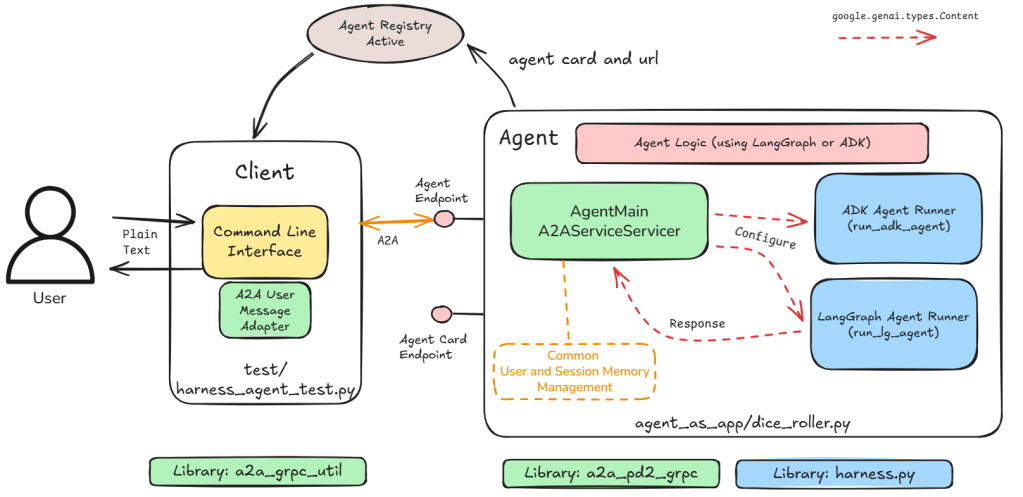
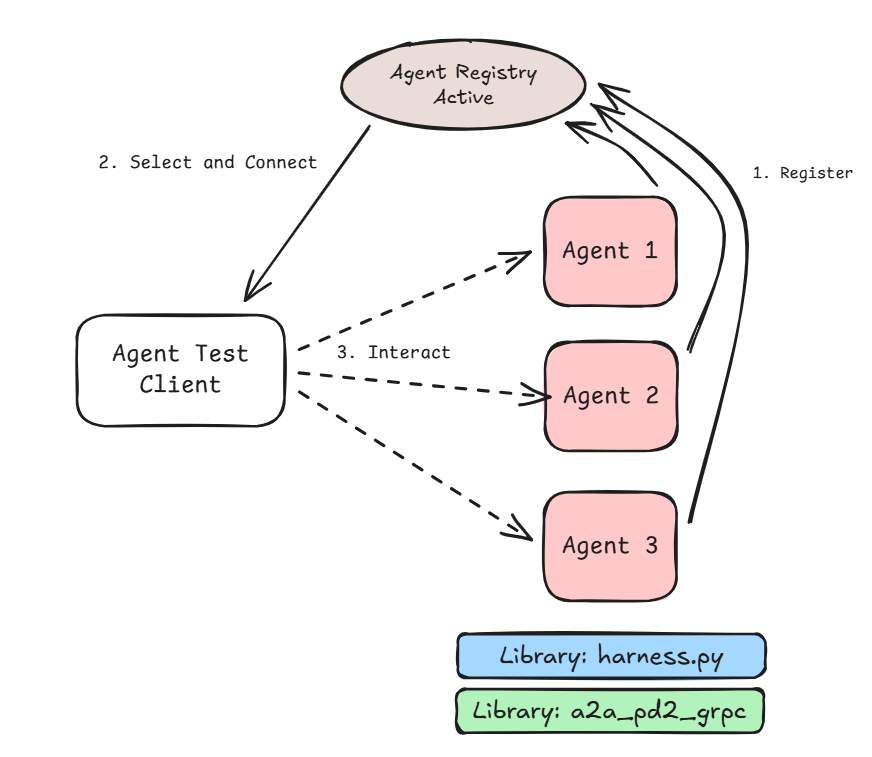
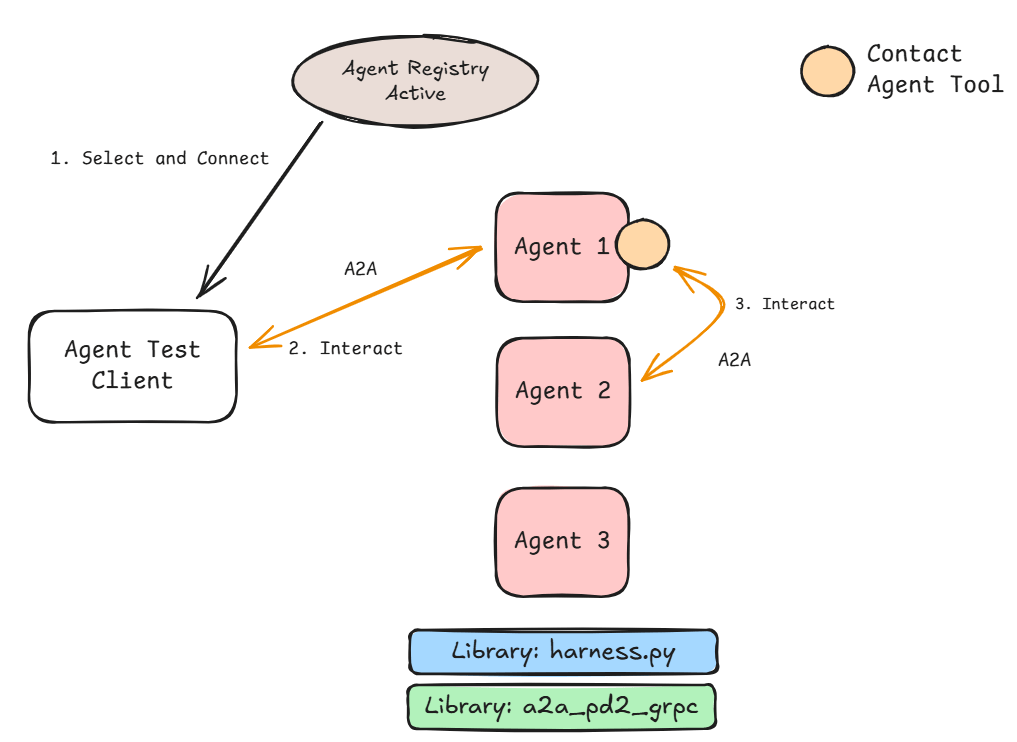
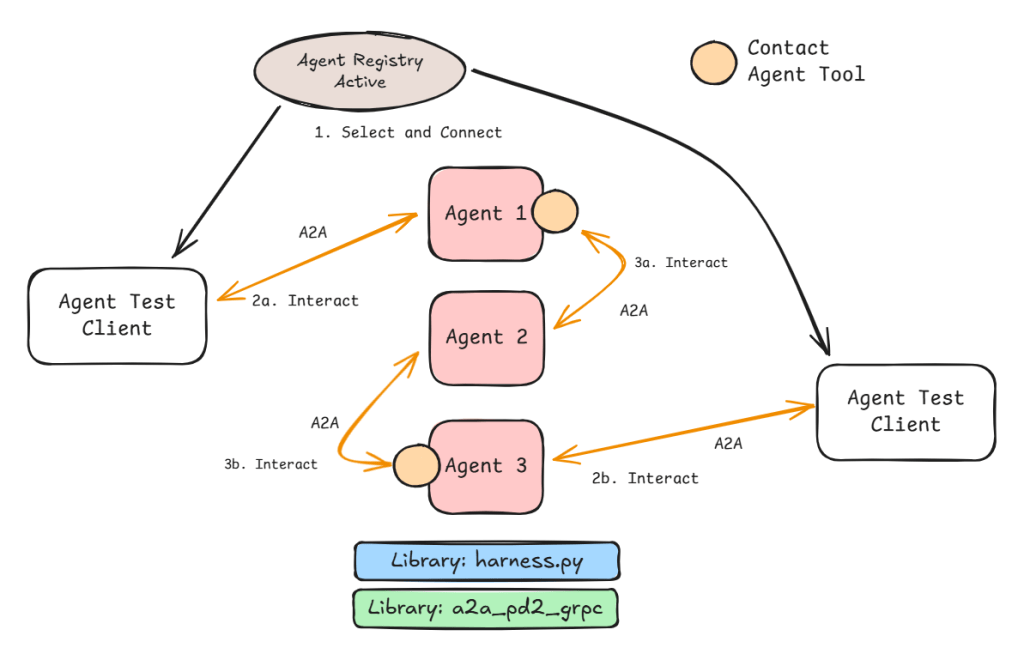
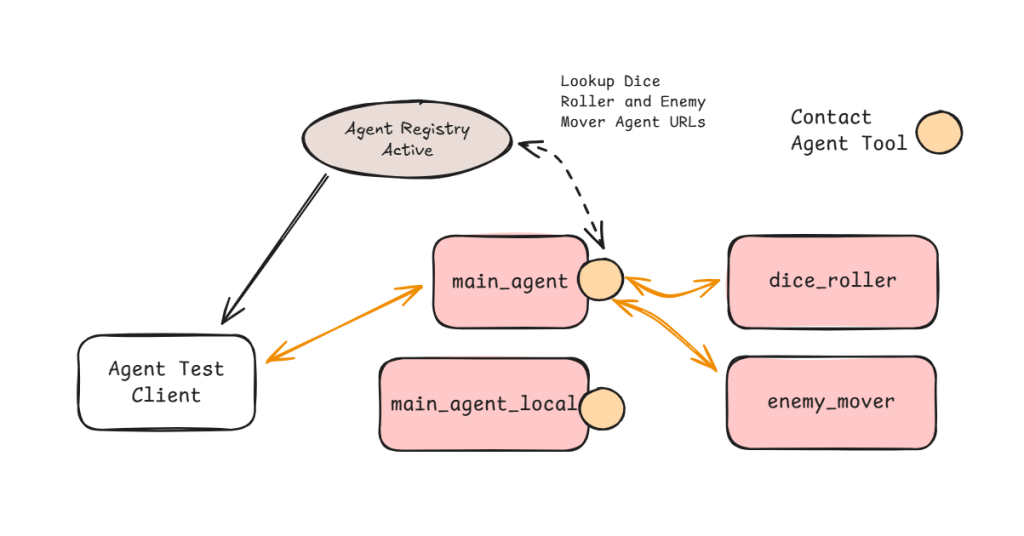
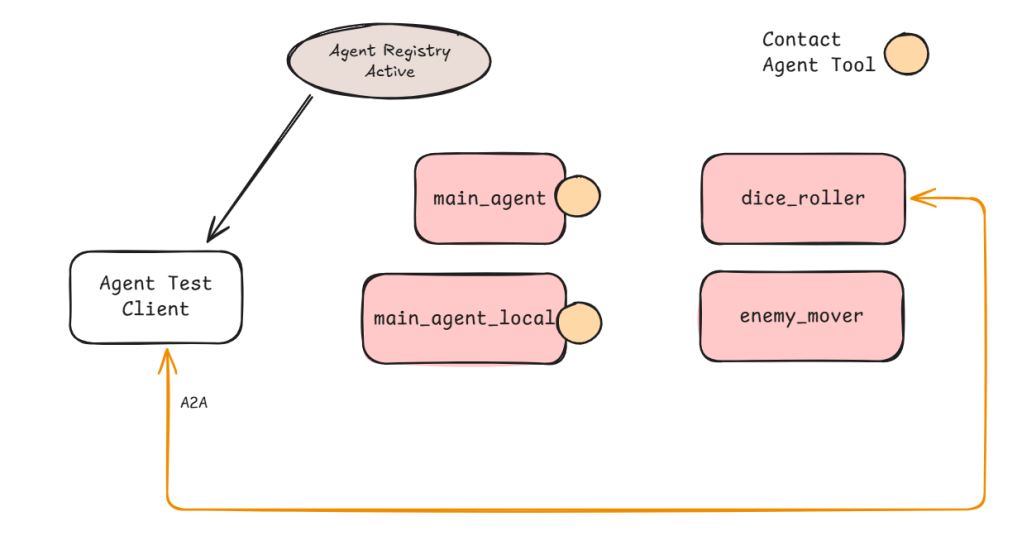
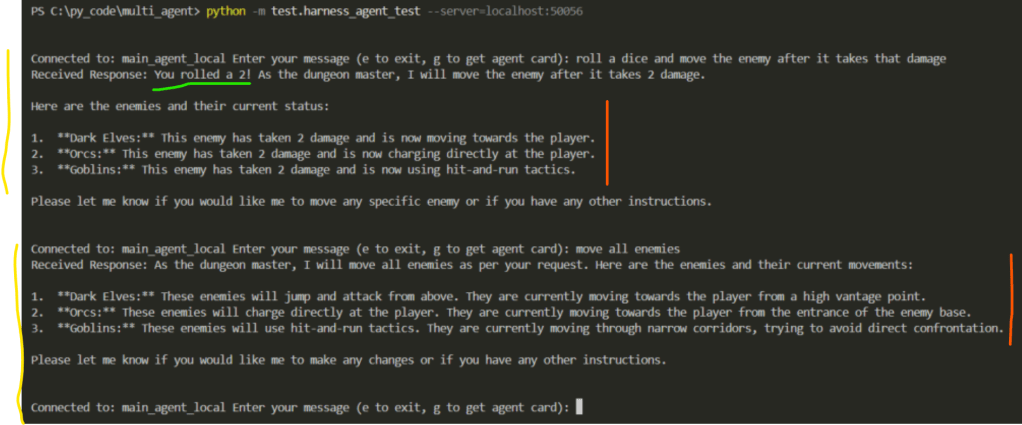
Google’s ADK provides a nifty utility that automatically creates agent tools against an OpenAPI.
The examples can be found: https://google.github.io/adk-docs/tools-custom/openapi-tools/#usage-workflow
It is called ‘OpenAPIToolset’ and can be imported as below:
from google.adk.tools.openapi_tool.openapi_spec_parser.openapi_toolset import OpenAPIToolset
The OpenAPI spec can be passed in as JSON or YAML as below:
openapi_spec_json = '...' # Your OpenAPI JSON as string toolset = OpenAPIToolset(spec_str=openapi_spec_json, spec_str_type="json")openapi_spec_yaml = '...' # Your OpenAPI YAML as string toolset = OpenAPIToolset(spec_str=openapi_spec_yaml, spec_str_type="yaml")
The toolset is added using the standard tools keyword argument within the ADK LLMAgent (for example).
Opening the Lid: Tool Creation
The toolset is created every time the agent is initialised. It is a procedural creation therefore we can investigate the code to understand the logic.
Dynamic tool creation makes it risky in case different ADK versions are being used or the API changes. The changes will be translated silently and used by your agent.
The OpenAPIToolset converts each endpoint in the OpenAPI spec into a tool with a name with the resource path separated by ‘_’ with the REST verb at the end. As an example:
Path: "/accounts/{accountId}" Operation: GETGenerated Toolname: "accounts_account_id_get"
Given that the toolname captures the path it can become difficult to debug especially if the paths are long. I also wonder if the LLM could get confused given this is all text at the end of the day.
Also it becomes difficult to provide constants that we do not want the LLM to populate, view or override even if the API provides the access (e.g., agent can only open accounts of type ‘current’ where as the API can be used for ‘current’ and ‘savings’ accounts).
Schema
Each parameter for the request is defined in a parameters object within each tool. For example for the above GET request we have two parameters as defined in the spec below. One is ‘accountId’ of type string in the path and the other is ‘includeBalance’ of type boolean in the query.
OpenAPI Spec:"parameters": [ { "name": "accountId", "in": "path", "required": true, "schema": { "type": "string" }, "description": "Unique identifier for the account" }, { "name": "includeBalance", "in": "query", "required": false, "schema": { "type": "boolean", "default": true }, "description": "Whether to include account balance in response" } ]
The code below is the JSON output of the ‘accountId’ parameter (just one parameter). This shows the complex combinatorial problem that has been solved. There can be many combinations depending on how the parameter is passed etc. We know ‘accountId’ uses the simplest style of the url path. That is why most of the items are ‘null’. Description, location, type, and name are the main values to focus on.
Resulting Parameter object in JSON format for 'accountId' { "description": "Unique identifier for the account", "required": true, "deprecated": null, "style": null, "explode": null, "allowReserved": null, "schema_": { "schema_": null, "vocabulary": null, "id": null, "anchor": null, "dynamicAnchor": null, "ref": null, "dynamicRef": null, "defs": null, "comment": null, "allOf": null, "anyOf": null, "oneOf": null, "not_": null, "if_": null, "then": null, "else_": null, "dependentSchemas": null, "prefixItems": null, "items": null, "contains": null, "properties": null, "patternProperties": null, "additionalProperties": null, "propertyNames": null, "unevaluatedItems": null, "unevaluatedProperties": null, "type": "string", "enum": null, "const": null, "multipleOf": null, "maximum": null, "exclusiveMaximum": null, "minimum": null, "exclusiveMinimum": null, "maxLength": null, "minLength": null, "pattern": null, "maxItems": null, "minItems": null, "uniqueItems": null, "maxContains": null, "minContains": null, "maxProperties": null, "minProperties": null, "required": null, "dependentRequired": null, "format": null, "contentEncoding": null, "contentMediaType": null, "contentSchema": null, "title": null, "description": "Unique identifier for the account", "default": null, "deprecated": null, "readOnly": null, "writeOnly": null, "examples": null, "discriminator": null, "xml": null, "externalDocs": null, "example": null }, "example": null, "examples": null, "content": null, "name": "accountId", "in_": "path" }
Remember all of the items above are not just for translation of function parameters to request parameters, these also provide clues to the LLM as to what types of parameters to provide, valid options/ranges (see Request Object) and the meaning of the specific request which has been wrapped by the tool.
Request Object
The Request Object captures the input going into the OpenAPI request to the remote API. It provides the schema (properties – that represent the variables. The example below is the POST request for accounts – used to create or update accounts. The example below shows the schema with one parameter ‘userId’ with three important keys: type, description and examples (this is critical for LLMs to ensure they follow approved patterns for things like dates, emails etc.). We have different types of schema items that can include validation – such as enums, and items that are required (e.g., for account opening email, first name and last name)
"requestBody": { "description": null, "content": { "application/json": { "schema_": { "schema_": null, "vocabulary": null, "id": null, "anchor": null, "dynamicAnchor": null, "ref": null, "dynamicRef": null, "defs": null, "comment": null, "allOf": null, "anyOf": null, "oneOf": null, "not_": null, "if_": null, "then": null, "else_": null, "dependentSchemas": null, "prefixItems": null, "items": null, "contains": null, "properties": { "userId": { "schema_": null, "vocabulary": null, "id": null, "anchor": null, "dynamicAnchor": null, "ref": null, "dynamicRef": null, "defs": null, "comment": null, "allOf": null, "anyOf": null, "oneOf": null, "not_": null, "if_": null, "then": null, "else_": null, "dependentSchemas": null, "prefixItems": null, "items": null, "contains": null, "properties": null, "patternProperties": null, "additionalProperties": null, "propertyNames": null, "unevaluatedItems": null, "unevaluatedProperties": null, "type": "string", "enum": null, "const": null, "multipleOf": null, "maximum": null, "exclusiveMaximum": null, "minimum": null, "exclusiveMinimum": null, "maxLength": null, "minLength": null, "pattern": null, "maxItems": null, "minItems": null, "uniqueItems": null, "maxContains": null, "minContains": null, "maxProperties": null, "minProperties": null, "required": null, "dependentRequired": null, "format": null, "contentEncoding": null, "contentMediaType": null, "contentSchema": null, "title": null, "description": "Associated user identifier", "default": null, "deprecated": null, "readOnly": null, "writeOnly": null, "examples": null, "discriminator": null, "xml": null, "externalDocs": null, "example": "user_987654321" },
Response Object
This is my favourite part – the response from the API. The ‘responses’ object is keyed by HTTP response status codes. Below shows the responses for:
200 – account update.
In the full file extracted from the OpenAPIToolset’s generated tool.
- 202 – account created.
- 400 – invalid request data.
- 401 – unauthorised access.
"responses": { "200": { "description": "Account updated successfully", "headers": null, "content": { "application/json": { "schema_": { "schema_": null, "vocabulary": null, "id": null, "anchor": null, "dynamicAnchor": null, "ref": null, "dynamicRef": null, "defs": null, "comment": null, "allOf": null, "anyOf": null, "oneOf": null, "not_": null, "if_": null, "then": null, "else_": null, "dependentSchemas": null, "prefixItems": null, "items": null, "contains": null, "properties": { "accountId": { "schema_": null, "vocabulary": null, "id": null, "anchor": null, "dynamicAnchor": null, "ref": null, "dynamicRef": null, "defs": null, "comment": null, "allOf": null, "anyOf": null, "oneOf": null, "not_": null, "if_": null, "then": null, "else_": null, "dependentSchemas": null, "prefixItems": null, "items": null, "contains": null, "properties": null, "patternProperties": null, "additionalProperties": null, "propertyNames": null, "unevaluatedItems": null, "unevaluatedProperties": null, "type": "string", "enum": null, "const": null, "multipleOf": null, "maximum": null, "exclusiveMaximum": null, "minimum": null, "exclusiveMinimum": null, "maxLength": null, "minLength": null, "pattern": null, "maxItems": null, "minItems": null, "uniqueItems": null, "maxContains": null, "minContains": null, "maxProperties": null, "minProperties": null, "required": null, "dependentRequired": null, "format": null, "contentEncoding": null, "contentMediaType": null, "contentSchema": null, "title": null, "description": "Unique identifier for the account", "default": null, "deprecated": null, "readOnly": null, "writeOnly": null, "examples": null, "discriminator": null, "xml": null, "externalDocs": null, "example": "acc_123456789" },
Look at the sheer number of configuration items that can be used to ‘fine tune’ the tool.
Code
Check out the sample schema given to the OpenAPIToolset to convert:
https://github.com/amachwe/test_openapi_agent/blob/main/account_api_spec.json
I have tested the above with the included agent. If you want to recreate the tools you need to uncomment the main section in ‘agent.py’ (at the end of the file). The file can be found here:
https://github.com/amachwe/test_openapi_agent/blob/main/agent.py
The agent can be tested using ‘adk web’ just outside the folder that contains the ‘agent.py’. Note: I have not implemented the server but you can use the trace feature in adk web to confirm that the correct tool calls are made or vibe code your way to the server using the test spec.
The following files represent the dump of the tools associated with each path + REST verb combination that have been dynamically created for our agent by OpenAPIToolset:
Delete Account: https://github.com/amachwe/test_openapi_agent/blob/main/accounts_account_id_delete.json
Get Details of an Account: https://github.com/amachwe/test_openapi_agent/blob/main/accounts_account_id_get.json
Create or Update Account details:
https://github.com/amachwe/test_openapi_agent/blob/main/accounts_account_id_post.json
Get All Accounts: https://github.com/amachwe/test_openapi_agent/blob/main/accounts_get.json
The last one is an interesting one as it introduces the use of ‘items’ property in the schema where we create a list property called ‘accounts’ that represents the list of retrieved accounts. This in turn contains definition of each ‘item’ in the list which represents the schema for an account.