port Gigabit switch – I would suggest buying one with at least 8 ports as you will need 1 port per Pi and 1 port to connect to your existing network.
- A wireless keyboard-trackpad to setup each Pi (just once per Pi).
- A single HDMI cable to connect with a TV/Monitor (just once per Pi).
Setting up the Pi boards:
Once you have assembled the rack and mounted the boards, install the memory cards on all the boards and connect them to the power supply and the network. Wait for the Pi boards to boot up.
Then one Pi at a time:
- Connect a keyboard, mouse and monitor – ensure the Pi is working properly then:
- Set hostname
- Disable Wireless LAN (as you have Ethernet connectivity- which is more stable)
- Check SSH works – this will make sure you can remotely work on the Pi

Once all that is done and you can SSH into the Pi boards – time to install Spark:
Again one Pi at a time:
- SSH into the Pi and use curl -o <spark download url> to download Spark tar.gz
- tar -xvf <spark tar.gz file> to unzip the tar.gz to a standard location (I use ‘/spark/’ on all the Pi boards)
- Make sure correct permissions are assigned to the spark folder
- Add the master machine hostname to the /etc/hosts file
- Edit your ~/.bashrc and add the following: export SPARK_HOME = <the standard location for your spark>
Similarly install Spark on a node which you will use as the ‘spark cluster master’ – use the same standard location.
Start up master using the spark ‘start-master.sh’ script. If you go to http://<IP of the Master Node>:8080/ you should see the Spark webpage with the status of the Workers (empty to start with) and various other bits of useful information such as the spark master URL (which we will need for the next step), number of available CPUs and application information. The last item – application information – is particularly useful to track running applications.
SSH into each of the Pi boards and execute the following: ‘start-slave.sh spark://<IP of the Master Node>:7077’ to convert each Pi board into a Spark slave.
Now if you look at the Spark webpage you will see each of the Slave nodes up (give it a couple of minutes) and you will also see the cluster resources available to you. If you have 4 Pi boards as slaves you will see 4 * 4 = 16 Cores and 4 * 1 GB = 4 GB Memory available.
Running Spark applications:
There are two main things to remember when running a Spark application:
- All the code that you are running should be available to ALL the nodes in your cluster (including the master)
- All the data that you are using should be available to ALL the nodes in your cluster (including the master).
For the code – you can easily package it up in the appropriate format (language dependent – I used Java so I used Maven to build a JAR with dependencies) and network share a folder. This reference can be used when using the spark-submit command (as the location of the application package).
For the data – you have two options – either use a network share as for the code or copy the data to the SAME location on ALL the nodes (including the master). So for example if on the master you create a local copy of the data at ‘/spark/data’ then you must use the SAME location on all the Pi boards! A local copy is definitely required if you are dealing with large data files.
Some tests:
For my test I used a 4 GB data file (text-csv) and a simple Spark program (using ‘spark-shell’) to load the text file and do a line count.
1: Pi Cluster (4 x Raspberry Pi 3 Model B)
- Pi with Network shared data file: > 6 minutes (not good at all – this is just a simple line count!)
- Pi with local copies of the data file: ~ 51 seconds (massive difference by making the data local to the node)
2: Spark standalone running on my laptop (i7 6th Gen., 5600 RPM HDD, SATA3 SSD, 16 GB RAM)
- Local data file on HDD: > 1 min 30 seconds (worse than a Pi cluster with locally copied data file)
- Local data file on SSD: ~ 20 seconds (massive difference due to the raw speed of the SSD!)
Conclusion (Breaking the Cluster):
I did manage to kill the cluster! I setup a more complicated data pipeline which does grouping and calculations using the 4 GB data file. It runs within 5 mins on my laptop (Spark local). The cluster collapsed after processing about 50%. I am not sure if the issue was related to the network (as a bottleneck) or just the Pi not able to take the load. The total file size is greater than the total available memory in the cluster (some RAM is required for the local OS as well).
So my Spark cluster is not going to break any records, in fact I would be better off using a Spark standalone on my laptop if it is a one-shot (i.e. process large data file and store the results somewhere).
Things get interesting if we had to do this once every few hours and we could automate the ‘local data copy’ step – which should be fairly easy to do. The other option is to create a fast network share (e.g. using SSDs).
What next:
Some nice project which would suit the capabilities of a Pi cluster? Periodic data processing/stream processing task? Node.JS Servers? Please comment and let me know!

