When we use Gen AI within a workflow with predictive interactions with LLMs we can attempt to estimate the cost and time penalties.
Now agentic (true agentic – not workflows being described as agentic) is characterised by:
- Minimum coupling between agents but maximum cohesion within an agent.
- Autonomy
- Use of tools to change the environment
This brings a whole new dimension to the cost and time penalty problem making it lot harder to generate usable values.
Why Are Cost and Time Penalties Important
The simple answer is the two inform the sweet spot between experience, safety and cost.
Experience
Better experience involves using tricks that require additional LLM turns to reflect, plan and use tools, moving closer to agentic. While this allows the LLM to handle complex tasks with missing information it does increase the cost and time.
From a contact centre perspective think of this as:
- An expert agent (human with experience) spending time with the customer to resolve their query.
Now if we did this for every case then we may end up giving a quick and ‘optimal’ resolution to every customer but the costs will be quite high.
Safety
Safer experience involves deeper and continuous checks on the information flowing into and out of the system. When we are dealing with agents then we get a hierarchical system to keep safe at different scales.
Semantic safety checks / guardrails involve LLM-as-a-Judge as we expect LLMs to ‘understand’. This increases the time to handle requests as well as increases costs due to additional LLM calls to the Judge LLM.
Cost Model
This is the first iteration of the cost model.
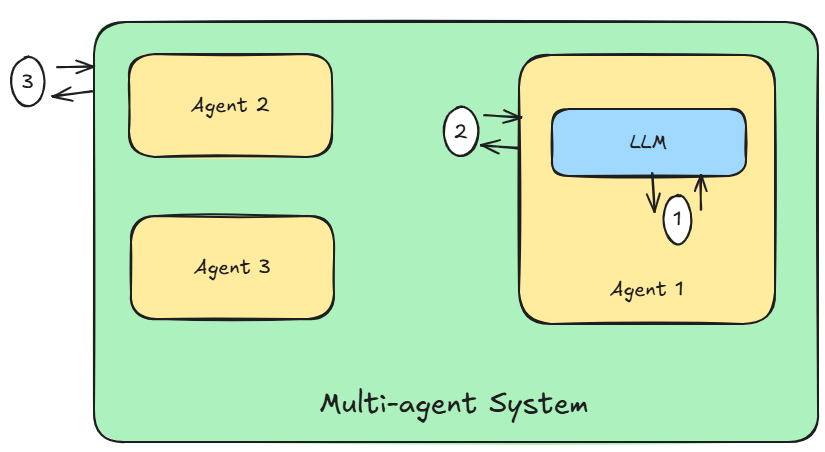
The cost model works at three levels (see Figure 1 above):
- Single Model Turn – Input-LLM-Output
- This is a single turn with the LLM.
- Single Agent Turn – Input-Agent-Output
- This is a single turn with the Agent – the output could be a tool call or a response to the user or Agent request.
- Input can be from the user or from another Agent (in a Multi-agent system) or a response from the Tool.
- Single Multi-agent System Turn – Input-Multi-Agent-System-Output
- This is a single turn with a Multi-agent system. Input can be the user utterance or external stimulus and the output can be the response to the request.
- A Multi-agent System can use deterministic orchestration, a semi-deterministic or fully probabilistic.
Single Model Turn
Item 1 in Figure 1. The base for input will be the prompt template which will be constant for a given input. We can have different input prompt templates for different sources (e.g., for tool response, user input etc.).
We assume a single prompt template in this iteration.
kI = Cost per token for input tokens (Agent LLM)
kO = Cost per token for output tokens (Agent LLM)The constant cost per turn into the model: Cc = kI * tP The variable cost per turn into the model: Cv = kI * tDTotal Cost per turn out of the model: Co = kO * tOTotal Cost per Model Turn = Cc + Cv + CoThis can be enhanced to compensate for Guardrails that use LLM-as-a-Judge. I also introduce a multiplier to compensate for parallel guardrails per turn that use LLM-as-a-Judge.
gI = Cost per token for input tokens (Judge Model)
gO = Cost per token for output tokens (Judge Model)
mG = Multiplier - for multiple parallel guardrails that use LLMs as JudgeThe variable cost per turn into the judge model: Gv = gI * (tD + tP) * mGTotal Cost per turn out of the judge model: Go = gO * tO * mGTotal Cost per Model Turn (including Governance) = Cc + Cv + Co + Gv + GoSingle Agent Turn
Here a single agent turn will consist of multiple model turns (e.g., to understand user request, to plan actions, to execute tool calls, to reflect on input etc.).
In our simple model we take the Total Cost per turn and multiply it with the number of turns to get an estimate of the cost per Agent turn.
Total Cost for Single Turn = nA * Total Cost per Model Turn
nA = Number of turns within a single Agent turnBut many Agents continuously build context as they internally process a request. Therefore we can refine this model by increasing the variable input token count by the same amount every turn.
Incremental Cost of Variable Input = Cv += kI * tD * i
where i = 1 to nA + 1 Single Turn with Multi-agent System
A single user input or event from an external system into a multi-agent system will trigger an orchestrated dance of agents where each agent plays a role in the overall system.
Given different patterns of orchestration are available from fully deterministic to fully probabilistic this particular factor is difficult to compensate for.
In a linear workflow with 4 agents we could use an agent interaction multiplier set to 5 (user + 4 agents). With a peer-to-peer a given request could bounce around multiple agents in an unpredictable manner.
The simplest model is a linear one:
Total Cost of Single Multi-agent System Turn = total Cost of Single Agent Turn * nI
nI = Number of Agent Interactions in a single Multi-agent System Turn.Statistical Analysis
Now all of the models above require specific numbers to establish costs. For example:
- How many tokens are going into a LLM?
- How many turns does an Agent take even if we use mostly deterministic workflows?
- How many Agent interactions are triggered with one user input?
Clearly these are not constant values. They will follow a distribution in time and space.
Key Concept: We cannot work with single values to estimate costs. We cannot even work with max and min values. We need to work with distributions.
We can use different distributions to mimic the different token counts, agent interactions, and agent turns.
The base prompt template token count for example can be from a choice of values.
The input data token count and output token count can be sampled from a normal distribution.
For the number of turns within an Agent we expect lower number of turns (say 1-3) to be of high probability with longer sequences being rarer. We will have at least one agent turn even if that results in the agent rejecting the request.
Same goes for the number of Agent interactions. This also depends on number of agents in the Multi-agent system and the orchestration pattern used. Therefore, this is the place where we can get high variability.
Key Concept: Agentic AI is touted as large number of agents running around doing things. This takes the high variability above and expands it like a balloon as more agents we have in a Multi-agent system wider is the range of agent interactions triggered by a request.
Some Results
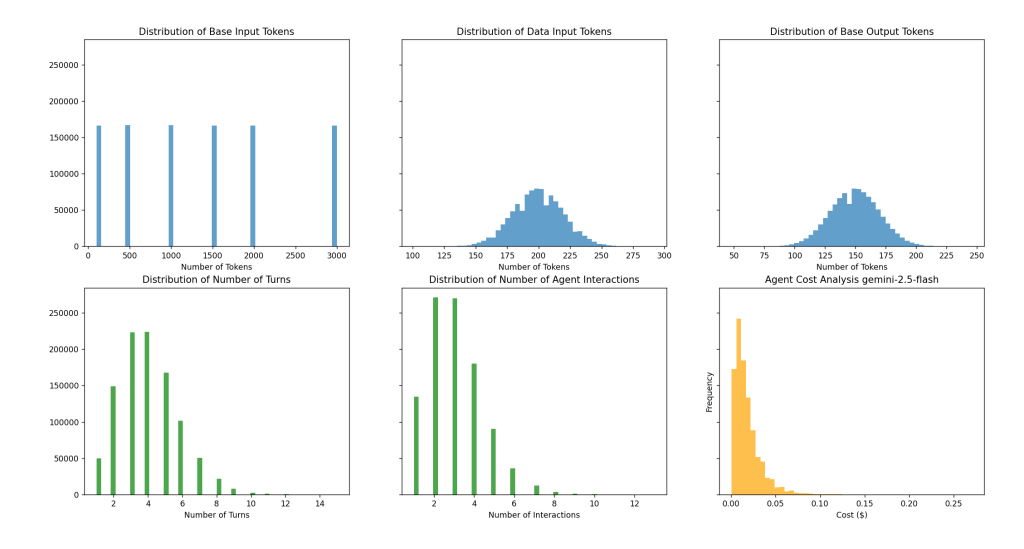
The distributions below represent the result of the cost model working through each stage repeated 1 million times. Think of this as the same Multi-agent system going through 1 million different user chats.
I have used Gemini-2.5-Flash costs for the main LLM and Gemini-2.5-Flash-Lite costs for LLM-as-a-Judge.
The blue distributions from Left-to-Right: Base Prompt Template Token Count, Data Input Token Count, and Output Token Count. These are the first stage of the Cost Model.
The green distributions from Left-to-Right: Number of turns per Agent and Number of Agent Interactions. These are the second and third stages of the Cost Model.
The orange distribution is the cost per turn.
Expected Costs:
Average Cost per Multi-Turn Agent Interaction: $0.0174756
Median Cost per Multi-Turn Agent Interaction: $0.0133794
Max Cost per Multi-Turn Agent Interaction: $0.2704608
Min Cost per Multi-Turn Agent Interaction: $0.0004264
Total Cost for 1000000 Multi-Turn Agent Interactions: $17475.6268173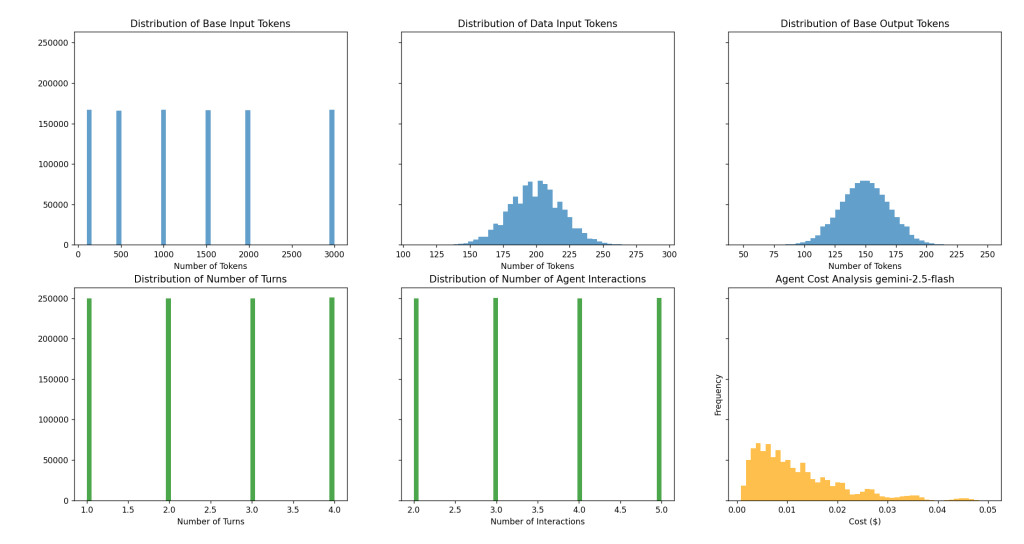
Expected Costs:
Average Cost per Multi-Turn Agent Interaction: $0.0119819
Median Cost per Multi-Turn Agent Interaction: $0.0096888
Max Cost per Multi-Turn Agent Interaction: $0.0501490
Min Cost per Multi-Turn Agent Interaction: $0.0007306
Total Cost for 1000000 Multi-Turn Agent Interactions: $11981.8778405Let us see what happens when we change the distribution for Agent turns to 4 (a small change from 2 previously).
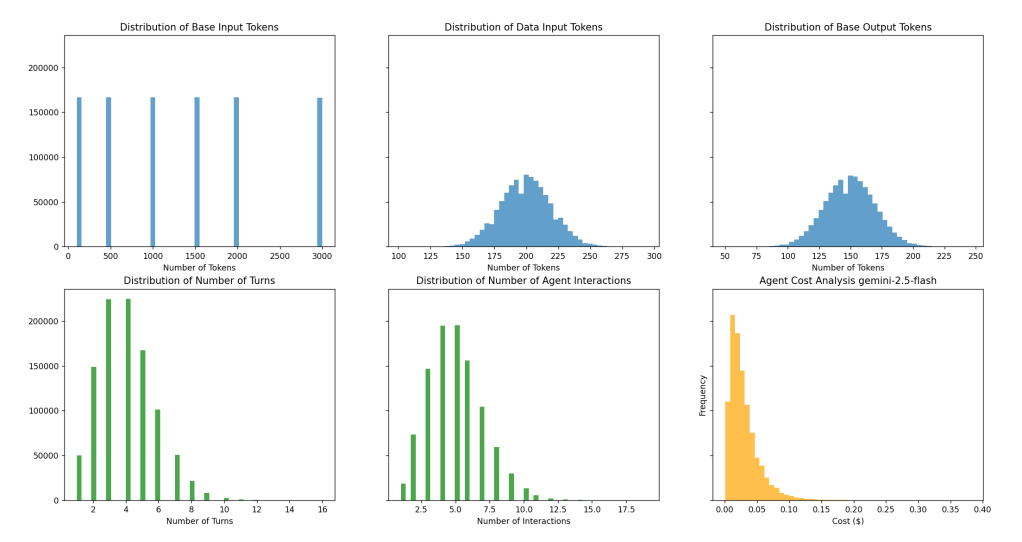
Expected Costs:
Average Cost per Multi-Turn Agent Interaction: $0.0291073
Median Cost per Multi-Turn Agent Interaction: $0.0232008
Max Cost per Multi-Turn Agent Interaction: $0.3814272
Min Cost per Multi-Turn Agent Interaction: $0.0004921
Total Cost for 1000000 Multi-Turn Agent Interactions: $29107.3320206The costs almost double from increasing agent interaction from 2 to 4.
Key Concept: The expected cost distribution (orange) will not be a one time thing. The development team will have to continuously fine-tune based on Agent and Multi-agent System design approach, specific prompts, and tools use.
Caveats
There are several caveats to this analysis.
- This is not the final cost – this is just the cost arising from the use of LLMs in agents and multi-agent applications where we have loops and workflows.
- This cost will contribute to the larger total cost of ownership which will include operational setup to monitor these agents, compute, storage, and not to mention cost of maintaining and upgrading the agents as models change, new intents are required and failure modes are discovered.
- The model output is quite sensitive to what is put in. That is why we get a distribution as part of the estimate. Individual numbers will never give us the true story.
Code
Code for the Agent Cost Model can be found below… feel free to play with it and fine tune it.