Gameplaying is no child’s play! Simple games can have deep tactical and strategic choices that can have a big impact on the end result. Modern board games include multiple different gameplay mechanics like dice rolling for probabilistic decision making, decision making under incomplete information, resource management and so on. They have now given way to games that can be played by a single player where either a set of rules (e.g. Legend of Drizzt) or a smartphone app (e.g. Mansions of Madness) play the role of the Game Keeper/director.
Each game has a target/goal that helps define the win/loss conditions. This may be static (kill your opponents ‘king’), evolving (find something then do something with that object) or time-based (e.g. survive 10 turns).
Game turns are usually divided into phases which groups behaviour different class of agents (such as human players, monsters, world effects). So each game turn might begin with a preparation phase, a hero-action phase, a monster-action phase and so on. In the hero-action phase (usually) the human players can choose one or more actions from a set of actions (e.g. move, explore/search, attack etc.) and execute it by spending some limited resource (e.g. action point, potion, item etc.). This is where the tactics and strategy come into the picture. Similarly, during the monster-action phase we may use some rule-based mechanic to decide what the monster does (e.g. monster moves one square closer to the nearest hero) or this can be decided by the Game Keeper/director. Finally there are always constraint mechanisms that help decide the reward signal (e.g. health, turns left) as a consequence of our actions. For example – my hero can choose to fight a monster or attempt to sneak away – what should I choose? We might make a tactical choice to sneak away if our health is low or risk an encounter if we feel we are much stronger than the monster. Games can also have a time-constraint where once the time runs out something good/bad happens.
Game environment usually consist of some grid system which allows for exploration and a set of agents and game elements (e.g. resources, locations) that are oriented on the grid. Grid system may provide complete information (i.e. all parts of the grid are visible) or incomplete information (i.e. the grid is built up as we play and make choices).
Similar concepts also exist in video-games. But they are lot less discreet. For example when we play a shooting game like Doom we move in a continuous way. There is no grid (or a the grid has infinitely small squares). We still have mechanics around action choices and reward signals.
As an example for a common game: Chess –
target is to kill your opponents king
grid is the chess board
agents are the two players (or 1 player and 1 AI) – chess pieces are the tokens used to play the game
phase in chess consists of a phase for each player to move
action just one basic action of movement – this includes the action to ‘kill’ an opposing piece
reward win/loss, number of pieces left etc.
constraints number of pieces left, in some fixed length games – the number of turns etc., number of squares on the chess board
Game Playing Gym
So why this lengthy discussion around this topic? I want to explore concepts around automated-gameplaying. I was also interested in building a game environment. Therefore, I built a ‘gym’ environment using python and PyGame where I can play around with different automated game-playing methods.
target is for both knights to survive 250 game turns per knight
grid is the environment consisting of mountain, water and grass squares
agents are two knights and a dragon. The dragon operates on a fixed rule-set (scan, move and attack nearest). Knights will be controlled by automated gameplaying methods.
phase – there is a hero phase for each knight followed by a monster phase for the dragon
action seven actions to choose from: move (x4 up, down, left, right), search (for food), farm (grow food), rest (heal)
reward food quantity, health quantity, amount of area explored
constraints health, food – if food goes to zero health starts to drop – all actions cost 1 food
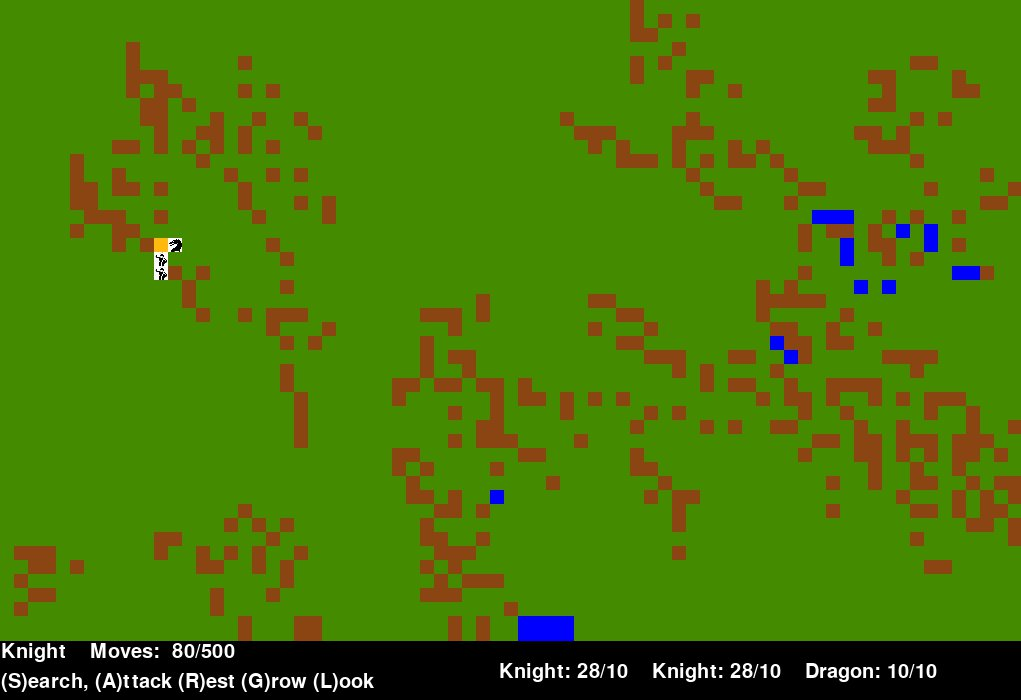
Figure 1: Example of the Game Environment
In Figure 1 we can see the game environment. Green blocks are grasslands where food is available and farming can be done. Brown blocks are mountains and blue blocks are water. The yellow block is a grassland block exhausted by searching for food. Exhausted block can be regenerated by using the ‘farm’ action.
Two white blocks below the barren block are the two knights and the white block to the right of it is the dragon. Against each Knight we can see their food (uncapped) and health value (capped at 10).
Reward Maximisation – No Constraints
In the above video you can see the dragon is taking a snooze and the knights are busy exploring the land. You might think that the knights have been ‘programmed’ to avoid mountains and navigate through. But that is not the case. We use reward signals for deciding where the knights should go.
As we know in any kind of agent-based system we have a loop like below:
- Agent reads state of the environment (or observes the environment)
- Agent reads the reward signal (zero for first loop)
- Agent decides and executes next action on the environment
- This causes the state of the environment to change and a reward signal to be generated
- Check state/observation for Termination condition, if not met then go to (1)
In our case the knights are getting the full state of the environment as opposed to observing/sampling the state indirectly. The environment state consists of their health, their food and their location (which includes cell type and the food available if a grassland type of cell).
Since state transitions are not stochastic and the knights have full access to the state transition functions they can evaluate each of the seven actions at each stage and select the action that maximises the reward (in which health is the most important component) in the next step. This simple rule can lead to a lot of sophisticated behaviour that you see in the above video. Even there note how there are absolutely no constraints on the knights and they can keep moving, searching and stockpiling the food (see the food number go up!). These knights are just greedy!
We can make the state transition stochastic by randomly changing the amount of food the agent gets when searching or the direction of movement when selecting a move action.
Again if we have the transition graph (generated by Markov Decision Process) available then we can easily use Value Iteration or Policy Iteration to come up with an optimum policy for each state. I will show an example of this in the next post.
Reward Maximisation with Constraints
Let us make life slightly difficult for our greedy knights (well at least for one of them). In the video below we just change the starting position of the dragon. Now the dragon is going to continuously harass one of the knights.
Remember we have not changed anything else in the program! Just moved the dragon closer to one of the knights so that it enters the dragons area of awareness. The simple rule-based AI of the dragon will ensure it tracks the knight.
Now our knight has to be slightly cleverer than before! It can no longer just gather food. It now has to gather food, loose food to heal (if dragon has attacked successfully) and move. It may also choose to regenerate an area if it can afford to. Remember again reward signal has health as the most important component. The knight, using reward maximisation, automatically starts doing this in a sequence. We see that it keeps moving and surviving (keeping health > 0) while it collects food to heal. This adds a big constraint to its food gathering capability and doesn’t allow it to stockpile any food. The other knight – not bothered by a dragon – is able to continue its greedy behavior. We can tune the aggressiveness of the dragon by tuning its attack probability.
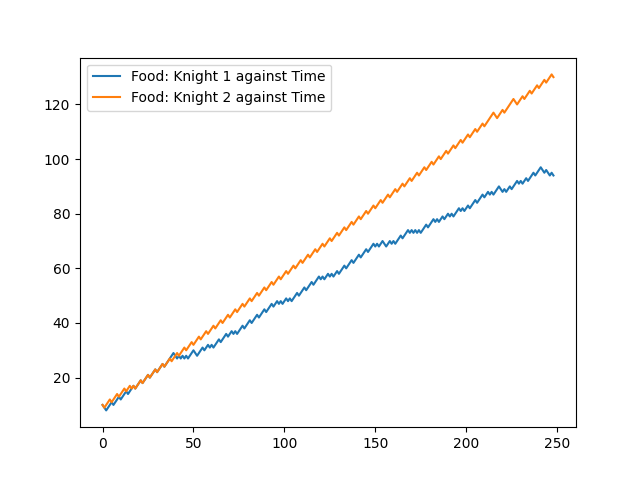
We can see in Figure 2, for a high attack probability (0.9), the knight under attack (knight 2) is overwhelmed and killed (compare with knight 1 that is steadily stockpiling food). This means that knight 2 is not able to gather, heal and move fast enough under the relentless attack of the dragon. We may improve survival chances if we had an ‘attack’ action?
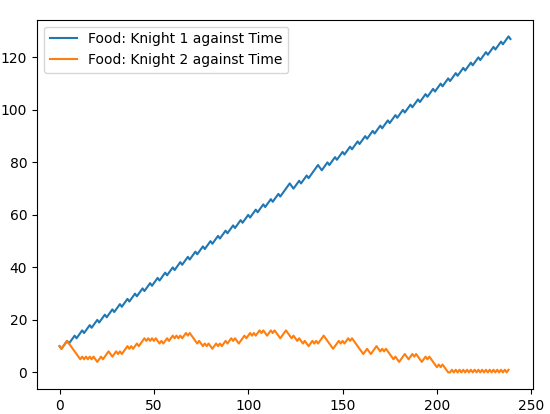
We can see in Figure 3, for a lower attack probability (0.6), the knight under attack (knight 1) is not overwhelmed. Whilst it still starts falling behind the other knight it is far from any real danger of death. In this case the dragon is a bit lazy about attacking!