These days you don’t have to shell out thousands of pounds for an OpenFlow switch. Especially if you don’t mind lesser number of ports and devices that are not blazingly fast. I purchased a Zodiac FX OpenFlow switch and have been trying out different projects with it. The switch has 4 ports at 100M each with Port 4 reserved for management.
To make a Traffic Snooper we need to mirror ports that allow ingress into and egress from the internal network. Port mirroring means sending same traffic to the target port as well as a mirror port. We may also filter traffic that is mirrored (e.g. we may only want to mirror Layer 4: UDP traffic).
For the Zodiac FX, I selected Port 2 to be the mirror port. Traffic exiting the internal network will arrive on Port 1 and be sent out from Port 2 and Port 3 (Apply Action List). Similarly traffic entering the internal network from the Internet will arrive on Port 3 and be sent out from Port 2 and Port 1.
Thus Port 2 will receive packets from both the directions. Port 2 is attached directly to a Raspberry Pi with Link Local addressing enabled. This means that the port on the Raspberry Pi has a link local IP address assigned to it. We don’t really care about this because we are already forcing the traffic to come this way using a static flow.
On the Traffic Snooper Pi I run my Python based Traffic collector. This utilises raw sockets to listen for traffic. All data is converted into hex and dumped into the Analytics Store database (Mongo DB). This is a fairly simple utility perfect for a lightweight platform like the Pi. It does not do any processing of the network data. It simply stores it in a database. The source code is attached for both the Snooper and the static controller which uses Ryu.
The Traffic Snooper needs the following to read from the raw socket that is getting data from port 2 of the switch (the mirrored port):
s = socket.socket(socket.AF_PACKET, socket.SOCK_RAW, socket.htons(3))
The line above can be interpreted as:
Open a socket that uses Address Family (AF) of Packets (you will need to run snooper with sudo to provide access) that will allow access to Layer 2 information. The socket is a raw type – therefore Layer 2 headers will not be stripped. Finally we provide the host to network byte order conversion (htons).
This gives us a socket that pulls the packet with all the information (headers) intact and also ensures the byte ordering is correct.
The Traffic Snooper also stores the packet hash to ensure we do not store duplicate packets (this can be disabled if required).
Note: port 2 will not get any direct assignment of IP address (we don’t want any traffic to use this port for communication – only mirrored traffic should use this port) and should default to a ‘link-local’ IP address. In case of IPv4, link-local addresses are defined in the address block 169.254.0.0/16
Static_Controller.py: https://docs.google.com/document/d/e/2PACX-1vRU8ZAa5Vl03UwC5K61Rt9Me0y0tvKq_0s8lCm7aH9t7vN_Z6qnUMQgINPFdCrt9BM-kBkJh3uuJCyw/pub
The installed flows:
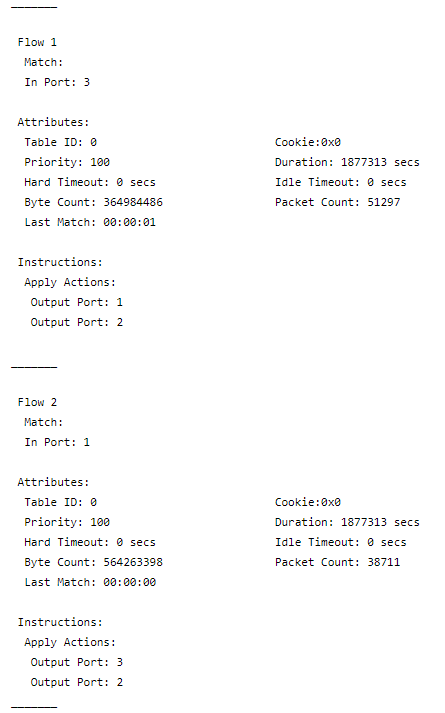
The OpenFlow Specification allows multiple Apply Actions. We use this to create duplicated traffic flows.
Flow 1: All traffic coming in from port 3 is forwarded to port 2 and 1. Here port 2 is the port connected to the analyser.
Flow 2: All traffic coming in from port 1 is forwarded to port 2 and 3.
Note: The controller is a static controller. In other words we use Ryu to install flows and then the controller is disconnected (thus flow timeout=0). To achieve this we use the ‘safe’ mode on the Zodiac FX which does not remove the flows that have been installed. As the Zodiac FX is a pure OpenFlow switch it does not support standalone mode.
Next Step: Next post will look at the traffic analyser that breaks down the incoming packet and pulls out various protocol related information.
Follow-up: I have used Zodiac FX for this post and not something like OpenVSwitch (which has several advanced features such as port mirroring and built in learning switch in ‘standalone’ mode) because I wanted to use a pure OpenFlow device that does nothing till you don’t provide the flows.
OVS Implementation
It is fairly straight forward if you want to setup your Pi as a OVS switch. You will need USB-Ethernet plugs and a freshly formatted Pi. I used the lightweight no-desktop ‘Stretch’.
This is a good guide to follow:
https://www.telematika.org/post/piovs-raspberry-pi-open-vswitch/
I only needed the ‘Install OVS’ and ‘Configure Interfaces’ step.
Below are the three interfaces I created, ‘eth2’ is the interface to the snooper and ‘eth3’ the ‘internet’ interface.
auto eth1
iface eth1 inet manual
hwaddress ether 00:0e:c6:de:54:15
auto eth2
iface eth2 inet manual
hwaddress ether 00:0e:c6:df:ae:ac
auto eth3
iface eth3 inet manual
hwaddress ether 00:0e:c6:df:ae:c2
auto ovsbr0
allow-ovs ovsbr0
iface ovsbr0 inet manual
ovs_type OVSBridge
There are few things to watch out for:
- The interface on the Raspberry Pi running the snooper application should not be reachable from the network. This is because we do not want any traffic headed for that port. We only want to record traffic flowing between 1 and 3. Therefore, the Pi connected to port 2 of the switch should have two interfaces. One that has a valid local network address – to allow snooper to access the database server for example. The second which is connected to the switch interface 2 which receives the copied traffic. This second interface should have a link local IP address to ensure all the traffic received there either for port 1 or 3.
- Set the fail mode to ‘secure’ in OVS. If you do not set the fail mode in OVS to ‘secure’ then it will fall back to learning switch mode (standalone mode) and start faithfully switching traffic. This will mean (in short) your snooper Pi will have an IP address assigned to the port that is sniffing the mirrored traffic. Once you install the flows then the traffic will be mirrored but you can still get extra packets not part of the flow that we are monitoring.
- Use ‘sudo ovs-vsctl get-fail-mode <bridge_name>‘ to get the fail mode and then ‘sudo ovs-vsctl set-fail-mode <bridge_name> secure‘ to set to secure mode (replace bridge_name with the name of your OVS bridge). This will disable the learning switch and you will need to use the static-controller to setup the snooper flows.
- You can use ‘sudo ovs-appctl fdb/show <bridge_name>‘ to show the forwarding db (this stores the result of the mac learning) and ‘sudo ovs-appctl fdb/flush <bridge_name>‘ to clear the forwarding db.
