The attention mechanism was an important innovation and led to the rise of large language models like GPT. The paper ‘Attention is all you need’ introduced the Transformer network architecture which showed state-of-the-art performance, in sequence prediction tasks, using only the attention mechanism. The attention mechanism used in the paper is called ‘Self-attention’.
Self-attention mechanism learns to pay attention to different parts of the input sequence. This is done by learning how the input sequence interacts with itself. This is where the Key and Query tensors play an important role.
The Key and Query tensors are computed by multiplying the input tensor (in embedding format) with two different weight tensors. The resultant tensors are referred to as the Key and Query tensors. The attention mechanism is trained by tuning the Key, Query, and Value weights. Once trained, the attention mechanism is then able to ‘identify’ the important parts of the input which can then be used to generate the next output token.
If I is the input tensor and Wk and Wq are the Key and Query weights then we can define the Key (K) and Query (Q) tensors as:
K = I @ Wk (1)
Q = I @ Wq (2)
(where @ stands for matrix multiplication)
Key Understanding: For each token in the input (I) we have embeddings. The same embeddings are then matrix multiplied three times – once with weights for the Key, once with weights for the Query, and once with weights for the Value. This produces the Key, Query, and Value tensors.
Attention Score
The attention score (self-attention) is calculated by scaling and taking the dot product between Q and K. Therefore this mechanism is also referred to as ‘scaled dot-product attention’. The output of this operation is then used to enhance/degrade the Value tensor.
Key Understanding: The attention score ‘decorates’ the value tensor and is a form of automated ‘feature extraction’. In other words, the attention mechanism pulls out important parts of the input which then aids in generating contextually correct output.
Need for Transformations
These transformations change the ‘space’ the input words (tokens strictly speaking) are sitting in. Think of it like putting two dots on a piece of cloth and then stretching it. The dots will move away from each other. Instead if we fold the piece of cloth then the dots come closer. The weights learnt should modify the input in a way that reflects some property of the inputs. For example, nouns and related pronouns should come closer in a sentence like:
‘The dog finished his food quickly.’
Or even across sentences:
‘My favourite fruit is an apple. I prefer it over a banana.
Key Understanding: We should be able to test this out by training a small model and investigating the change in similarity between the same pair of tokens in the Key and Query tensors.
An Example
Let process the following example: “Apple iPhone is an amazing phone. I like it better than an apple.”
The process:
- Train a small encoder-decoder model that uses attention heads.
- Extract Key and Query weights from the model.
- Convert the input example above into embeddings.
- Create the Key and Query tensors using (1) and (2).
- Use cosine similarity to find similarity between tokens in the resulting tensors.
- Plot the similarity and compare the two outputs.
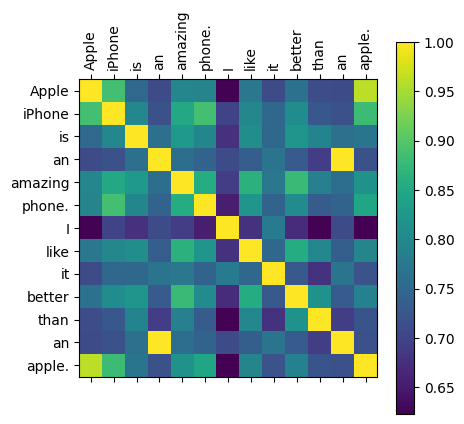
Below we can see the similarity measure between Key tensor tokens for the example input.
Below we can see the similarity measure between Query tensor tokens for the example input.
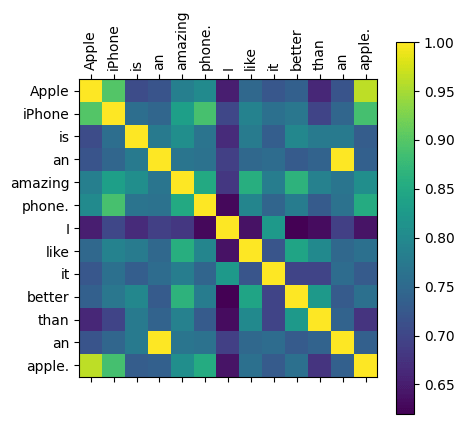
The yellow blocks in the above figures show exactly the same token (1.00).
‘an’ is a token which is repeated in the example sentence therefore the yellow block lies outside the diagonal.
The tokens ‘apple.’ and ‘Apple’ are quite similar (0.96) in both the Key and Query tensors, but unfortunately not in the current context as these refer to different objects. Similarly, if we look at the tokens ‘Apple’ and ‘iPhone’ (the first row) we find high similarity in both the tensors.
For ‘Apple’ and ‘than’ the similarity in the Key tensor is around 0.72. For the Query tensor it is around 0.68. This means these tokens are closer in the Key space (higher similarity) than the Query space.

Figure 3 shows the difference in similarity for the same text between the Key and Query tensor. If we look at ‘Apple’ and ‘apple.’ we see the difference between the two tensors is around 0.001.
This is where the architecture and training process play a critical role. For a model like GPT-3.5, we expect the context to be crystal clear and the generated content should be aligned with the context. In other words, the generated output should not confuse Apple iPhone with the apple the fruit.
Key Understanding: The architecture that involves structures such as multiple attention heads (instead of one) will be able to tease out many different relationships across the input.
Training larger models with more data will ensure the Key and Query weights are able to extract more ‘features’ from the input text to generate the correct output.
