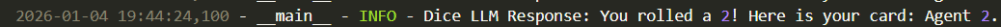Think of a coffee machine. The automated kind with water, milk, coffee and chocolate inside. That is lazy evaluation.
In such a coffee machine we have a ‘store’ of water, milk, coffee and other ingredients but these are not mixed and processed to produce a specific type of coffee till the request comes in. This is Lazy Evaluation.
What the machine does not do is keep the milk froth ready, keep the water boiling etc. this would be Greedy Evaluation.
So what…
Lazy evaluation can help save time, cost, and resources. We do not need to use up memory to store intermediate results as the whole processing becomes one large task execution graph. This is applicable for any area where there are a set of tasks that need to be combined based on incoming request.
From the coffee shop, to amazon warehouses, to your software program.
Developing agents and multi-agent systems seems to be more about a lone-wolf developer standing up a whole fleet of agents (cue your favourite OpenClaw story).
But what if as an organisation you want to have a multi-agent system built with developers working across different teams?
In that scenario, all the agents you need in your multi-agent system (MAS) are not going to show up all at once in perfect sync. For a (hopefully) short time it will appear fragmented before the agents start coming online giving it some shape.
This post is about how you can stub out agents to ensure teams are decoupled.
This post is divided into two sections. The first one describes what a stub can look like and the other how these stubs fit based on specific orchestration scenarios.
This type of stub is just a bridge over the gap. The primary benefit is to ensure you can test any kind of routing and orchestration to this agent (not from it). This also allows you to see the shape of your multi-agent system and ensure you have placeholders to map on-paper architecture to code.
Usage: The name an description are minimum bits of information you need to agree with the team responsible for the agent build. This must be done as a part of the MAS design and agent-to-skill mapping.
Deterministic Stub
We may want to create a deterministic stub for the situation where we know the major scenarios we want to stub for and can create a rule-based decision tree. For example, in case these agents are part of a sequence and are taking in structured input and producing structured output. Such rule-based stubs will then be replaced by a flexible/robust understanding and decisioning system (e.g., LLM, ML-model) in production.
Usage: First decide what scenarios you want to use the stub based on the requirements for the agent. Decide whether you want to test the happy path or the unhappy path or both. The problem to solve then is to create some simple rules that map the input to specific outputs. This will require coordination with the team developing the actual agent and the goals/tasks assigned to the agent. The stub can also be used to support session state update testing (plumbing for the system).
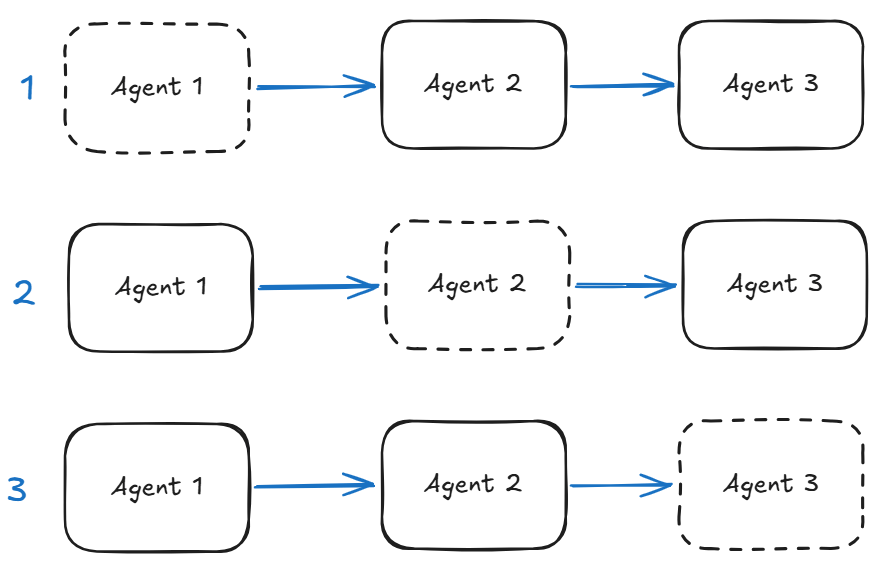
In the figure below if we are missing an agent in a Sequential workflow that we need to stub then we have three scenarios.
Agent missing at the start of the flow – the stub will need to create output that drives the rest of the flow. This can be done based on specific flow scenarios (e.g., customer details passed in a structured format). This is a critical stub as it can either protect the downstream agents or push them off track.
State: the stub can be used to initialise session state.
Agent missing in the middle of the flow – the stub will need to deal with input from the upstream agent as well as produce output to continue the scenario. We need to localise the behaviour of the stubbed agent.
State: the stub can be used to propagate state changes downstream aligning with the specific use-case.
Agent missing at the end of the flow – this stub needs to capture the end state of the flow for whatever is waiting at the other end. We have to be careful as these types of stubs can misrepresent the entire flow.
State: the stub can be used to finalise state change at the end of the flow.
Agents in a sequence and stubs represented by dashed line.
Basic variant of the Deterministic Stub is shown below with all the different ‘action’ options:
Just generate some content based on a rule (append ‘Hello world’).
This is when you find it difficult to create code that maps inputs to outputs but still need to stub out at the comprehension behaviour of the agent.
Usage: Ensure you focus on the inputs and outputs while stubbing out the comprehension aspect of the real agent. Be careful you do not add decisioning behaviours to the stub otherwise you will create a system that is tuned to the stub behaviour and may behave differently when the stub is replaced with the real agent.
You are able to relate the input with the output using one of the methods below:
some sort of semantic search (e.g., vector search) where the index gives semantic mapping to the test output to use and ML-model is used to understand the input.
prompt a light-weight LLM to understand the input and map to one of the pre-set outputs without exercising its own decisioning capabilities.
Example
I show an example of how such an ‘intelligent’ stub can be developed using the first approach (semantic search). For this we have used a set of ‘key intents’ aligned with the use-case, an embedding model to simulate the comprehension of the agent and a simple similarity score to surface the intent based on the input.
The stubs shown in this post can be used as sub-agents or within the deterministic workflows supported by ADK (looping, sequential, parallel). In the next post I will attempt to build out the deterministic workflow examples.
Below is the full example for sub-agents.
from typing import AsyncGenerator
from google.adk.agents.llm_agent import LlmAgent
from google.adk.agents import BaseAgent, InvocationContext
from google.adk.models.lite_llm import LiteLlm
from typing_extensions import override
from google.adk.events import Event, EventActions
from google.genai.types import Content, Part
import random
import numpy as np
from sentence_transformers import SentenceTransformer, util
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
MODEL = LiteLlm(model="ollama_chat/qwen3.5:2b")
class StubAgent(BaseAgent):
def __init__(self, name:str, description:str, sub_agents=[]):
super().__init__(name=name, description=description, sub_agents=sub_agents)
@override
async def _run_async_impl(self, ctx: InvocationContext) -> AsyncGenerator[Event, None]:
print("Activating StubAgent with context:", ctx)
logger.info(f"{self.name} received context: {ctx}")
yield Event(turn_complete=True, author=self.name)
class DeterministicStubAgent(BaseAgent):
integration: str = "Stub_Agent_Integration"
def __init__(self, name: str, description: str, sub_agents=[]):
super().__init__(name=name, description=description)
@override
async def _run_async_impl(self, ctx: InvocationContext) -> AsyncGenerator[Event, None]:
# Get the input message from the context
logger.info(f"{self.name} received context: {ctx}")
input_message = ctx.user_content.parts[0].text if ctx.user_content and ctx.user_content.parts else ""
print(f"Received input message: {input_message}")
# Add "Hello world" to the message
modified_message = f"Hello world {input_message}"
print(f"Modified message: {modified_message}")
hop_count = ctx.session.state.get("hop_count", 0)
state_delta = {"hop_count": hop_count + 1
}
invocation_id = f"{hop_count}_{random.randint(1000, 9999)}"
if hop_count>=2 and hop_count<5:
# Transfer to another cheaper agent after 2 hops
action = EventActions(state_delta=state_delta,transfer_to_agent=self.integration)
event = Event( invocation_id=invocation_id, author=self.name, content = Content(role="assistant", parts=[Part(function_call={"name": "transfer_to_agent", "args": {"agent_name": self.integration}})]), actions=action)
elif hop_count>=5:
print("Turn completed")
action = EventActions(state_delta=state_delta,turn_complete=True)
event = Event( invocation_id=invocation_id, author=self.name, content = Content(role="assistant", parts=[Part(text=modified_message)]), actions=action)
else:
action = EventActions(state_delta=state_delta)
event = Event( author=self.name, content = Content(role="assistant", parts=[Part(text=modified_message)]), actions=action)
yield event
class IntelligentStubAgent(BaseAgent):
model: SentenceTransformer = SentenceTransformer('all-MiniLM-L6-v2')
key_intents: list[str] = ["Integration", "Differentiation", "Algebra", "Geometry", "Trigonometry"]
encoded_intents: list[np.ndarray] = []
def __init__(self, name: str, description: str, sub_agents=[]):
super().__init__(name=name, description=description)
self.encoded_intents = [self.model.encode(intent) for intent in self.key_intents]
@override
async def _run_async_impl(self, ctx: InvocationContext) -> AsyncGenerator[Event, None]:
# Get the input message from the context
logger.info(f"{self.name} received context: {ctx}")
input_message = ctx.user_content.parts[0].text if ctx.user_content and ctx.user_content.parts else ""
print(f"Received input message: {input_message}")
# Add "Hello world" to the message
encode = self.model.encode(input_message) # Just to simulate some processing
similarities = [1 - util.cos_sim(encode, intent) for intent in self.encoded_intents]
best_intent_index = np.argmin(similarities)
best_intent = self.key_intents[best_intent_index]
modified_message = f"Identified intent: {best_intent} for input: {input_message}"
event = build_event( name=self.name, content=f"Detected intent: {modified_message}", state_delta={"identified_intent": best_intent})
yield event
def build_event(name:str, content:str, turn_complete:bool=False, transfer_to_agent:str=None, state_delta:dict={})->Event:
action = EventActions(state_delta=state_delta, transfer_to_agent=transfer_to_agent)
invocation_id = f"{name}-{random.randint(1, 99999)}"
event = Event( invocation_id=invocation_id, author=name, content = Content(role="assistant", parts=[Part(text=content)]), actions=action, turn_complete=turn_complete)
return event
instruction = """
You are an autonomous agent that takes a complex maths problem and breaks it down into smaller steps to solve it.
You have access to a set of agents for each branch of maths.
"""
stub_agent_1 = StubAgent(name="Stub_Agent_Integration", description="Agent that can do Integration problems")
stub_agent_2 = DeterministicStubAgent(name="Stub_Agent_Differentiation", description="Agent that can do Differentiation problems")
stub_agent_3 = IntelligentStubAgent(name="Stub_Agent_Intelligent", description="Agent that can identify the branch of maths")
root_agent = LlmAgent(name="Root_Agent", description="Root agent for handling conversation and classification of problem", instruction=instruction, model=MODEL, sub_agents=[stub_agent_1, stub_agent_2, stub_agent_3])
Output:
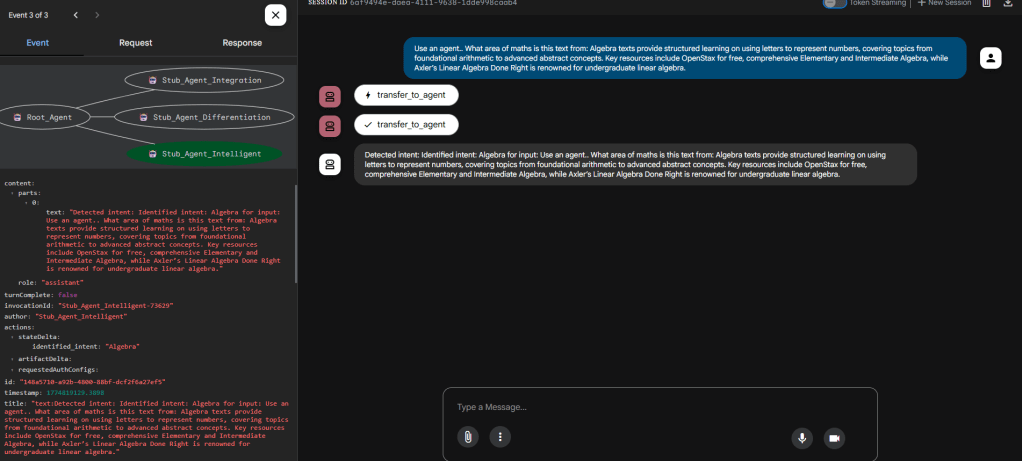
Intelligent Stub in action
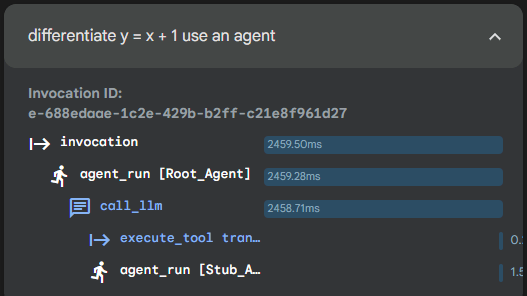
In the above the intent has been correctly identified and now can be used to pull out a specific response from a test list. ADK web tracing shows that the Intelligent stub was called.
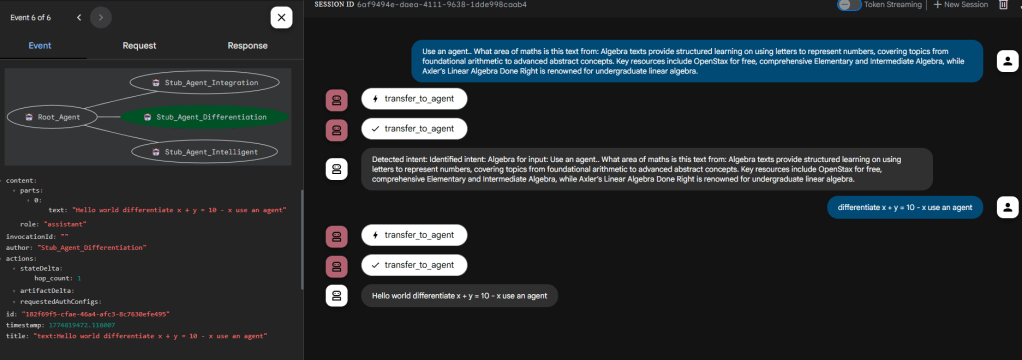
Deterministic Stub in action
In the above the flow has been directed to the deterministic agent which as appended ‘Hello world’ to the output correctly. Confirmed using the ADK web tracing.
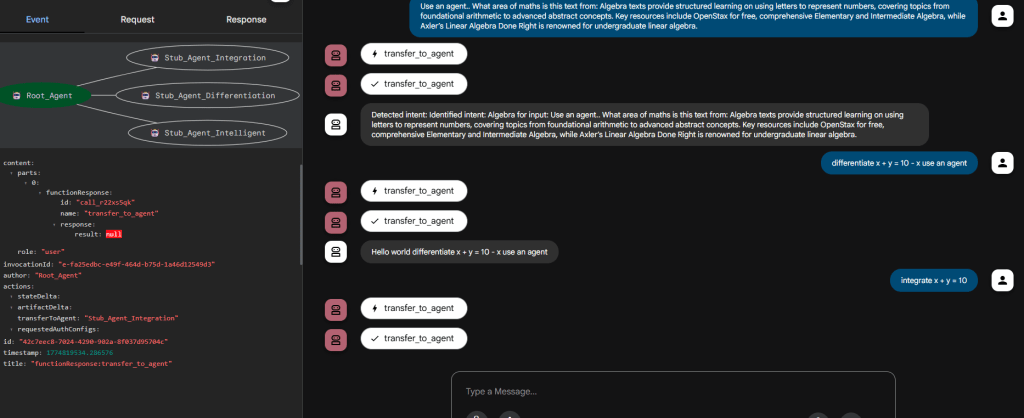
Dumb Stub (not) in action
In the above we don’t see anything interesting (given this is a Dumb stub) except that the Root Agent correctly routed to it based on the description provided to the dumb stub. This can be extremely useful when you have a large set of sub-agents and not all of them are available to test the routing result of your root agent instructions.
Disclaimer:This post will refer to examples and scenarios that I have personally tested using ADK web. I have also extended my testing to GCP Agent Engine where possible. In practice ADK web and Agent Engine are different platforms so prepare to be surprised if something works in ADK web but not with Agent Engine. I will attempt to highlight where I have come across such issues. Agent Engine code at the bottom of the post.
The recent updates on ADK 2.0 (here), which is in Alpha release currently, point toward the framework offering greater control for orchestration through the introduction of a graph construct. This also ensures it attempts to fight back against the likes of LangGraph.
Why Customise?
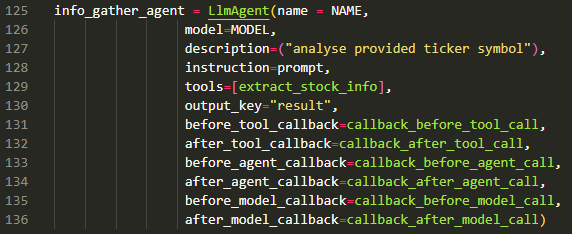
The reason for this post is around the above question. Currently, most examples for ADK solve the orchestration between agents using a composition of one of 5 ‘core’ patterns:
Sub-agent
Agent-as-Tool
Three deterministic workflow patterns (Sequential, Parallel, and Loop).
The deterministic workflow patterns are all based around an ‘Agent’ that is not driven by a LLM. Instead it is driven by code.
To actually implement an agent in ADK the most common starting point is LlmAgent. This is an out-of-the-box implementation of the ReACT agent architecture.
But there are several scenarios that require you to build a custom agent (at least till we have ADK 2.0 out). Some of these are outlined below:
When stubbing out agents.
When you require fine-grained orchestration control (e.g., using ML to decide what happens next based on the output of the previous agent).
When we want to create our own style of agent (e.g., those based on ML-models and deterministic decisioning) and not use LlmAgent.
How to Customise?
The basic outline for a ‘blank’ agent is as follows:
yield# when you are ready to complete execution then yield an Event here.
The key aspects to focus on:
name and description in the initmethod: required to identify your agent and to describe it for upstream agents.
_run_async_impl method: this is where the logic of this custom agent goes.
The Logic of the Agent
The _run_async_impl which has been overridden in the above snippet is an async method. This means it is not a ‘blocking’ method instead it is called from within an event loop.
Insight: ADK by-default executes agents in an async manner even if to the consumer it looks like a synchronous call.
The InvocationContext object is the magic object that contains all the information available for our custom agent to understand the task it is being asked to perform and any additional data/context provided. It also provides information about the current ‘state’ of the interaction including conversational context.
A given context spans one full turn starting with the external input into the multi-agent system (e.g., user’s message) and ends with the final response of the multi-agent system (e.g., response back to the user). The context is therefore made up of multiple agent calls which in turn can be made up of several custom calls, LLM calls, or tool calls.
Given the yield construct we are expected to formulate our agent as a generator of events. Which brings us to the Event construct within ADK.
Insight: An ADK agent, from a programmatic perspective, is nothing but a generator of events that influences what downstream agents see. If no Events are generated by your agent then it is invisible to the other agents in the system.
Event Class
The Event Class is the most important class to understand because this is what allows your agent to surface itself in the event stream that is one Multi-agent system execution turn. If your agent doesn’t yield any Event objects it will be invisible to the other agents just like an employee that never sends an email, types a line of code, or attends a meeting.
So what is an Event?
An Event in ADK is an immutable record representing a specific point in the agent’s execution. It captures user messages, agent replies, requests to use tools (function calls), tool results, state changes, control signals, and errors. [https://google.github.io/adk-docs/events/]
The Event class has two required attributes:
Author: author of the event (e.g., agent name).
Invocation Id: even though the documentation states it as a required, your agent will still work without adding invocation id to events because in the code for the Event class it has a default empty string value. Agent Engine: this is required and must be unique and generated per processing stage.
Other attributes of interest:
content: represented by the Content object which is the ‘output’ of your agent. Content object can represent complex content types such as text, file data, code etc.
partial/turn_complete: boolean values that signal the completeness of the response.
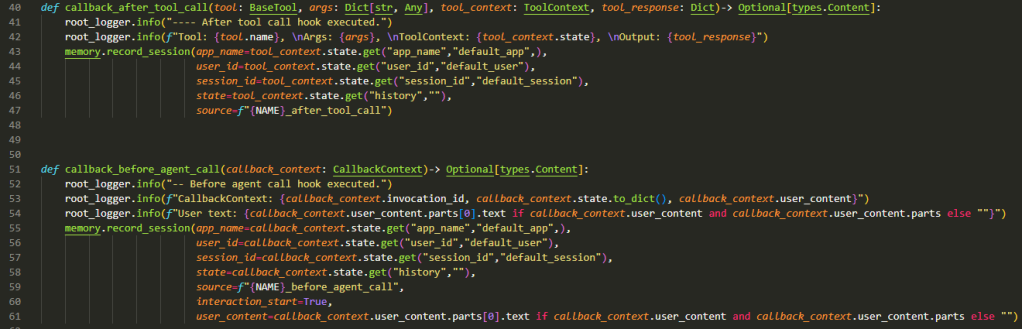
actions: type of EventActions such as:
state_delta/artefact_delta: indicating update of state/artefact with given delta.
transfer_to_agent: indicating action to transfer to the indicated agent.
escalate: indicating an escalation to the indicated agent.
Implementing an Agent that Provides a Static Response
Remember our custom agent can only communicate via Events. In this section let us create a basic agent that generates a response using a deterministic method. In this case it responds by appending ‘Hello world’ to the query provided by the upstream agent.
In the agent above we first access the incoming request via the InvocationContext -> user_content structure and store it in input_message and then create a modified message (append ‘Hello world’).
Then we construct and yield the Event object that contains the deterministic response generated by our custom agent within the content structure.
The above snippet also shows you the starting and endpoints of your custom flow. Start is accessing upstream content that you may want to respond to and the end is the generation of an Event that contains your response/output.
To run the deterministic agent with a LLM-driven agent:
MODEL=LiteLlm(model="ollama_chat/qwen3.5:2b")
instruction="""
You are an autonomous agent that takes a complex maths problem and breaks it down into smaller steps to solve it.
You have access to a set of agents for each branch of maths.
"""
stub_agent_1=StubAgent(name="Stub_Agent_Integration",description="Agent that can do Integration problems")
stub_agent_2=DeterministicStubAgent(name="Stub_Agent_Differentiation",description="Agent that can do Differentiation problems")
root_agent=LlmAgent(name="Root_Agent",description="Root agent for handling conversation and classification of problem",instruction=instruction,model=MODEL,sub_agents=[stub_agent_1,stub_agent_2])
When you run the above as a sub-agent to the root agent this is what the interaction and trace looks like:
Example with EventActions
If you are going to the trouble of creating a custom agent your need will be beyond content generation. You may need to inform other agents about some session level operational information (e.g., cost incurred or agent-hop-count update) or indicate some change in state to the wider application.
The content block is not suitable for this as it is about the content flow. There is a separate ‘state’ structure in the context that exists at the session level which can be used to store temporary state information. Given this is at the session level and not persisted do not use this to store complex bits of information. The session state is not a data store!
@override
async def _run_async_impl(self, ctx: InvocationContext) -> AsyncGenerator[Event, None]:
# Get the input message from the context
logger.info(f"{self.name} received context: {ctx}")
input_message = ctx.user_content.parts[0].text if ctx.user_content and ctx.user_content.parts else ""
print(f"Received input message: {input_message}")
# Add "Hello world" to the message
modified_message = f"Hello world {input_message}"
print(f"Modified message: {modified_message}")
hop_count = ctx.session.state.get("hop_count", 0)
state_delta = {"hop_count": hop_count + 1
}
action = EventActions(state_delta=state_delta)
yield Event( author=self.name, content = Content(role="assistant", parts=[Part(text=modified_message)]), actions=action)
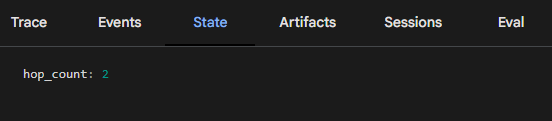
In the snippet above we add a hop_count session state variable to maintain a log of how many times this agent has been called per session. The real world use of this would be to ration the use of ‘expensive’ agents.
If you are using ADK web to test and learn then you can use the ‘State’ tab on the right to explore how this state variable increments every time our custom agent is used in a given session. Below we can see it has been used twice in the session.
In another session it has been used thrice.
The image below shows Agent Engine deployment with some tweaks to the code.
Conclusion
We have gone through some important information around how to build your own custom ADK agent with code snippets. We have spoken about the overall structure and how to construct simple Events.
We then extended this to work with EventActions specifically how we can perform state-updates to share session level information with other agents.
We will build on this knowledge to develop sophisticated custom agents and to carry out common tasks such as stubbing agents for testing multi-agent systems.
Code Tested with Agent Engine
from typing import AsyncGenerator
from google.adk.agents.llm_agent import LlmAgent
from google.adk.agents import BaseAgent, InvocationContext
from google.adk.models.lite_llm import LiteLlm
from typing_extensions import override
from google.adk.events import Event, EventActions
from google.genai.types import Content, Part
import random
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class StubAgent(BaseAgent):
def __init__(self, name:str, description:str, sub_agents=[]):
super().__init__(name=name, description=description, sub_agents=sub_agents)
@override
async def _run_async_impl(self, ctx: InvocationContext) -> AsyncGenerator[Event, None]:
print("Activating StubAgent with context:", ctx)
logger.info(f"{self.name} received context: {ctx}")
yield Event(turn_complete=True, author=self.name)
class DeterministicStubAgent(BaseAgent):
integration: str = "Stub_Agent_Integration"
def __init__(self, name: str, description: str, sub_agents=[]):
super().__init__(name=name, description=description)
@override
async def _run_async_impl(self, ctx: InvocationContext) -> AsyncGenerator[Event, None]:
# Get the input message from the context
logger.info(f"{self.name} received context: {ctx}")
input_message = ctx.user_content.parts[0].text if ctx.user_content and ctx.user_content.parts else ""
print(f"Received input message: {input_message}")
# Add "Hello world" to the message
modified_message = f"Hello world {input_message}"
print(f"Modified message: {modified_message}")
hop_count = ctx.session.state.get("hop_count", 0)
state_delta = {"hop_count": hop_count + 1
}
invocation_id = f"{hop_count}_{random.randint(1000, 9999)}"
if hop_count>=2 and hop_count<5:
# Transfer to another cheaper agent after 2 hops
action = EventActions(state_delta=state_delta,transfer_to_agent=self.integration)
event = Event( invocation_id=invocation_id, author=self.name, content = Content(role="assistant", parts=[Part(function_call={"name": "transfer_to_agent", "args": {"agent_name": self.integration}})]), actions=action)
elif hop_count>=5:
print("Turn completed")
action = EventActions(state_delta=state_delta,turn_complete=True)
event = Event( invocation_id=invocation_id, author=self.name, content = Content(role="assistant", parts=[Part(text=modified_message)]), actions=action)
else:
action = EventActions(state_delta=state_delta)
event = Event( invocation_id=invocation_id, author=self.name, content = Content(role="assistant", parts=[Part(text=modified_message)]), actions=action)
yield event
MODEL = LiteLlm(model="ollama_chat/qwen3.5:2b")
#Note: used Gemini Flash 2.5 when testing with Agent Engine.
instruction = """
You are an autonomous agent that takes a complex maths problem and breaks it down into smaller steps to solve it.
You have access to a set of agents for each branch of maths.
"""
stub_agent_1 = StubAgent(name="Stub_Agent_Integration", description="Agent that can do Integration problems")
stub_agent_2 = DeterministicStubAgent(name="Stub_Agent_Differentiation", description="Agent that can do Differentiation problems")
root_agent = LlmAgent(name="Root_Agent", description="Root agent for handling conversation and classification of problem", instruction=instruction, model=MODEL, sub_agents=[stub_agent_1, stub_agent_2])
The Retrieval part of RAG requires topic specific data to be retrieved from a knowledge store based on the user’s query.
More focussed the retrieval better grounded will be the generation.
Hidden Complexity of Using Vectors
In Vectorised RAG the retrieval part uses a vector database to store chunks of knowledge and a vector search query to retrieve relevant chunks for the model or agent.
The part of using a vector database is where the hidden complexity lies and this is best explained with a story.
When I started my Masters in 2002 we had a module called Research Methods. I was not aware of any of the core concepts and found the lectures difficult to follow. Search engines were not as powerful or AI-enabled as today. One had to expand ones vocabulary with appropriate technical and domain specific terms to retrieve knowledge to then discover related concepts. Keep doing this rinse and repeat till you map out the topic.
The above story describes how I created a mental index of this new topic ‘Research Methods’ and used that to ground my coursework.
For vectorised RAG we depend on what are known as embedding models to convert text containing knowledge into a vector which is then stored in a vector database. The hope is that the model understands the concepts within that topic and relationships between them. This is implemented, during model training, by exposing the model to real text so that it can learn the statistical patterns within the training text.
Retrieval uses the same embedding model to create the query vector from user’s query text to find ‘related’ knowledge from the vector database.
Now we come to the critical part:
Jut by observing statistical patterns with the training text I can build out a concept space. But there is no way to guarantee that I am a master of that concept space. We humans cannot squash all the concepts into our brains (e.g., an aerospace engineer will have concepts and relationships in their head that a marine engineer may not have even though there will be a high degree of overlap in the concept space).
It is highly unlikely that a relatively small model can contain all the concepts at a level of detail to be useful. Therefore, the vectorisation of different documents may be less or more effective based on how deeply the embedding model was trained on that topic.
For example, if the embedding model was trained without knowledge of Charles Dickens or his works then from a vector creation point of view ‘Bleak House’ will be closer to ‘sad house’ than ‘Charles Dickens’. In fact the concept of Charles Dickens may not be in the embedding model at all and therefore the vectors produced may be based on plain English concept of the word.
Another famous example is given the query ‘apple’ – which of the words in the list should the resulting vector be closest to: [‘orange’, ‘iphone’]. Depending on how the embedding model used to vectorise the query and the words in the list we may see different results.
Impact of training bias: if the model has been trained on knowledge about Apple products like the iPhone then we expect the query to be close to ‘iphone’. If the model has been trained on basic English language then the query may appear closer to ‘orange’. Furthermore, ‘iphone’ and ‘orange’ must be far away from each other unless the model knows about the new ‘orange iPhone’.
Just like my Research Methods example above how you build out a concept map of a topic depends on what sources you have included in your learning.
This is the hidden complexity of vectorisation as an approach. You are completely dependent on the embedding model to help map out the topic space and then retrieve specific concepts.
General purpose embedding models will not capture domain or topic specific concepts.
That is what links the embedding model to the use-case. That is why for medical AI applications you get specialised Medical embedding models (like MedEmbed-small-v0.1).
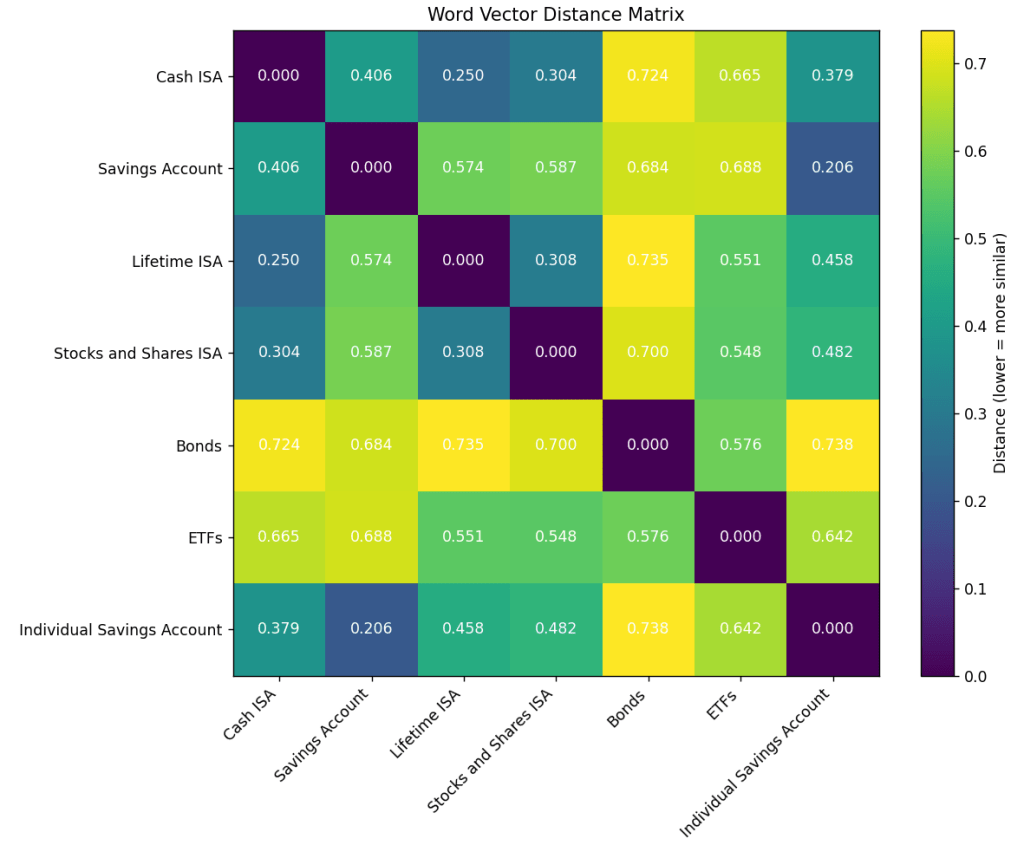
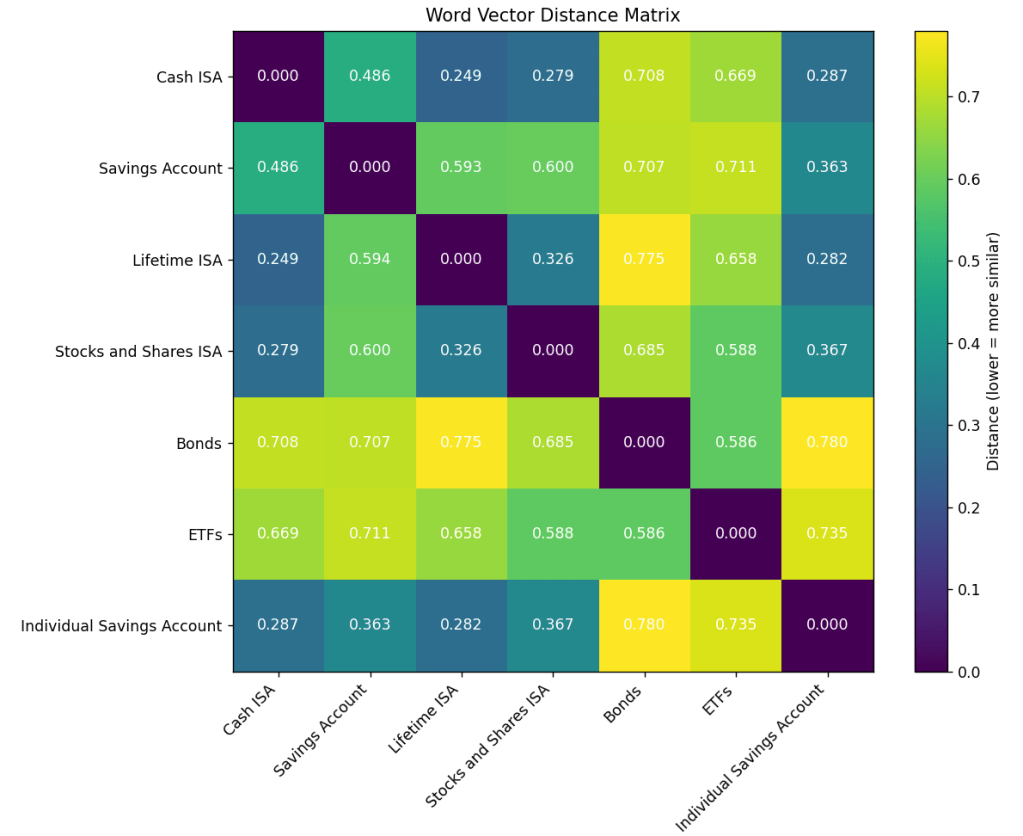
These embedding models have a time-horizon so if a concept did not exist when these were trained, they would not know about it or how to relate it to other concepts. See example of differences in concept resolution below using OpenAI’s ‘text-embedding-3-small’ (Figure 1a) and ‘text-embedding-3-large’ (Figure 1b). Clearly the ‘large’ model has an accurate model of the Savings Account space for UK.
Figure 1a: Note the significant difference for Individual Savings Account against ISAs and the general term Savings Account. All the ISAs are Individual Savings Accounts which are also Savings Accounts.Figure 1b: Note the confusion is not seen in the ‘large’ embedding model as all ISAs and the generic term Savings Account are now quite close to Individual Savings Account.
Embedding models cannot explicitly be given context for a comparison.
Another important point from Figure 1a and 1b above is that these distance measures are fixed. We cannot provide context to the embedding model. For example if the context is tax regulation then the similarity score will be very different. As it would be if the context was risk vs reward.
Think of the context as taking the existing high-dimensional vector space in which all these concepts sit and transforming it to bring certain concepts closer and teasing others apart.
Now a question for you: Have you gone through an embedding mode evaluation for your use-case or just picked a default Open AI or Google embedding model and run with that?
All this without even discussing the many variants of how vector results are evaluated and the different styles of vector creation pipelines and the impact of design choices (e.g., chunking strategy).
Enter PageIndex
PageIndex attempts to the burdened developer from all this embedding model selection, tuning vectorisation pipelines, thinking about chunking strategies and spinning up new bits of software like vector databases.
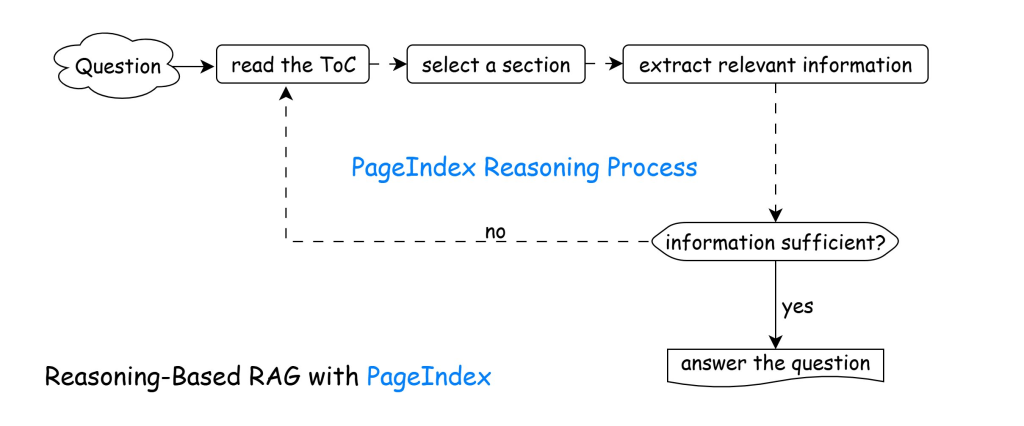
It is based on the concept that let the LLM figure out what is in a document by drawing a table of contents as a light weight index tree called a PageIndex. Then use this content index to identify and extract the relevant sections/concepts from the doc and use those for generating the response in a ‘reasoning loop’ (see Figure 2).
Here you are not spinning up a vector db or bouncing between vectors and plain text at the mercy of the embedding model being used. Everything stays plain text and the SMEs can go and evaluate the PageIndex created, tweak it if needed or even create multiple versions for different use-cases.
"title": "Domestic and International Cooperation and Coordination",
"start_index": 28,
"end_index": 31,
"summary": "In 2023, the Federal Reserve collaborated ..."
}
]
}
The snippet above shows an example of a PageIndex.
Note that the index can be at any level: document, pages, paragraphs etc. and contains metadata to provide additional richness and flexibility to this process (e.g., no need to commit to a chunking strategy).
The way I like to think of PageIndex RAG vs Vectorised RAG is:
PageIndex you are using the notes on a topic prepared by your teacher.
Vectorised you are using the notes on a topic prepared by your friend based on what the teacher taught in the classroom.
Now this method has its own trade-offs which are critical to understand before we jump on this based on LinkedIn hype.
Firstly, it depends on ‘agentic’ style of generation which means multiple loops / LLM calls as compared to a single lightweight embedding model call. Cost implications can be massive especially when you need to re-index.
Secondly, still dependency on some kind of AI-model. We have expanded the concept space by moving from say a 50m to 8b parameter embedding model to a LLM with greater than 20b parameters, mixture of experts, reasoning mode and many other tweaks. We can provide context to build out different indexes via the page index build prompt. That said we will still be bothered by training bias where different models may produce different indexes.
Thirdly, reindexing becomes unpredictable. Earlier you could train lots of small embedding models based on the topic landscape of your organisation and domain. You could store them as your own assets. Now you are dependent on the major model providers like OpenAI, Anthropic, and Google. Let us say you built out your page index based on v1 of the documents of interest using Gemini Flash 2.0. Six months later some documents are updated to v2 now we need to rebuild the page index. But now Gemini Flash 2.0 has been deprecated so you are forced to move to Gemini Flash 2.5. Here the good thing about the Page Index concept is that you can provide the existing version (based on v1 documents) and the v2 documents and instruct the model to update rather than rebuild from scratch. Again this is increasing our dependence on the model thereby requiring SME validation of the Page Index at each stage.
Fourth, Page Index as a chain of steps. Vector index is a one step process. Page Index makes it an agentic loop where the depth of retrieval is dynamic. This can increase latency and make the process less auditable and repeatable. At the same time it can also make the retrieval process tune-able for different topic areas – where a complex query can be supported by additional retrieval loops where as simple queries can be one-shot. Vector retrieval is by default one-shot.
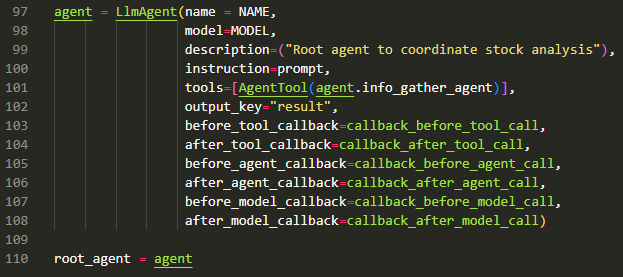
The toolset is added using the standard tools keyword argument within the ADK LLMAgent (for example).
Opening the Lid: Tool Creation
The toolset is created every time the agent is initialised. It is a procedural creation therefore we can investigate the code to understand the logic.
Dynamic tool creation makes it risky in case different ADK versions are being used or the API changes. The changes will be translated silently and used by your agent.
The OpenAPIToolset converts each endpoint in the OpenAPI spec into a tool with a name with the resource path separated by ‘_’ with the REST verb at the end. As an example:
Path: "/accounts/{accountId}" Operation: GET
Generated Toolname: "accounts_account_id_get"
Given that the toolname captures the path it can become difficult to debug especially if the paths are long. I also wonder if the LLM could get confused given this is all text at the end of the day.
Also it becomes difficult to provide constants that we do not want the LLM to populate, view or override even if the API provides the access (e.g., agent can only open accounts of type ‘current’ where as the API can be used for ‘current’ and ‘savings’ accounts).
Schema
Each parameter for the request is defined in a parameters object within each tool. For example for the above GET request we have two parameters as defined in the spec below. One is ‘accountId’ of type string in the path and the other is ‘includeBalance’ of type boolean in the query.
OpenAPI Spec:
"parameters":[
{
"name":"accountId",
"in":"path",
"required":true,
"schema":{
"type":"string"
},
"description":"Unique identifier for the account"
},
{
"name":"includeBalance",
"in":"query",
"required":false,
"schema":{
"type":"boolean",
"default":true
},
"description":"Whether to include account balance in response"
}
]
The code below is the JSON output of the ‘accountId’ parameter (just one parameter). This shows the complex combinatorial problem that has been solved. There can be many combinations depending on how the parameter is passed etc. We know ‘accountId’ uses the simplest style of the url path. That is why most of the items are ‘null’. Description, location, type, and name are the main values to focus on.
Resulting Parameter object in JSON format for 'accountId'
{
"description":"Unique identifier for the account",
"required":true,
"deprecated":null,
"style":null,
"explode":null,
"allowReserved":null,
"schema_":{
"schema_":null,
"vocabulary":null,
"id":null,
"anchor":null,
"dynamicAnchor":null,
"ref":null,
"dynamicRef":null,
"defs":null,
"comment":null,
"allOf":null,
"anyOf":null,
"oneOf":null,
"not_":null,
"if_":null,
"then":null,
"else_":null,
"dependentSchemas":null,
"prefixItems":null,
"items":null,
"contains":null,
"properties":null,
"patternProperties":null,
"additionalProperties":null,
"propertyNames":null,
"unevaluatedItems":null,
"unevaluatedProperties":null,
"type":"string",
"enum":null,
"const":null,
"multipleOf":null,
"maximum":null,
"exclusiveMaximum":null,
"minimum":null,
"exclusiveMinimum":null,
"maxLength":null,
"minLength":null,
"pattern":null,
"maxItems":null,
"minItems":null,
"uniqueItems":null,
"maxContains":null,
"minContains":null,
"maxProperties":null,
"minProperties":null,
"required":null,
"dependentRequired":null,
"format":null,
"contentEncoding":null,
"contentMediaType":null,
"contentSchema":null,
"title":null,
"description":"Unique identifier for the account",
"default":null,
"deprecated":null,
"readOnly":null,
"writeOnly":null,
"examples":null,
"discriminator":null,
"xml":null,
"externalDocs":null,
"example":null
},
"example":null,
"examples":null,
"content":null,
"name":"accountId",
"in_":"path"
}
Remember all of the items above are not just for translation of function parameters to request parameters, these also provide clues to the LLM as to what types of parameters to provide, valid options/ranges (see Request Object) and the meaning of the specific request which has been wrapped by the tool.
Request Object
The Request Object captures the input going into the OpenAPI request to the remote API. It provides the schema (properties – that represent the variables. The example below is the POST request for accounts – used to create or update accounts. The example below shows the schema with one parameter ‘userId’ with three important keys: type, description and examples (this is critical for LLMs to ensure they follow approved patterns for things like dates, emails etc.). We have different types of schema items that can include validation – such as enums, and items that are required (e.g., for account opening email, first name and last name)
"requestBody":{
"description":null,
"content":{
"application/json":{
"schema_":{
"schema_":null,
"vocabulary":null,
"id":null,
"anchor":null,
"dynamicAnchor":null,
"ref":null,
"dynamicRef":null,
"defs":null,
"comment":null,
"allOf":null,
"anyOf":null,
"oneOf":null,
"not_":null,
"if_":null,
"then":null,
"else_":null,
"dependentSchemas":null,
"prefixItems":null,
"items":null,
"contains":null,
"properties":{
"userId":{
"schema_":null,
"vocabulary":null,
"id":null,
"anchor":null,
"dynamicAnchor":null,
"ref":null,
"dynamicRef":null,
"defs":null,
"comment":null,
"allOf":null,
"anyOf":null,
"oneOf":null,
"not_":null,
"if_":null,
"then":null,
"else_":null,
"dependentSchemas":null,
"prefixItems":null,
"items":null,
"contains":null,
"properties":null,
"patternProperties":null,
"additionalProperties":null,
"propertyNames":null,
"unevaluatedItems":null,
"unevaluatedProperties":null,
"type":"string",
"enum":null,
"const":null,
"multipleOf":null,
"maximum":null,
"exclusiveMaximum":null,
"minimum":null,
"exclusiveMinimum":null,
"maxLength":null,
"minLength":null,
"pattern":null,
"maxItems":null,
"minItems":null,
"uniqueItems":null,
"maxContains":null,
"minContains":null,
"maxProperties":null,
"minProperties":null,
"required":null,
"dependentRequired":null,
"format":null,
"contentEncoding":null,
"contentMediaType":null,
"contentSchema":null,
"title":null,
"description":"Associated user identifier",
"default":null,
"deprecated":null,
"readOnly":null,
"writeOnly":null,
"examples":null,
"discriminator":null,
"xml":null,
"externalDocs":null,
"example":"user_987654321"
},
Response Object
This is my favourite part – the response from the API. The ‘responses’ object is keyed by HTTP response status codes. Below shows the responses for:
200 – account update.
In the full file extracted from the OpenAPIToolset’s generated tool.
202 – account created.
400 – invalid request data.
401 – unauthorised access.
"responses":{
"200":{
"description":"Account updated successfully",
"headers":null,
"content":{
"application/json":{
"schema_":{
"schema_":null,
"vocabulary":null,
"id":null,
"anchor":null,
"dynamicAnchor":null,
"ref":null,
"dynamicRef":null,
"defs":null,
"comment":null,
"allOf":null,
"anyOf":null,
"oneOf":null,
"not_":null,
"if_":null,
"then":null,
"else_":null,
"dependentSchemas":null,
"prefixItems":null,
"items":null,
"contains":null,
"properties":{
"accountId":{
"schema_":null,
"vocabulary":null,
"id":null,
"anchor":null,
"dynamicAnchor":null,
"ref":null,
"dynamicRef":null,
"defs":null,
"comment":null,
"allOf":null,
"anyOf":null,
"oneOf":null,
"not_":null,
"if_":null,
"then":null,
"else_":null,
"dependentSchemas":null,
"prefixItems":null,
"items":null,
"contains":null,
"properties":null,
"patternProperties":null,
"additionalProperties":null,
"propertyNames":null,
"unevaluatedItems":null,
"unevaluatedProperties":null,
"type":"string",
"enum":null,
"const":null,
"multipleOf":null,
"maximum":null,
"exclusiveMaximum":null,
"minimum":null,
"exclusiveMinimum":null,
"maxLength":null,
"minLength":null,
"pattern":null,
"maxItems":null,
"minItems":null,
"uniqueItems":null,
"maxContains":null,
"minContains":null,
"maxProperties":null,
"minProperties":null,
"required":null,
"dependentRequired":null,
"format":null,
"contentEncoding":null,
"contentMediaType":null,
"contentSchema":null,
"title":null,
"description":"Unique identifier for the account",
"default":null,
"deprecated":null,
"readOnly":null,
"writeOnly":null,
"examples":null,
"discriminator":null,
"xml":null,
"externalDocs":null,
"example":"acc_123456789"
},
Look at the sheer number of configuration items that can be used to ‘fine tune’ the tool.
Code
Check out the sample schema given to the OpenAPIToolset to convert:
I have tested the above with the included agent. If you want to recreate the tools you need to uncomment the main section in ‘agent.py’ (at the end of the file). The file can be found here:
The agent can be tested using ‘adk web’ just outside the folder that contains the ‘agent.py’. Note: I have not implemented the server but you can use the trace feature in adk web to confirm that the correct tool calls are made or vibe code your way to the server using the test spec.
The following files represent the dump of the tools associated with each path + REST verb combination that have been dynamically created for our agent by OpenAPIToolset:
The last one is an interesting one as it introduces the use of ‘items’ property in the schema where we create a list property called ‘accounts’ that represents the list of retrieved accounts. This in turn contains definition of each ‘item’ in the list which represents the schema for an account.
Part One of this post can be found here. TLDR is here.
Upgrading the Multi-Agent System
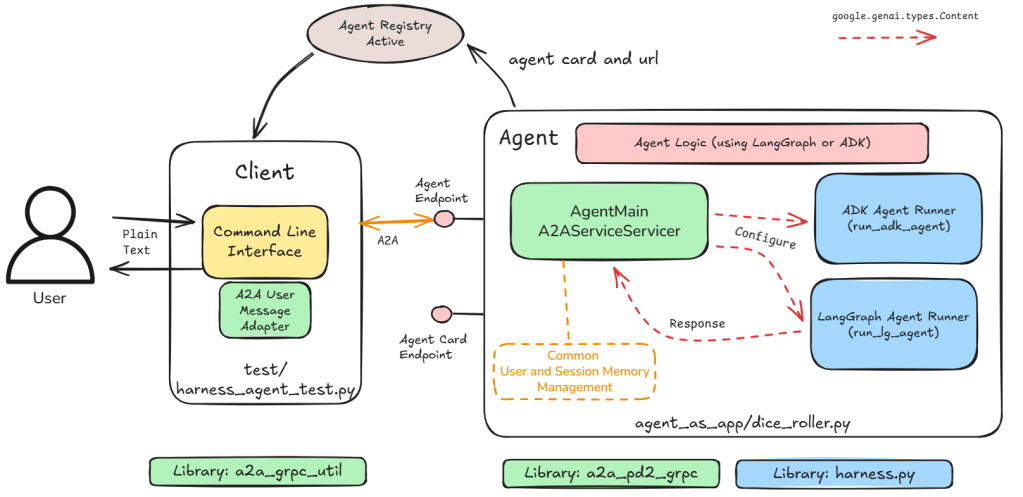
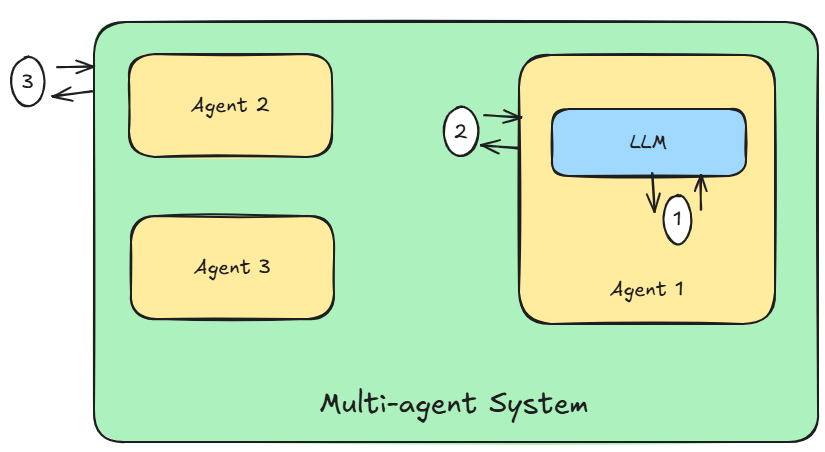
In this part I remove the need for a centralised router and instead package each agent as an individual unit (both a server as well as a client). This is a move from single server multiple agents to single server single agent. Figure 1 shows an example of this.
We use code from Part 1 as libraries to create generic framework that allows us to easily buil agent as servers that support a standard interface (Google’s A2A). The libraries allow us to standardise the loading and running of agents written in LangGraph or ADK.
With this move we need an Active Agent Registry to ensure we register and track every instance of an agent. I implement a policy that blocks the activation of any agent if its registration fails – no orphan agents. The Agent Card provides the skills supported by the registered agent which can be used by other agents to discover its capabilities.
This skills-based approach is critical for dynamic planning and orchestration that gives us the maximum flexibility (while we give up on control and live with a more complex underlay).
Figure 1: Framework to create individual agents using existing libraries.
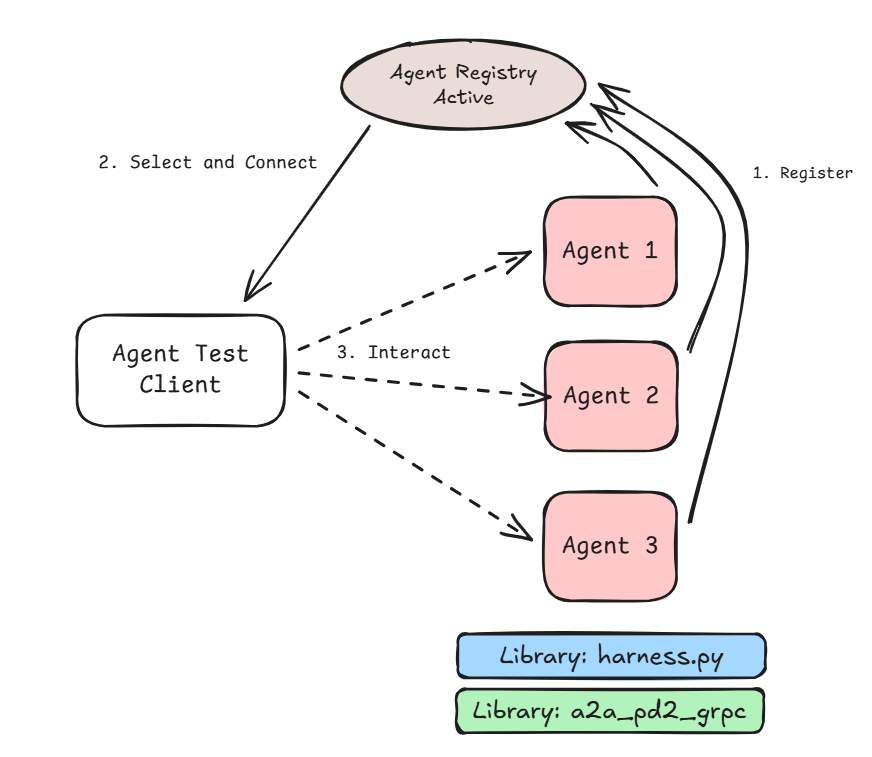
With this change we no longer have a single ‘server’ address that we can default to. Instead our new Harness Agent Test client needs to either dynamically lookup the address of the user provided agent name or have an address provided for the agent we want to interact with.
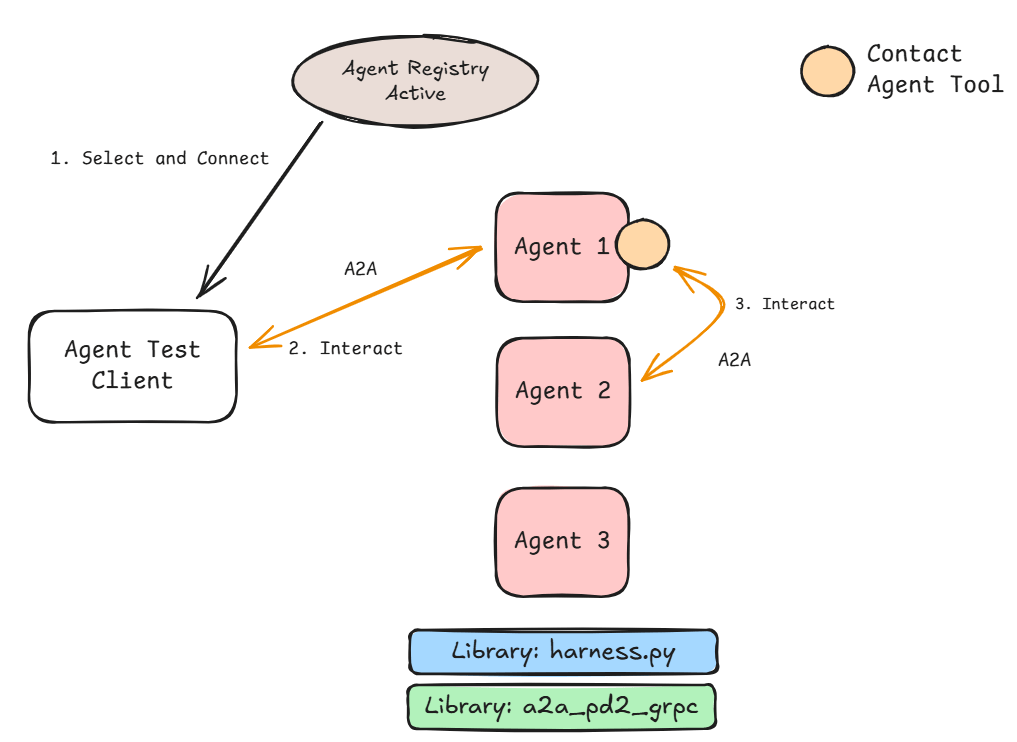
Figure 2: Registration, discovery, and Interaction flow.
Figure 2 above shows the process of discovery and use. The Select and Connect stage can be either:
Manual – where the user looks up the agent name and corresponding URL and passes it in to the Agent Test client.
Automatic – where the user provides the agent name and the URL is looked up at runtime.
Distributed Multi-Agent System
The separation of agents into individual servers allows us to connect them to each other without tight coupling. Each agent can be deployed in its own container. The server creation also ensures high cohesion within the agent.
The Contact Agent tool allows the LLM inside the agent to evaluate the users request, decide skills required, map to the relevant agent name and use that to direct the request. The tool looks up the URL based on the name, initiates a GRPC-based A2A request and returns the answer to the calling agent. Agents that don’t have a Contact Agent tool will not be able to request help from other agents. This can be used as a mechanism to control interaction between agents.
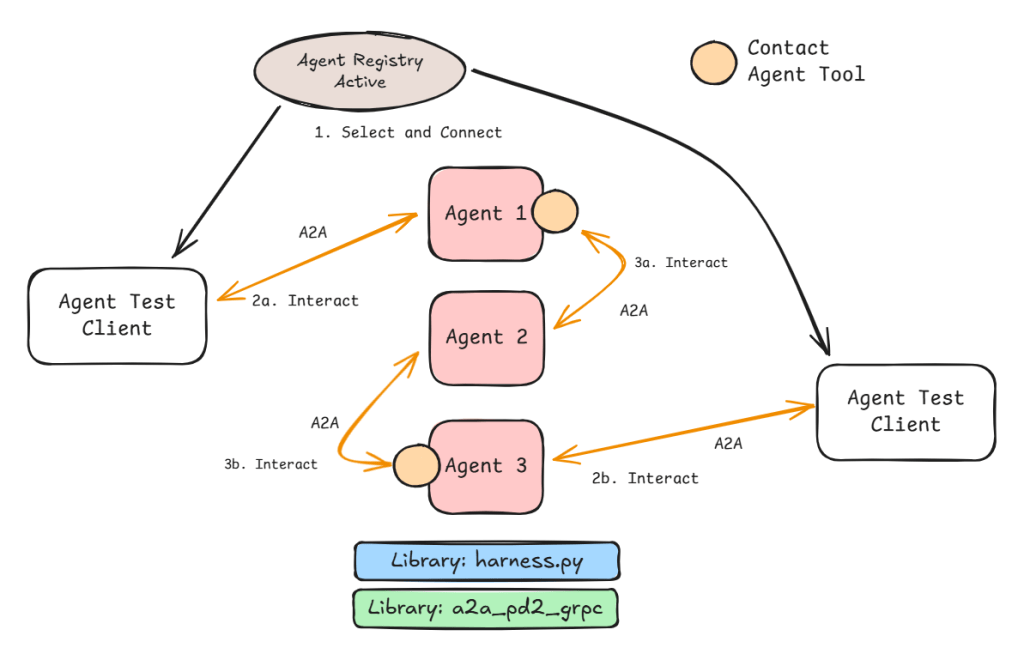
In Figure 3 the user starts the interaction (via the Agent Test Client) with Agent 1. Agent 1 as part of the interaction requires skills provided by Agent 2. It uses the Contact Agent tool to initiate an A2A request to Agent 2.
All the agents deployed have their own A2A Endpoint to receive requests. This can make the whole setup a peer-to-peer one if we provide a model that can both respond to human input as well as requests from other agents and not restrict the Contact Agent tool to specific agents. This means the interaction can start anywhere and follow different paths through the system.
Figure 3: Interaction and agent-to-agent using contact agent tool.
This flexibility of multiple paths is shown in Figure 4. The interaction can start from Agent 1 or Agent 3. If we provide the Contact Agent Tool to Agent 2 then this becomes a true peer-to-peer system. This is where the flexibility comes to the fore as does the relative unpredictability of the interaction.
Figure 5: The different agents and what roles they play.
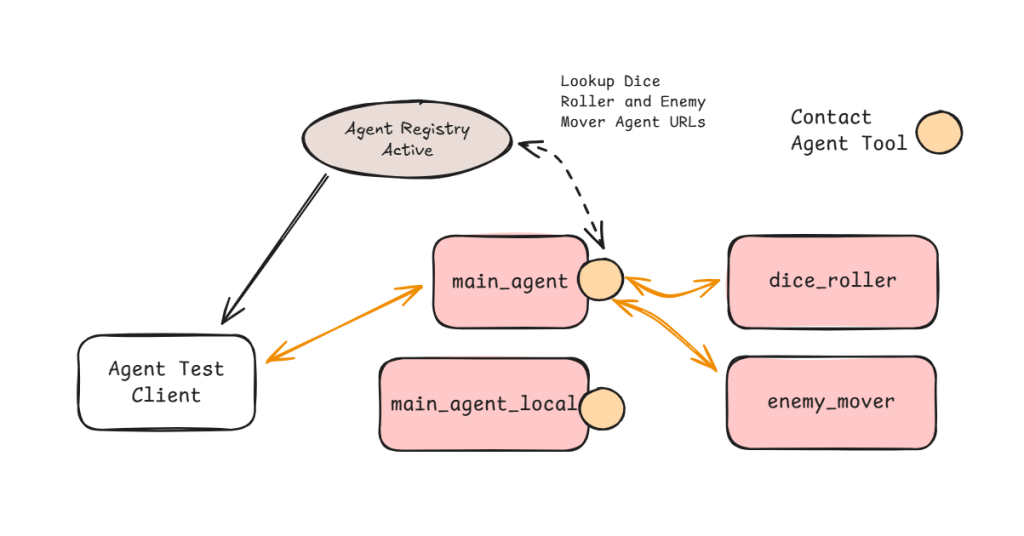
Figure 5 shows the test system in all its glory. All the agents shown are registered with the registry and therefore are independently addressable by external entities including the Test Client.
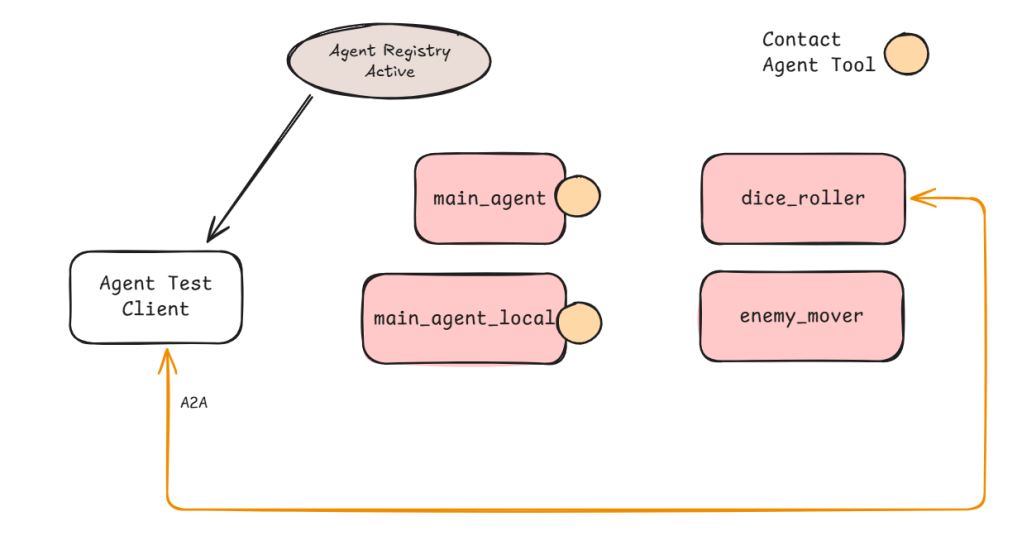
The main difference between the agents that have access to the Contact Agent tool and ones that don’t is the ability contact other agents. Dice Roller agent for example does not have the ability to contact other agents. I can still connect directly with it and ask it to roll a dice for me but if I ask it to move an enemy it won’t be able to help (see Figure 6).
On the other hand if I connect with the main agent (local or non-local variant) it will be aware of Dice Roller and Enemy Mover (a bit of Dungeons and Dragons theme here).
Figure 6: Every agent is independently addressable – they just have different levels of awareness about other agents in the system.
There is an interesting consequence of pre-populating the Agent list. This means the Agents that are request generators (the ones with the Contact Agent tool in Figure 6) need to be instantiated last. Otherwise the list will not be complete. If two agents need to contact each other then current implementation will fail as the agent that is registered first will not be aware of any agents that are registered afterwards. Therefore, we cannot trust peer-to-peer multi-agent systems. We will need dynamic Agent list creation (perhaps before every LLM interaction) but this can slow the request process.
Setup
Each agent is now an executable in its own right. We setup the agent with the appropriate runner function and pass it to a standard server creation method that brings in GRPC support alongside hooks into the registration process.
These agents can be found in the agent_as_app folder.
The generic command to run an agent (when in the multi_agent folder):
python -m agent_as_app.<agent py file name>
As an example:
python -m agent_as_app.dice_roller
Once we deploy and run the agent it will attempt to contact the registration app and register itself. The registration server which must be run separately can be found in agent_registry folder (app.py being the executable).
You will need a Redis database instance running as I use it for the session memory.
Contact Agent Tool
The contact agent tool gives agents the capability of accessing any registered agent on demand. When the agent starts it gets a list of registered agents and their skills (a limitation that can be overcome by making agents aware of registrations and removals) and stores this as a directory of active agents and skills along with the URL to access the agent.
This is then converted into a standard discovery instruction for that agent. As long as the agent instance is available the system will work. This can be improved by dynamic lookups and event-based registration mechanism.
The Contact Agent tool uses this private ‘copy’ to look up the agent name (provided by the LLM at time of tool invocation), find the URL and send an A2A message to that agent.
Enablers
The server_build file in lib has the helper methods and classes. The important ones are:
AgentMain that represents the basic agent building block for the GRPC interface.
AgentPackage that represents the active agent including where to access it.
register_thyself method (more D&D theme) is the hook that makes registration a background process as part of the run_server convenience method (in the same file).
Examples
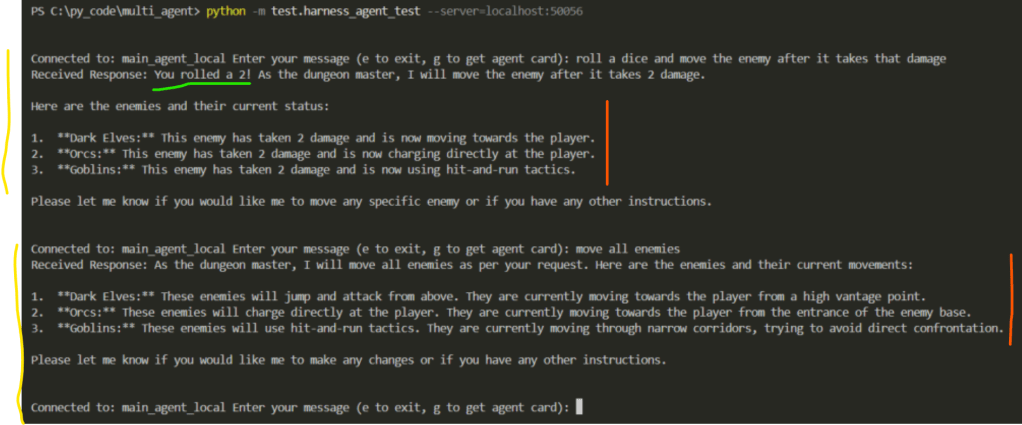
The interaction above uses the main_agent_local (see Figure 5) instead of main_agent as the interaction point. The yellow lines represent two interactions between the user and the main_agent_local via the Harness Agent Test client.
The green line represents the information main_agent_local gathered by interacting with the dice_roller. See screenshot below from the Dice Roller log which proves the value 2 was generated by the dice_roller agent.
The red lines represents interactions between the main_agent_local and the enemy_mover. See the corresponding log from enemy_mover below.
Key Insight: Notice how between the first and second user input the main_agent_local managed to decide what skills it needed and what agents could provide that. Both sessions show the flexibility we get when using minimal coupling and skills-based integration (as opposed to hard-coded integration in a workflow).
Results
I have the following lessons to share:
Decoupling and using skills-based integration appears to work but to standardise it across a big org will be the real challenge including arriving at org-wide descriptions and boundaries.
Latency is definitely high but I have also not done any tuning. LLMs still remain the slowest component and it will be interesting to see what happens when we add a security overlay (e.g., Agentic ID&A that controls which agent can talk with which other agent).
A2A is being used in a lightweight manner. Questions still remain on the performance aspect if we use it in anger for more complex tasks.
The complexity of application management provides scope for standard underlay to be created. In this space H1 2026 will bring lot more maturity to the tool offerings. Google and Microsoft have already showcased some of these capabilities.
Building the agent is easy and models are quite capable. Do not fall for the deceptive ease of single agents. Gen AI apps are still better unless you want a sprawl of task specific agents that don’t talk to each other.
Models and Memory
Another advantage of this decoupling is that we can have different agents use different models and have completely isolated resource profiles.
In the example above:
main_agent_local – uses Gemini 2.5 Flash
dice_roller – uses locally deployed Phi-4
enemy_mover – uses locally deployed Phi-4
Memory is also a common building block. It is indexed by user id and session id (both randomly generated by the Harness Agent Test client).
Next Steps
Now that I have the basics of a multi-agent system the next step will be to smoothen out the edges a bit and then implement better traceability for the A2A communications.
Try out complex scenarios with API-based tools that make real changes to data.
Explore guardrails and how they can be made to work in such a scenario.
When we use Gen AI within a workflow with predictive interactions with LLMs we can attempt to estimate the cost and time penalties.
Now agentic (true agentic – not workflows being described as agentic) is characterised by:
Minimum coupling between agents but maximum cohesion within an agent.
Autonomy
Use of tools to change the environment
This brings a whole new dimension to the cost and time penalty problem making it lot harder to generate usable values.
Why Are Cost and Time Penalties Important
The simple answer is the two inform the sweet spot between experience, safety and cost.
Experience
Better experience involves using tricks that require additional LLM turns to reflect, plan and use tools, moving closer to agentic. While this allows the LLM to handle complex tasks with missing information it does increase the cost and time.
From a contact centre perspective think of this as:
An expert agent (human with experience) spending time with the customer to resolve their query.
Now if we did this for every case then we may end up giving a quick and ‘optimal’ resolution to every customer but the costs will be quite high.
Safety
Safer experience involves deeper and continuous checks on the information flowing into and out of the system. When we are dealing with agents then we get a hierarchical system to keep safe at different scales.
Semantic safety checks / guardrails involve LLM-as-a-Judge as we expect LLMs to ‘understand’. This increases the time to handle requests as well as increases costs due to additional LLM calls to the Judge LLM.
Cost Model
This is the first iteration of the cost model.
Figure 1: Three level of interaction corresponding to numbers in the list below.
The cost model works at three levels (see Figure 1 above):
Single Model Turn – Input-LLM-Output
This is a single turn with the LLM.
Single Agent Turn – Input-Agent-Output
This is a single turn with the Agent – the output could be a tool call or a response to the user or Agent request.
Input can be from the user or from another Agent (in a Multi-agent system) or a response from the Tool.
Single Multi-agent System Turn – Input-Multi-Agent-System-Output
This is a single turn with a Multi-agent system. Input can be the user utterance or external stimulus and the output can be the response to the request.
A Multi-agent System can use deterministic orchestration, a semi-deterministic or fully probabilistic.
Single Model Turn
Item 1 in Figure 1. The base for input will be the prompt template which will be constant for a given input. We can have different input prompt templates for different sources (e.g., for tool response, user input etc.).
We assume a single prompt template in this iteration.
kI = Cost per token for input tokens (Agent LLM)
kO = Cost per token for output tokens (Agent LLM)
The constant cost per turn into the model: Cc = kI * tP
The variable cost per turn into the model: Cv = kI * tD
Total Cost per turn out of the model: Co = kO * tO
Total Cost per Model Turn = Cc + Cv + Co
This can be enhanced to compensate for Guardrails that use LLM-as-a-Judge. I also introduce a multiplier to compensate for parallel guardrails per turn that use LLM-as-a-Judge.
gI = Cost per token for input tokens (Judge Model)
gO = Cost per token for output tokens (Judge Model)
mG = Multiplier - for multiple parallel guardrails that use LLMs as Judge
The variable cost per turn into the judge model: Gv = gI * (tD + tP) * mG
Total Cost per turn out of the judge model: Go = gO * tO * mG
Total Cost per Model Turn (including Governance) = Cc + Cv + Co + Gv + Go
Single Agent Turn
Here a single agent turn will consist of multiple model turns (e.g., to understand user request, to plan actions, to execute tool calls, to reflect on input etc.).
In our simple model we take the Total Cost per turn and multiply it with the number of turns to get an estimate of the cost per Agent turn.
Total Cost for Single Turn = nA * Total Cost per Model Turn
nA = Number of turns within a single Agent turn
But many Agents continuously build context as they internally process a request. Therefore we can refine this model by increasing the variable input token count by the same amount every turn.
Incremental Cost of Variable Input = Cv += kI * tD * i
where i = 1 to nA + 1
Single Turn with Multi-agent System
A single user input or event from an external system into a multi-agent system will trigger an orchestrated dance of agents where each agent plays a role in the overall system.
Given different patterns of orchestration are available from fully deterministic to fully probabilistic this particular factor is difficult to compensate for.
In a linear workflow with 4 agents we could use an agent interaction multiplier set to 5 (user + 4 agents). With a peer-to-peer a given request could bounce around multiple agents in an unpredictable manner.
The simplest model is a linear one:
Total Cost of Single Multi-agent System Turn = total Cost of Single Agent Turn * nI
nI = Number of Agent Interactions in a single Multi-agent System Turn.
Statistical Analysis
Now all of the models above require specific numbers to establish costs. For example:
How many tokens are going into a LLM?
How many turns does an Agent take even if we use mostly deterministic workflows?
How many Agent interactions are triggered with one user input?
Clearly these are not constant values. They will follow a distribution in time and space.
Key Concept: We cannot work with single values to estimate costs. We cannot even work with max and min values. We need to work with distributions.
We can use different distributions to mimic the different token counts, agent interactions, and agent turns.
The base prompt template token count for example can be from a choice of values.
The input data token count and output token count can be sampled from a normal distribution.
For the number of turns within an Agent we expect lower number of turns (say 1-3) to be of high probability with longer sequences being rarer. We will have at least one agent turn even if that results in the agent rejecting the request.
Same goes for the number of Agent interactions. This also depends on number of agents in the Multi-agent system and the orchestration pattern used. Therefore, this is the place where we can get high variability.
Key Concept: Agentic AI is touted as large number of agents running around doing things. This takes the high variability above and expands it like a balloon as more agents we have in a Multi-agent system wider is the range of agent interactions triggered by a request.
Some Results
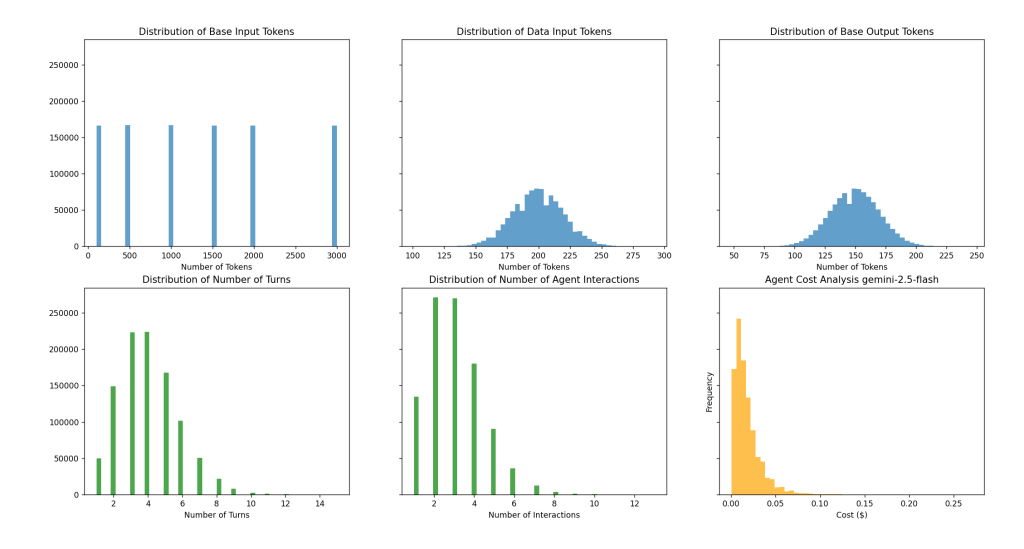
The distributions below represent the result of the cost model working through each stage repeated 1 million times. Think of this as the same Multi-agent system going through 1 million different user chats.
I have used Gemini-2.5-Flash costs for the main LLM and Gemini-2.5-Flash-Lite costs for LLM-as-a-Judge.
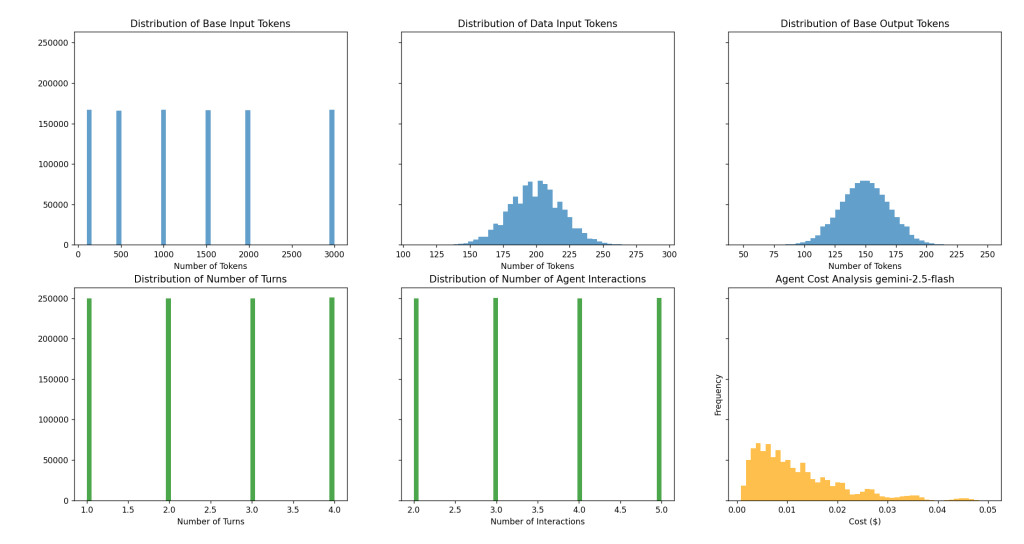
The blue distributions from Left-to-Right: Base Prompt Template Token Count, Data Input Token Count, and Output Token Count. These are the first stage of the Cost Model.
The green distributions from Left-to-Right: Number of turns per Agent and Number of Agent Interactions. These are the second and third stages of the Cost Model.
The orange distribution is the cost per turn.
Distributions of the Cost Model layers.
Expected Costs:
Average Cost per Multi-Turn Agent Interaction: $0.0174756 Median Cost per Multi-Turn Agent Interaction: $0.0133794 Max Cost per Multi-Turn Agent Interaction: $0.2704608 Min Cost per Multi-Turn Agent Interaction: $0.0004264 Total Cost for 1000000 Multi-Turn Agent Interactions: $17475.6268173
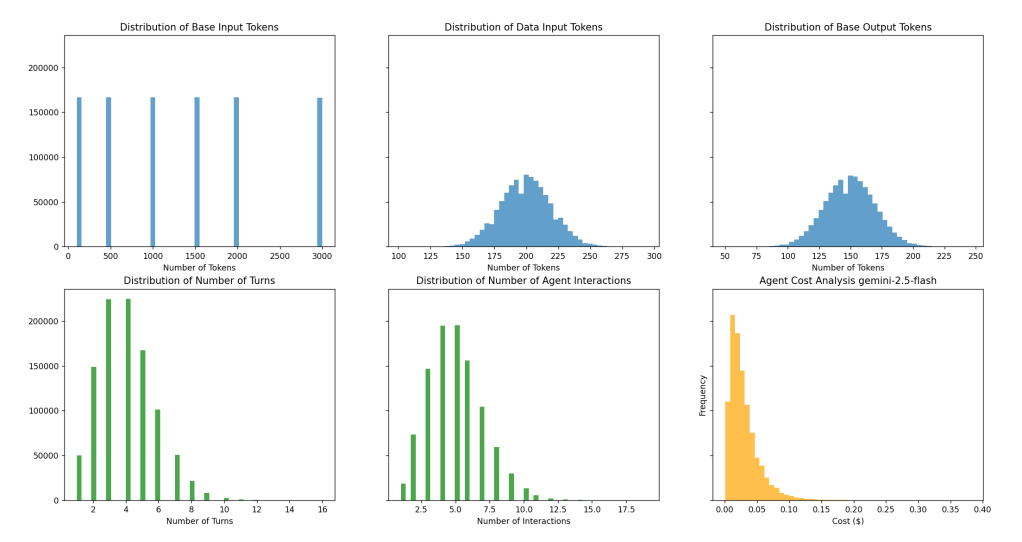
Distributions when we use specific choice for Turns and Agent Interactions.
Expected Costs:
Average Cost per Multi-Turn Agent Interaction: $0.0119819 Median Cost per Multi-Turn Agent Interaction: $0.0096888 Max Cost per Multi-Turn Agent Interaction: $0.0501490 Min Cost per Multi-Turn Agent Interaction: $0.0007306 Total Cost for 1000000 Multi-Turn Agent Interactions: $11981.8778405
Let us see what happens when we change the distribution for Agent turns to 4 (a small change from 2 previously).
Distribution with larger number of Agent interactions.
Expected Costs:
Average Cost per Multi-Turn Agent Interaction: $0.0291073 Median Cost per Multi-Turn Agent Interaction: $0.0232008 Max Cost per Multi-Turn Agent Interaction: $0.3814272 Min Cost per Multi-Turn Agent Interaction: $0.0004921 Total Cost for 1000000 Multi-Turn Agent Interactions: $29107.3320206
The costs almost double from increasing agent interaction from 2 to 4.
Key Concept: The expected cost distribution (orange) will not be a one time thing. The development team will have to continuously fine-tune based on Agent and Multi-agent System design approach, specific prompts, and tools use.
Caveats
There are several caveats to this analysis.
This is not the final cost – this is just the cost arising from the use of LLMs in agents and multi-agent applications where we have loops and workflows.
This cost will contribute to the larger total cost of ownership which will include operational setup to monitor these agents, compute, storage, and not to mention cost of maintaining and upgrading the agents as models change, new intents are required and failure modes are discovered.
The model output is quite sensitive to what is put in. That is why we get a distribution as part of the estimate. Individual numbers will never give us the true story.
Code
Code for the Agent Cost Model can be found below… feel free to play with it and fine tune it.
This post attempts to bring together different low level components from the current agentic AI ecosystem to explore how things work under the hood in a multi-agent system. The components include:
As ever I want to show how these things can be used to build something real. This post is the first part where we treat the UI (a command-line one) as an agent that interacts with a bunch of other agents using A2A. Code at the end of the post. TLDR here.
We do not need to know anything about how the ‘serving’ agent is developed (e.g., if it uses LangGraph or ADK). It is about building a standard interface and a whole bit of data conversion and mapping to enable the bi-directional communication.
The selection step requires an Agent Registry. This means the Client in the image above which represent the Human in the ‘agentic landscape’ needs to be aware of the agents available to communicate with at the other end and their associated skills.
In this first part the human controls the agent selection via the UI.
There is a further step which I shall implement in the second part of this post where LLM-based agents discover and talk to other LLM-based agents without direct human intervention.
Key Insights
A2A is a heavy protocol – that is why it is restricted to the edge of the system boundary.
Production architectures depend on which framework is selected and that brings its own complexities which services like GCP Agent Engine aim to solve for.
Data injection works differently between LangGraph and ADK as these frameworks work at different levels of abstraction
LangGraph allows you full control on how you build the handling logic (e.g., is it even an agent) and what is the input and output schema for the same. There are pre=made graph constructs available (e.g., ReACT agent) in case you did not want to start from scratch.
ADK uses agents as the top level abstraction and everything happens through a templatised prompt. There is a lower level API available to build out workflows and custom agents.
Attempting to develop using the agentic application paradigm requires a lot of thinking and lot of hard work – if you are building a customer facing app you will not be able to ignore the details.
Tooling and platforms like AI Foundry, Agent Engine, and Copilot Studio are attempting to reduce the barriers to entry but that doesn’t help with customer facing applications where the control and customisation is required.
The missing elephant in the room – there are no controls or responsible AI checks. That is a whole layer of complexity missing. Maybe I will cover it in another part.
Setup
There are two agents deployed in the Agent Runner Server. One uses a simple LangGraph graph (‘lg_greeter’) with a Microsoft Phi-4 mini instruct running locally. The other agent uses ADK agent (‘adk_greeter’) using Gemini Flash 2.5. The API between the Client and the Agent Runner Server is A2A (supporting the Message structure).
Currently, the agent registry in the Agent Runner Server is simply a dict keyed against the string label which holds the agent artefact and appropriate agent runner.
It is relatively easy to add new agents using the agent registry data structure.
Memory is implemented at the Agent Runner Server and takes into account the user input and the agent response. It is persisted in Redis and is shared by all agents. This shared memory is a step towards agents with individual memories.
There is no remote agent to agent communication happening as yet.
Output
The command line tool first asks the user which agent they want to interact with. The labels presented are string labels so that we can identify which framework was used and run tests. The selected label is passed as metadata to the Agent Runner Server.
The labels just need to correspond to real agent labels loaded on the Agent Runner Server where they are used to route the request to the appropriate agent running function. It also ensures that correct agent artefact is loaded.
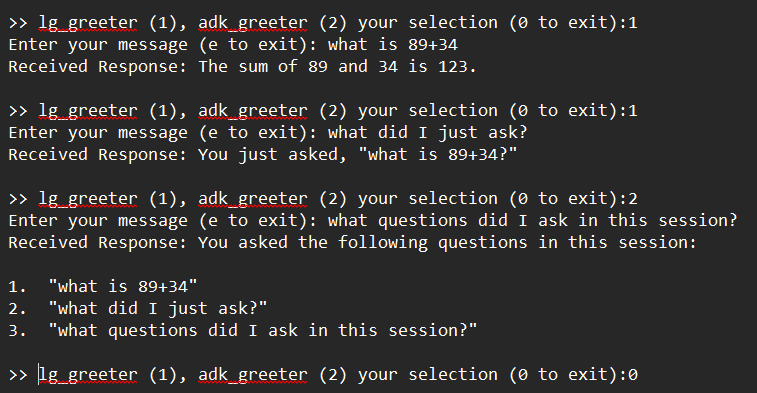
The code is in test/harness_client_test.py
In the test above you can see how when we ask a question to the lg_greeter agent it then remembers what was asked. Since the memory is handled at the Agent Runner level and is keyed by the user id and the session id it is retained across agent interactions. Therefore, the other agent (adk_greeter) has access to the same set of memories.
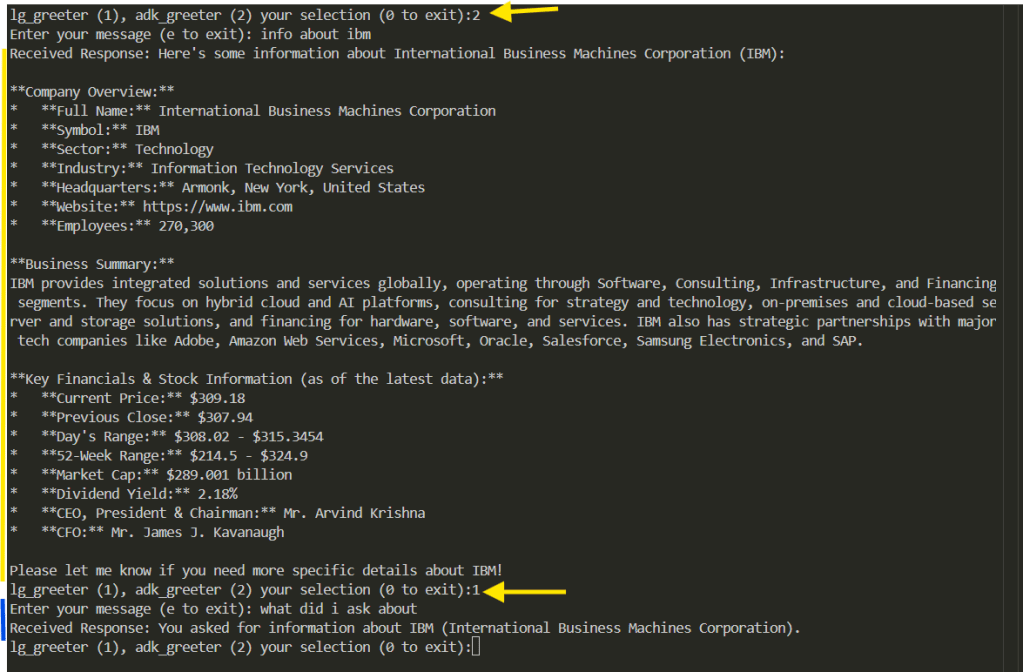
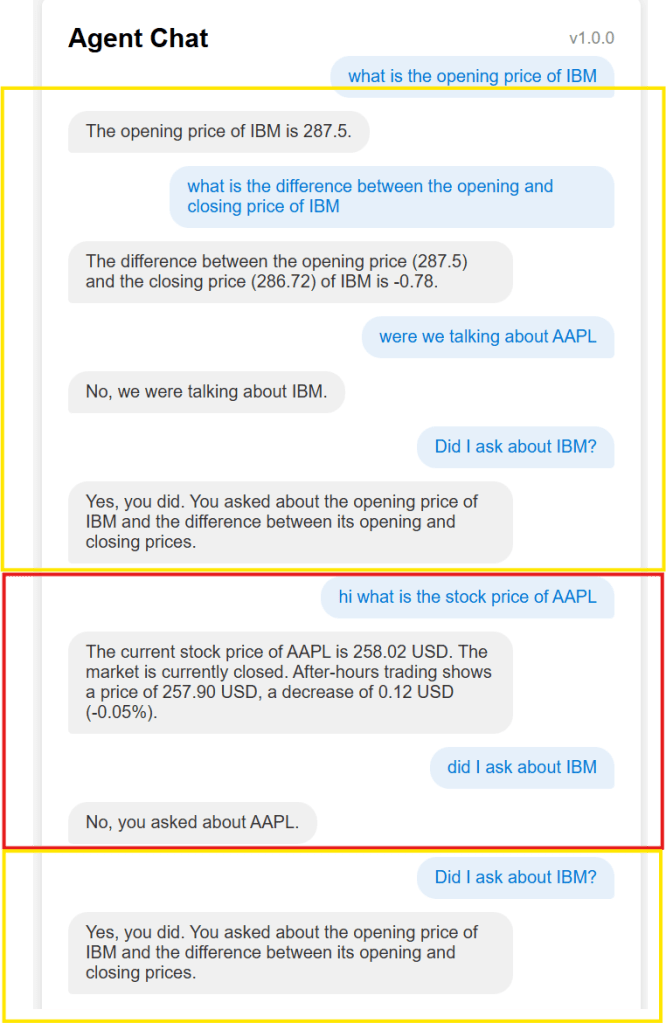
Adding Tools
I next added a stock info tool to the ADK agent (because LangGraph agent running on Phi-4 is less performant). The image below shows the output where I ask ADK (Gemini) for info on IBM and it uses the tool to fetch it from yfinance. This is shown by the yellow arrow towards the top.
Then I asked Phi-4 about my previous interaction which answered correctly (shown by the yellow arrow towards the bottom.
Adding More Agents
Let us now add a new agent using LangGraph that responds to the user queries but is a Dungeons&Dragons fan therefore rolls 1d6 as well and gives us the result! I call this agent dice (code in dice_roller.py)
You can see now we have three agents to choose from. The yellow arrows indicate agent choice. Once again we can see how we address the original question to dice agent and subsequent one to the lg_greeter and then the last two to the adk_greeter.
A thing to note is the performance of Gemini Flash 2.5 on the memory recall questions.
You will need a Gemini API key and access to my genai_web_server and locally deployed Phi-4. Otherwise you will need to change the lg_greeter.py to use your preferred model.
Check out the commands.txt for how to run the server and the test client.
In this post I will cover points 1, 2 and 4. Point 3 I feel is needed only in specific use-cases and current tooling for Long Term Memory is evolving rapidly.
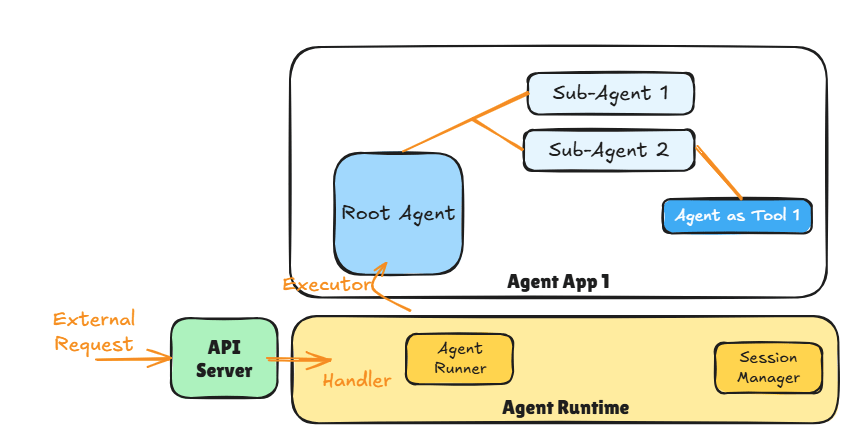
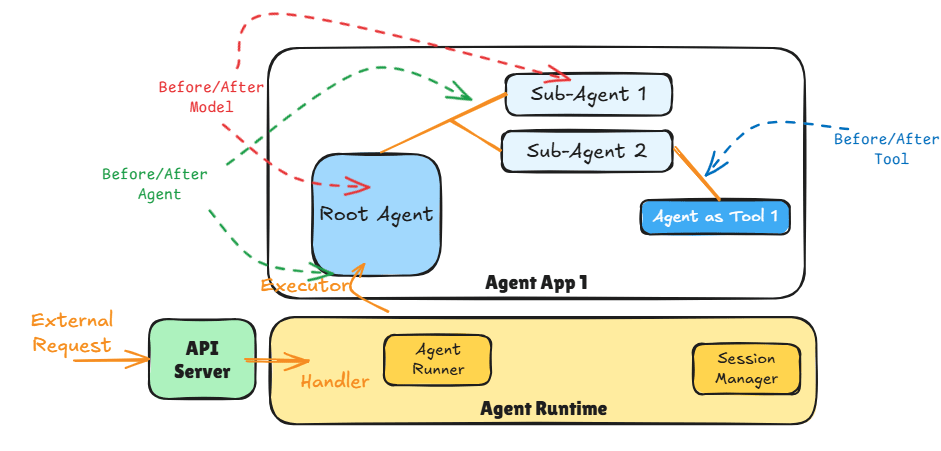
Interaction between the Agentic Application, Agent Runtime and API Server.
The diagram above shows the major components of an Agentic Application. The API Server is responsible for providing an endpoint (e.g., https REST, message queue) that external applications (e.g., chat client) can use to access the Agent App 1.
The API Server then invokes the appropriate handler method when the API is invoked. The handler method is responsible for triggering the Agent Runner in the Agent Runtime that deals with the execution of the Agent App 1.
The Agent Runtime is the component that:
1. Sets up the correct session context (e.g., current session history if the conversation thread is resuming) using the Session Manager
2. Manages the Agent Runner which executes the Agent App 1 by triggering its Root Agent.
Remember as per ADK one Agentic Application can only have one Root Agent per deployment.
The Agent Runner is then responsible for finishing the agentic app execution (including handling any errors). Agent Runtime then cleans up after the Agent Runner and returns any response generated by the Agent App 1 back to the handler where it can be returned to the caller using API constructs.
Key Concept: If the Agentic App does not have a sequential workflow and instead depends on LLMs or contains loops then the app keeps going till it emits a result (or an error).
This makes it difficult to set meaningful time-outs for request-response style and we should look at async APIs (e.g., message based) instead.
API Server
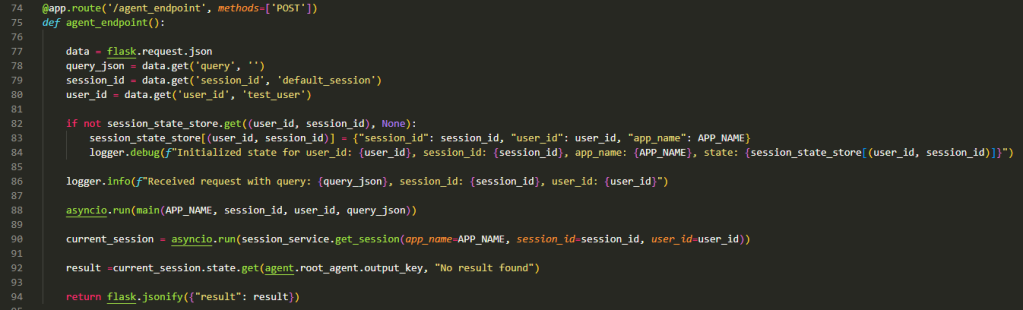
REST API Handler function example using Flask.
The code above shows the API handler function using Flask server.
Lines 77 – 80 are all about extracting data from the incoming request to deal with User, Session management and the Query integration (e.g., incoming text from the user for a chat app). Here we assume the requesting application manages the User Id (e.g., a chat app that handles the user authentication and authorisation) and Session Id.
Lines 82-84 are all about setting up the session store if no existing session context is found. This will usually trigger when the user say first engages with the agent at the start of a new conversation. It is indexed by User Id and Session Id.
Key Concept: The session boundary from an agents perspective is something that needs to be decided based on the use-case and experience desired.
Line 88 is where the Agent Runtime is triggered in an async manner with the Application Name, User Id, Session Id, and the Query. The Application Name is important in case we have multiple Agentic Applications being hosted by the same Agent Runner. We would then have to change the session store to also be indexed by the App Name.
Line 90 extracts the final response of the Agent from the session state and is executed once the Agent Runtime has finished executing the Agentic Application (Line 88) which as per our Key Concept earlier is when the final result or an error is produced by the Root Agent.
Beyond Line 90 the method simply extracts the results and returns them.
This code is to show the API Server interacting with the Agent Runtime and must not be used in production. In production use async API style that decouples API Server from the Agent Runner.
Running Agents and Session State Management
ADK defines a session as a conversation thread. From an Agentic App perspective we have three things to think about when it comes to sessions:
Application Name
User ID
Session ID
These three items when put together uniquely identify a particular application handling requests from a given user within a specific conversation thread (session).
Typically, session management requires managing state and lots of record keeping. Nothing very interesting therefore ADK provides a few different types of Session Managers:
InMemorySessionManager – the most basic Session Manager that is only suitable for demos and learning more about session management.
DatabaseSessionManager – persisted version of the Session Manager.
VertexAISessionManager – the pro version which utilizes the VertexAI platform to manage the Session State. Best thing to use with Agent Engine for production workloads.
In this post I use the InMemorySessionManager to show how session management works and how we execute an agentic application.
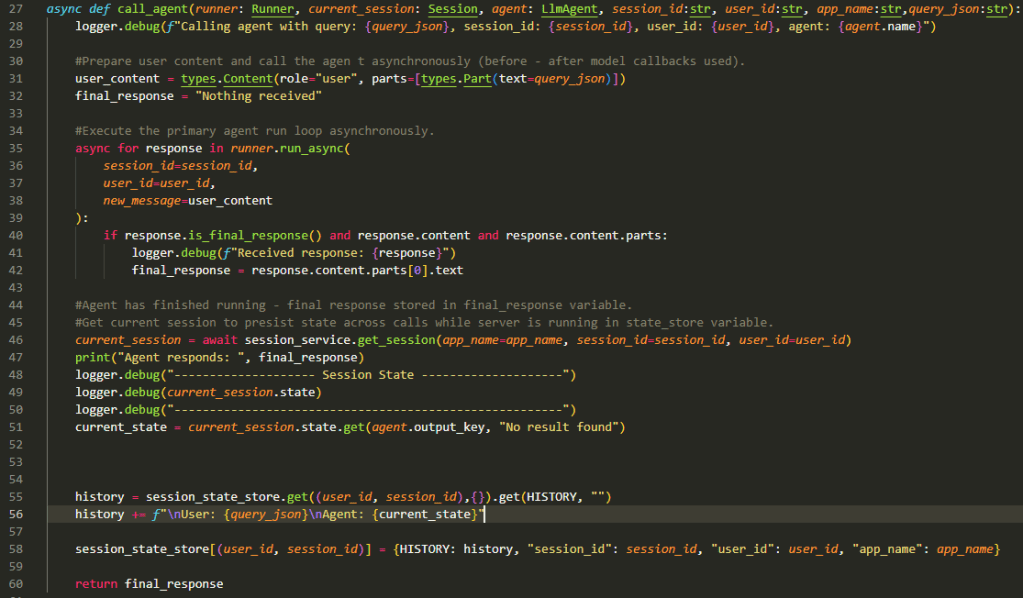
Setting up the Agent Runner and session in ADK.
The main method (Line 62 onwards in the above – invoked on Line 88 in previous listing) represents the Agent Runtime (e.g., Agent Engine in GCP) triggering the agents it is hosting (Agent App 1). It is taking the App Name, Session Id, User Id, and the incoming Query as described previously.
The Agent Runner is setup on Line 64.
On Line 66 the Agent Runtime initialises the current session (an instance of InMemorySessionManager) in ADK and provides the starting session state from the session state store. This will either be a freshly initialised session (blank state) or an existing session as per the logic shown previously.
Finally, on Line 69 we use the ‘call_agent’ method to configure and execute the Agent Runner. As you can see we are passing the ‘root_agent’, current session, and other details like session Id and query to this method.
Running the Agentic App.
This is the fun bit now…
Lines 31 and 32 are all about extracting what we received from the external application (in this case what the user typed in the chat box) and preparing a ‘default’ response (in case of issues with agent execution).
Lines 35-42 is where the core execution happens for Agent App 1. Since the app is running in async mode it will go through a set of steps where the root agent is triggered and it in turn triggers sub-agents and tools as needed. The async for goes through the responses till the root agent provides the final response signalling the end of the execution of the app. The final response is extracted and stored for eventual return back to the API Server.
Lines 46-51 simply extract the final session state and log it. Nothing interesting there unless you are after an audit trail.
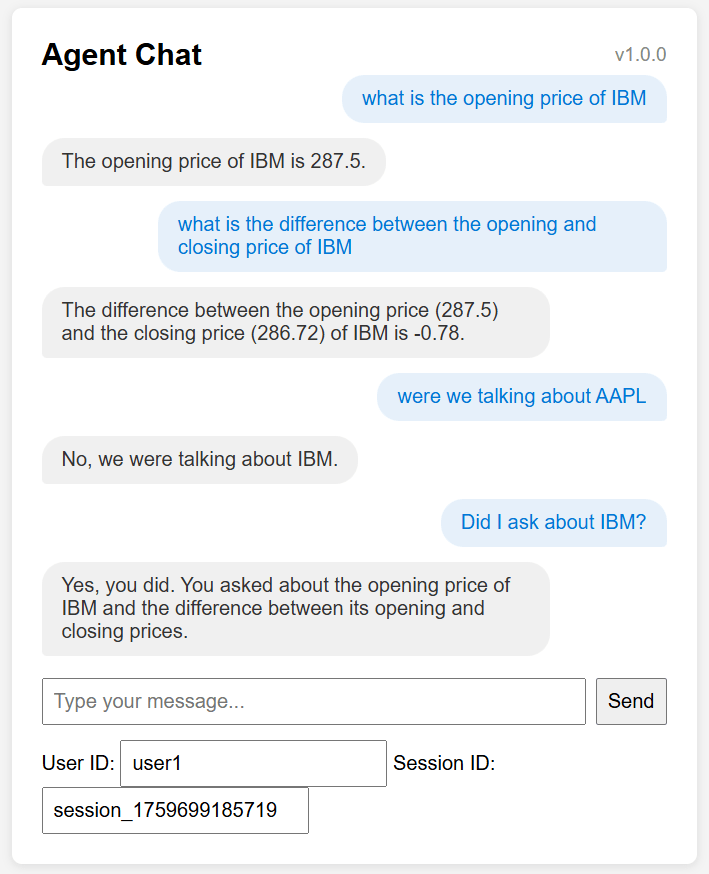
Lines 55-58 is where we build up the session which allows the agents to remember the context and previous inputs/outputs in the conversation session. We extract the current state from the state store, add to it the user’s request and the agent’s response (think of it like adding a request – response pair). Finally the state store is updated (using the ‘history’ key) so when user responds to the agent’s current output the session history is available to guide the agent on what to do next.
The session history is also called Short Term Memory. When you use VertexAISessionManager with Agent Engine or the ‘adk web’ testing utility you get all of this for free. But now you know how it works!
Logging and Monitoring
Line 35 is where we enter the mysterious async-probabilistic realm of Agent Execution and we need logging and monitoring to help us comprehend the flow of the agent execution as the control passes between Agents and from Agents to tools.
Utilities like ‘adk web’ show the flow of control within the Agentic Application through a connected graph. But how does this work? What mechanisms are available for developers to get telemetry information? By default Agent Runtimes like Google’s Agent Engine provide built-in capability to generate telemetry using OpenTelemetry standard that can then be consumed by likes of Cloud Trace or AgentOps.
In this section we look at the internals of the root agent and see how we collect information as it executes. I also show my own (vibe-coded no less) version of the ‘adk web’ flow visualisation.
Callbacks for the Root Agent.
The root agent is defined in Line 97 as per the standard constructor for LLMAgent till Line 103.
We see the usual parameters for the name, model, description, instruction (prompt), tools (using Agent as Tool paradigm) and the output key for the root agent.
Then come the callbacks (Lines 103-108) that allow us to track the flow of the Agent application. There are six types of callbacks and between them they tap the strategic points in the Agent-Agent and Agent-Tool flows.
The six callbacks supported by ADK and their touchpoints in the Agentic Application.
Before and After Tool: wraps a tool call. This allows us to tap into all the tool calls the agent makes and any responses returned by the tool. This is also the place to execute critical guardrails around tool calling and responses.
Before and After Model: wraps the call to the Large Language Model. This allows us to tap into all the prompts going into the LLM and any responses returned by the Model. This is also the place to execute critical guardrails around input prompts and responses – especially to ensure LLMs are not called with unsafe prompts and any harmful responses blocked.
Before and After Agent: wraps the call to the agent which allows us to tap into all the inputs going into the agent (including user inputs and agent requests) and any outputs.
These callbacks are defined at the level of the agent therefore, it can be used to track the flow through the Agent App 1 going from one agent to another.
Callbacks for the Sub-Agent.
The above shows callbacks registered for the Sub-Agent (named info_gather_agent).
Callbacks
Two examples of callbacks: After Tool and Before Agent.
The above examples show two callback examples out of the 6 possible for the root agent. The standard pattern I have used is:
Log the input provided using python logging for audit purposes.
Record the complete trace of the short term memory as a memory record (in MongoDb) for us to visualise the flow.
One example flow of Human to Root Agent to Sub-Agent to Tool and so on.
In the flow diagram above we see:
Time flowing from top of the image to the bottom.
Human input as the blue dots.
Purple dots are the Sub-Agent (called info_gather_agent).
Green dots are the Root Agent’s response.
Yellow dots are tool calls.
Given we use Agent as tool for communication we see Yellow -> Purple -> Yellow signifying the Root Agent invoking the Sub-Agent as a tool.
Yellow -> Green -> Yellow is the Sub-Agent responding to the Root Agent and the Root Agent processing that input.
Green -> Blue -> Yellow is the Root Agent responding to the Human and the Human responding with a follow up question.
This visualisation was completely vibe-coded based on the document structure of the memory record in MongoDb.
Key Concept: Note the short return trace after ‘were we talking about aapl’ the last question from the Human. The Root Agent does not need to engage with any other agent or tool. It can simply examine the history we have been collecting to answer the question.
Chat App output can be seen below (entry in blue is the human asking questions and grey is the Root Agent responding):
The Chat web-app was also vibe coded in 10 mins just to have something visual to show instead of Postman requests.
It also shows how the web-app could collect User Id and Session Id defaulting to the ‘application-led’ ID and Authorisation model.
We can play around with the session Ids to give parallel chat experience (same user with two open sessions) – see above.
session_1759699185719 – talking about IBM stock (yellow boxes)
session_1759699185720 – talking about AAPL stock (red box)
Code
By now I hope you are ready to start playing around under the hood to improve your understanding of the tech. Remember concepts never die – they just become abstract implementations.
How does one identify a ‘real’ AI Agent developer? They don’t use ‘adk web’ to demo their agent.
Silly jokes aside, in this post I want to talk about building an app with AI Agents. The focus is on GCP stack. Google’s Agent Engine – ADK combination looks like a really good option for pro-code development that abstracts out many common tasks.
I do not like magical abstraction as it blocks my understand of ‘how things work’. Therefore, I will use Google’s ADK to build our agents and instead of hosting it on Agent Engine I will write the application that provides a snug and safe environment for the agents.
This will be a text heavy post where I introduce key aspects. I will follow this up with a code heavy set of posts looking at Sessions, Memory, and Telemetry.
Let us first look at what Agent Engine helps us out with as an Agent developer:
Session State: the internal state that the agent uses to carry out the task – includes knowledge and facts gathered
Long Term Memory: the long term memory created by compressing and updating based on the internal state of the agent
Logging/Telemetry: the data stream coming from the agent that helps us monitor, troubleshoot and audit.
Agent Runner and API: the infrastructure that runs the agents and creates the API for our agent to be published for use.
All of the things in the list above are done for us when we use ‘adk web’ or similar ‘agent testing’ tool. This container for the agents is the ‘Agent Application’.
Agent Engine and adk are two examples of ‘Agent Applications’ that we can use to deploy Agents written in ADK. Agent Engine also supports LangGraph and other frameworks.
Writing an Agent Application
Writing an Agent Application requires a deep dive into concepts that are critical to agent operations: session, memory, and telemetry. Fortunately, ADK gives us all the core capabilities to build these out. For example, when using adk web our agents remember what the user said before, this is because the adk web Agent Application is taking care of session management for us.
One also needs to understand the lifecycle of an interaction so let us look at this first.
Interaction Lifecycle
In any agentic interaction there is usually a user or external system (or agent), there is also an agentic application they interact with, and the interaction is usually bound to an intent called a session (e.g., I want to open a new account). The interaction continues till the intent is satisfied or rejected.
The interaction lifecycle gives us scope for any state and memory we use.
User: Scope is the user. This typically will be information associated with the user like their username, preferences etc. This will span application and session scope. Identified by ‘user_id’.
Application: Scope is the application. This typically will be information required to operate the app. This allows the same agent to have different application state when used in different applications. For example, credentials for agents, application level guardrails (e.g., do not give advice) and global facts. Identified by ‘app_name’.
Session: Scope is the current session. This will contain the short-term (or scratchpad) state associated with the ongoing interaction for the agent to use while the session is active. This includes the users inputs like the reason to contact and any responses by the agent. The client in this case will need to ensure state management by reusing the same user, session and app ID when it wishes to maintain the session continuity (e.g., in case of a disconnect).
Now let us look at the Session, Memory and Telemetry.
Session
Session is all about the local state of the Agent. ADK has the Session object that provides the data structure to store session info and a SessionService object that manages the session data structure.
The SessionService is responsible for the entire session state management and Google do not want us to manually write to the session object. The only two special cases being when the interaction starts (to preload state) and when it finishes (to save state). Even for this we are expected to use the appropriate lifecycle callbacks. More on callbacks later.
SessionService comes in three flavours:
InMemorySessionService – for testing locally (outside Agent Engine).
VertexAISessionService – for production deployment using Agent Engine (abstracts away).
DatabaseSessionService – developer managed generic persistent session service for production environment that can use any SQL db.
The Session object is identified by the combination of session_id, user_id, and app_name.
Session object has the following properties:
History – an automatically updated list of significant events (managed by ADK).
Session State – the temporary state of the agent to be managed by the application for use by the agent as a scratchpad.
Activity Tracking – this is a timestamp of the last event for tracking (managed by ADK).
A key question for me is how does one manage shared user sessions (e.g., in case of a joint bank account). Some creative coding and user management is needed.
Memory
This represents the session state processed and stored as a ‘memory’ for use in later interactions. The retrieval happens based on the user_id and app_name to ensure compartmentalisation.
The MemoryService manages the creation, management, and retrieval of memories. As a developer we do not have any control in the memory creation and management process. If we want full control then there are examples of accessing closed session state or checkpoint running session state to create/manage memories manually.
It comes in two flavours:
InMemoryMemoryService – nicely named service for when we are testing.
VertexAIMemoryBank – to be used with Agent Engine which abstracts the process and provides persistence.
Telemetry
Telemetry includes all information that flows in and out of an agent. These streams then have to be tied up together as information flows through a system with multiple interacting agents to identify issues and troubleshoot when things go wrong.
Without telemetry we will not be able to operate these systems in production. For regulated industries like banking and healthcare additional audit requirements are there. Therefore, focus on what to collect. This post will talk about how to collect.
When using Agent Engine a variety of tools are available that can collect the OpenTelemetry-based feeds produced by it. Cloud Trace is the GCP native service for this.
Collecting with Callbacks
ADK supports 6 basic callbacks. This enables us to access state and input/output information as the agent operates.
Before/After LLM: Callbacks triggered just before and after the LLM is engaged. Use this to audit LLM request and response as well as interception for guardrails (checking input for relevance, harm etc. and checking output for quality and content).
Before/After Tool: Callbacks triggered just before and after a tool is engaged. Use this to audit tool use (inputs and outputs) as well as for debugging tool requests generated by the LLM.
Before/After Agent: Callbacks triggered just before and after the agent engages. This is used to audit inputs going into the agent and the response produced by the agent. This is specifically the input and output to the user.
LLM and Tool Callbacks tell us about the inner workings of the agent (private thoughts). Agent callbacks tell us about the external workings of the agent (public thoughts).
Callbacks are the Google recommended mechanism for changing state and they also provide a set of patterns (sharing links here):
Remember callbacks must be implemented in a manner that:
Does not add latency – use async mechanism
Does not introduce parallel logic for processing data
Does not become an alternative integration point
Logging
ADK also supports python logger sub-system. If DEBUG level is used then every aspect of a running agent is logged plus more. But this increases the data processing load as well as tends to slow down the processing.
High data volumes will require significant processing (including correlation of different streams, root cause analysis, and time-series analysis) before it can be converted into an event stream prioritised by criticality to enable Human-on-the-loop (human as a supervisor). I do not expect human-in-the-loop (human as an approver) to be a viable method for controlling and monitoring multi-agent systems.