Effective from 17th May 2024.
Model risk management (MRM) is a process the regulator expects all UK banks to implement if they are using any kind of model-based decision making. This is not a ‘new’ process for the development, verification, monitoring, and reporting of machine learning, statistical, and rule-based decision models. The end-to-end process is shown in the image below. There are additional components like the Model Inventory.
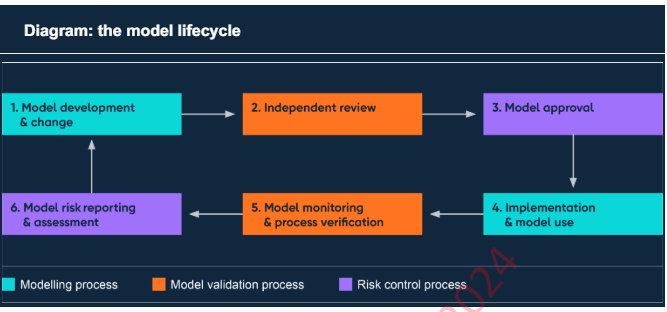
Why is this important?
This is important because MRM covers any type of AI model, doesn’t matter if you build it or you buy it. Doesn’t matter if it is a small XGBoost model or a Large-Language Model. There are clear guidelines for what is expected as part of the modelling process, validation process, and the risk control process.
I don’t think anyone knows how this applies to LLMs. If anyone has ideas I am happy to learn more.
Especially, third-party LLMs like Llama, Mistral, etc. where details of the modelling process are hidden behind intellectual property protection. Model validation and risk management are also new things when it comes to Large-Language Models. The main reason being that we cannot easily tie these to a specific use-case. All you need to do to change the behaviour of a LLM is to change the prompt. You can make it summarise text and then change the prompt to make it answer a question.
The Context
Let us look at various important definitions and concepts presented in SS 123.
Who is covered by SS 123
All regulated UK banks and building societies.
Why do we need SS 123
To manage Model Risk – this is the risk to the consumer, the bank, and/or the wider economy arising from the inappropriate use of models or due to errors made by the models.
What is covered by SS 123
Business decision making, risk management, and reporting – wide coverage.
What is a Model?
SS 123 defines a model (Principle 1.1 [a]) on pages 8 and 9 as:
A model is a quantitative method, system, or approach that applies statistical,
economic, financial, or mathematical theories, techniques, and assumptions to
process input data into output. The definition of a model includes input data that are
quantitative and / or qualitative in nature or expert judgement-based, and output that
are quantitative or qualitative.
Why do I think this covers LLMs? Because Principle 1.1 [a] explicitly mentions qualitative inputs and outputs, including expert judgement-based. Expert judgement-based aligns nicely with a ‘prompt’ for the LLM.
Additionally SS 123 Principle 1.3 talks about risk-based model tiering in order to identify and classify models that represent the highest risks as it goes through the model lifecycle. Why do I think LLMs should be in the ‘highest’ risk (i.e., most effort)? Let us understand through the ‘materiality’ (impact) and ‘complexity’ rating as described in SS 123.
Materiality
Size-based measures based on exposure, number of customers, and market values and qualitative factors related to its importance to informing business decisions.
LLMs are expected to be used by a large number of related use-cases. These could be as a shared instance or multiple instances of the same model. Therefore, the exposure could be widespread. Furthermore the use of LLMs in summarising, Q&A, and augmentation are all examples of ‘informing’ business decisions. For example, an agent using Gen AI-based Q&A system could rely on interpretation and summarisation provided by a Gen AI model.
Complexity
Various factors including: nature and quality of input data, choice of methodology, requirements and integrity of implementation, and the extensiveness of use of the model. But that is not all, when it comes to ‘newly advanced approaches or technologies’ (page 10), the complexity assessment may also consider risk factors related to: use of alternative and unstructured data, and measures of a model’s interpretability, explainability, transparency, and the potentials for designer or data bias to be present.
This last bit is written for LLMs: the use of unstructured data like text, images, and video. Evaluation of model interpretability, explainability, bias etc. are all important unsolved issues with LLMs.
Finally there is requirement for independent assessment and reassessment of models. How would this work for LLMs? Who would do the assessment?
Work To Do Ahead!
Lot of work still needs to be done clearly by all banks and regulated entities but there are many critical unknowns in this area. Key unknowns are how do we carry out independent reviews without clear guidelines? How do we verify the model build and ongoing testing of LLMs, especially those built by third-parties.
Within a bank a key role will be that of the model owner as they will be accountable for model use and with third-party LLMs will not be able to control the development of the same. Does this mean the end-state for LLMs is all about self-build, self-manage, and self-govern? Because there are two other roles: model users and model developers and the risk starts to build up right from when we start planning the model (e.g., selecting datasets and the LLM task).
Finally, the proportionality of MRM principles implies the largest entities (banks) need to make the most effort in this. In fact even simple requirements like tracking models in a model inventory (Principle 1.2) – the type of information you would need to track for LLMs is not straightforward as compared to a traditional machine learning model.
