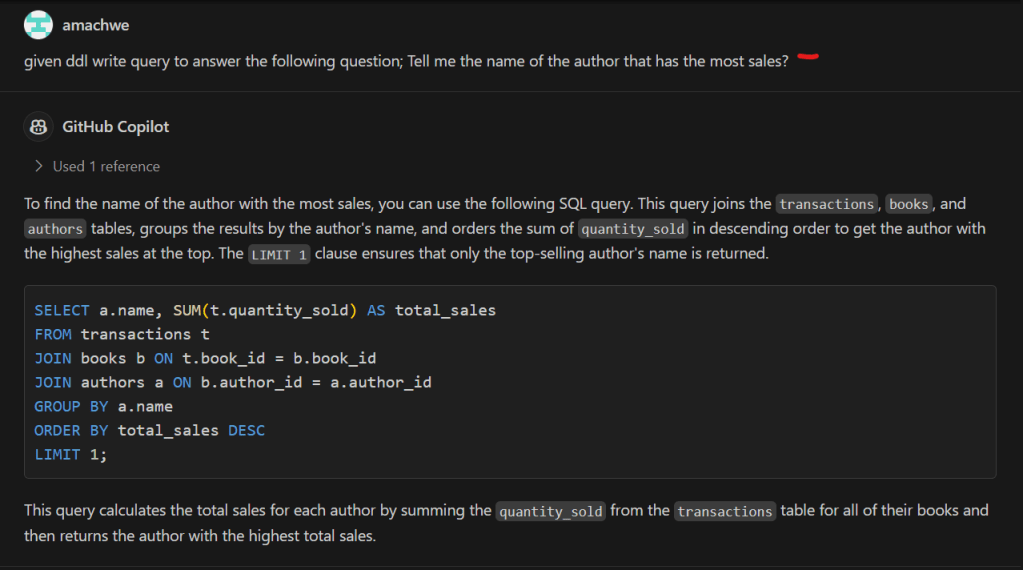
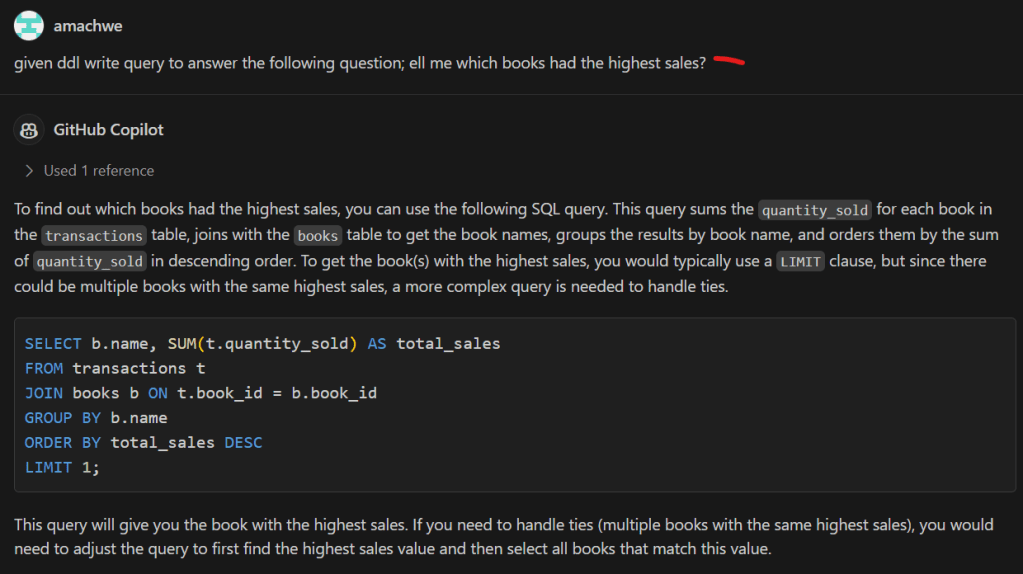
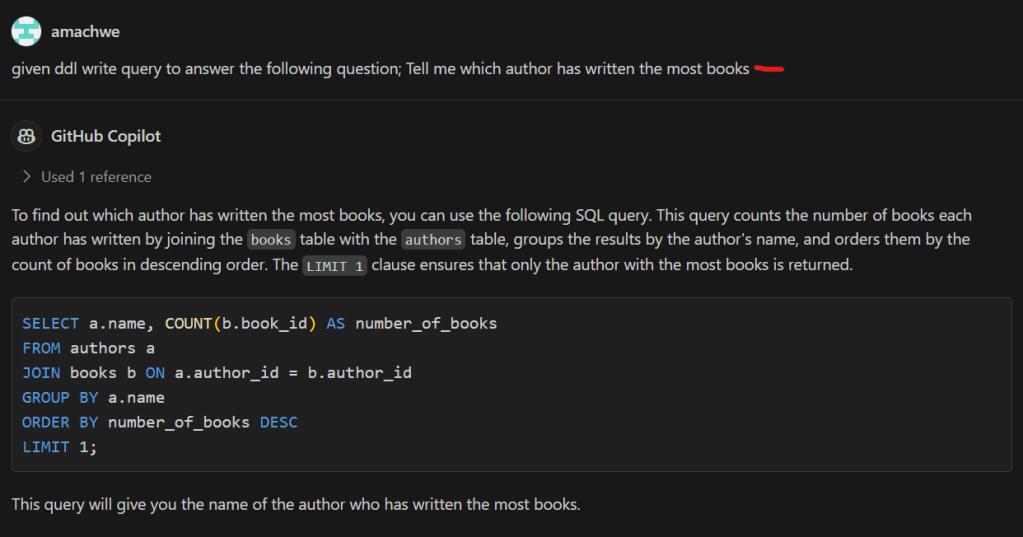
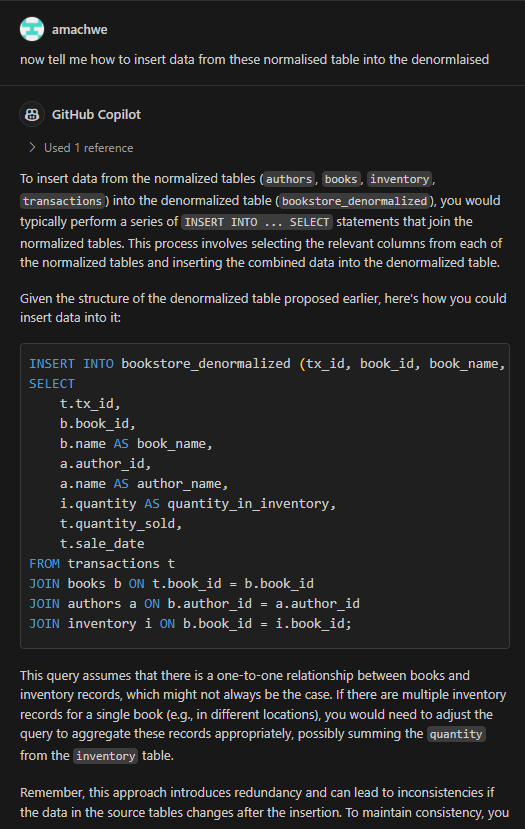
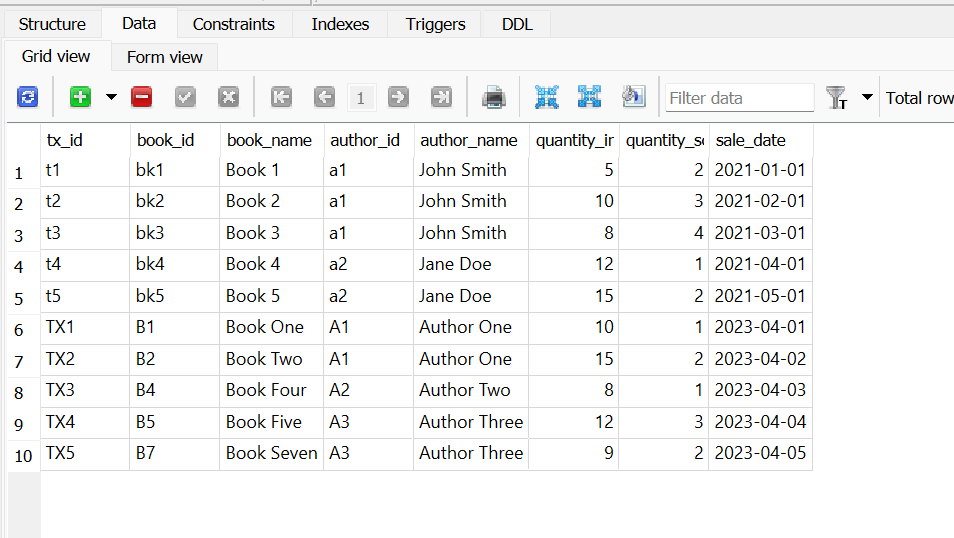
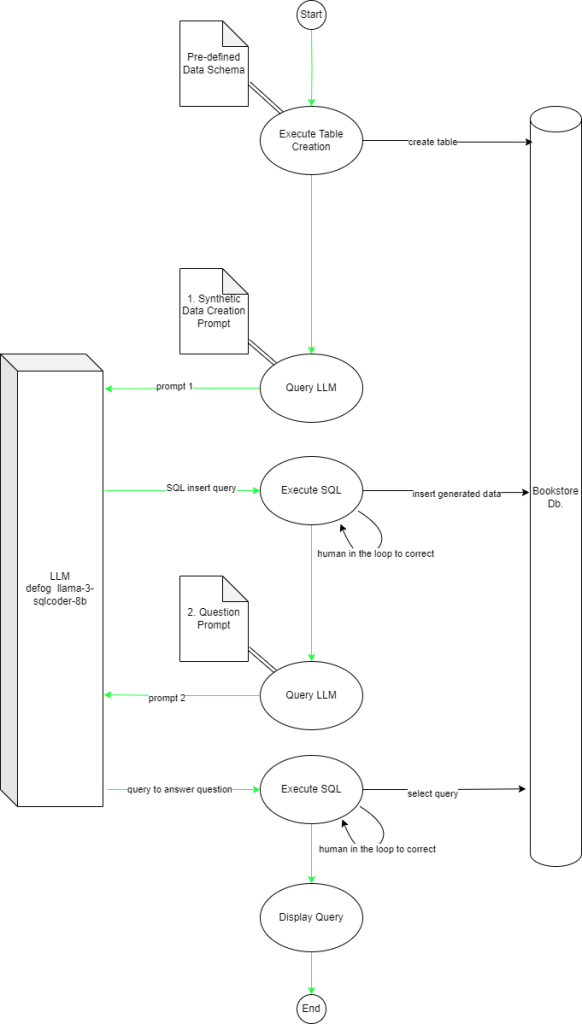
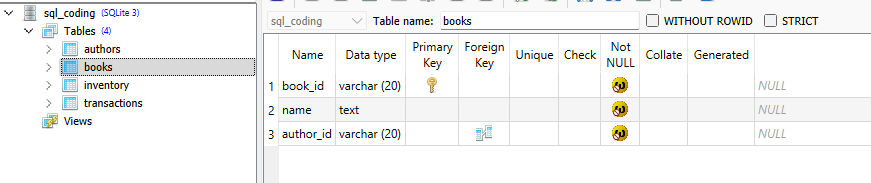
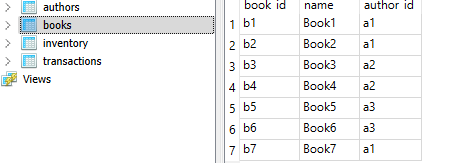
The output produced by Large language models seems even more incredible given the fact that they predict the next token (i.e., next bit of text) based on provided input (prompt) and the tokens generated so far.
The human brain does not work like this. We constantly evaluate, re-write, and re-think as we work. We also use hierarchical planning (e.g., breaking down a document into sections and sub-sections) and other methods to ‘think’ about text at various levels of detail.
LLMs on the other hand can only move forward one token at a time. There is no ‘reverse and rewrite’ mode (as yet).
So it would make sense for people to investigate generating a sequence of tokens rather than just the next token and to see if this has an impact on the quality of the output (which to be fair is already quite amazing).
This is exactly what a research team with members working in Meta have done. The paper is titled: Better & Faster Large Language Models via Multi-token Prediction
Why Multiple Tokens?
First let us understand what we mean by generating multiple tokens. Assuming we have the following prompt: “Calculate 4+6”.
A single token prediction LLM with provide the following sequential output (hidden from us because of convenience methods provided by transformers library):
- prompt -> <space>
- prompt + <space> -> 1
- prompt + <space>1 -> 0
- prompt + <space>10 -> .
- Final output: <space>10.
A multi-token prediction with length four might work as below (pipes separate tokens generated in parallel):
prompt -> <space>|1|0|.
Final output: <space>10.
Figure 1 shows the architecture that includes 4 heads to generate n=4 next tokens in parallel.
It is immediately clear if we have this kind of n token generation we are going to get massive speedup in inference at the cost of additional resource (for the extra heads). Also this will make training harder and resource intensive. To get to next-token generation the model can discard heads 2, 3, and 4.

Why Does This Work?
In their results they show significant improvements in Code related tasks and other benchmarks. The key thing to understand is that when we train using multiple-heads we are passing lot of ‘hidden’ information about token choices.
As they state in the paper, and we humans know intuitively: “Not all token decisions are equally important for generating useful texts from language models”.
Imagine when you are presented some text to read. Your brain knows the words it can skip without impacting your understanding of the text. These words may impart stylistic variation (e.g., first voice vs third-person voice) but do not add much to your understanding. These can be thought of as style tokens.
Then there will be some words that will grab your attention because they define the message in the text. These tokens they call choice points and they define the semantic properties of the text.
In a similar way LLMs have to generate (one token at a time – without any reverse-rewrite) the sequence of style tokens and choice point tokens that provides a correct response to the prompt.
Now you can probably begin to understand how LLMs can go off-track. If mistakes are made in the early choice point tokens then it is difficult to recover (as it cannot go back and reselect a different choice point). If mistakes are made in style tokens then recovery may still be possible.
When we train using multiple heads (even if we discard them during inference) we are teaching the LLM about relationships between next n tokens. And the key thing (as they show in the paper) – during training the correlated choice point tokens are weighed together with larger values than the style tokens.
In simple words two tokens that in the generation are related and add meaning to the text are given more importance than those that do not.
This looking-ahead property during training ensures that we already have a mental map (a tiny one) of what then next few words may look like when we are generating.
But n = ?
A valid question would be – what should be the value of n. In other words how big a mental map should be build during the training.
One reasonable answer would be – depends on the task – complex tasks may require bigger mental maps.
For most of the tasks they experiment with n = 4 seems to be the optimal value (except one task where it is 6). Another interesting result is that performance seems to drop at higher values of n. This is also understandable as if we try and think too far ahead we may find many ‘next steps’ and find it difficult to select the correct one.