Large language models are complex constructs that can understand and generate language – made up of a token-probability map generator and the next token selector which uses that map to select the next token. We will explore the structure of Large LanguageModels (LLMs) using the transformers python library provided by HuggingFace.
The token generator part is the gazillion-parameter, heavy weight, neural network based, language model. We create it as below, where the ‘model’ object encapsulates the LLM:

There are different model objects associated with each model type. In the above example we are loading a version of the GPT2 model using the ‘from_pretrained’ convenience method.

The token probabilities for the next token are obtained by performing a forward pass through the model as above.
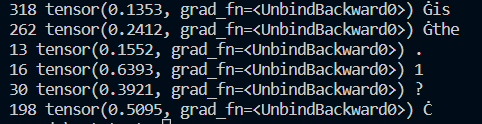
The output will be shaped according to the vocabulary size and output size of the model (e.g., 50,257 for GPT2 and 32,000 for Llama2). If we do some processing of the output and map it against the index in the ‘vocab.json’ associated with the model, we can get a probability map of tokens like below (from GPT2). The screenshot shows the token index and its probability score and text value:
The token generator and selector parts are conveniently encapsulated in the generate method associated with the model object:
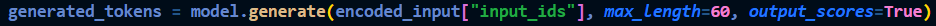
The selector uses searching and sampling mechanisms (e.g., top-k/top-p sampling and beam search) to select the next token. This component is what provides the mechanism to inject variation in the generated output. The model itself doesn’t provide any variability. The forward pass will predict the same same set of next tokens given the same input.
The forward pass is repeated again by adding the previously generated token to the input (for auto-regressive models like GPT) which allows the response to ‘grow’ one token at a time. The generate method takes care of this looping under the hood. The max_length parameter controls the number of times this looping takes place (and therefore the length of the generated output).
