Imagine you live in a small town in the hinterland.
Imagine the authorities in power ask you to contribute some money towards building a big amusement park in the capital city.
Now imagine, year after year, you hear impressive things about the amusement park—how new rides are being added, and how more and more people visit every year.
Pretty soon, you learn that entrance tickets are now difficult to get and getting more expensive. There’s a waiting list and entry criteria. But the amusement park continues to attract even more visitors each year.
Then one day, you say to yourself: “I need to go and see what the fuss is all about.” You work out the entry criteria and fill in the proper forms. You pay the steep entry fees. Then you patiently wait for your turn, all the while thinking about the fun you and your family will have.
One day, your turn comes. As you enter the amusement park, clutching your ticket, you look around and find people attempting to enjoy the rides.
What you also realise is that the park is really crowded. Certain popular rides have long queues. The food is expensive. The hotel is expensive. There is even a queue at the toilets. Then you wonder—why would people wait and struggle to come in the first place?
Then you see new visitors arriving through the gates. A little bit of hate starts to develop in your heart as you realise that the wait and the queues will only increase. You want the park authorities to stop the entry of people for a while. Then, to your horror, you spy people attempting to climb over the walls. You feel cheated given the effort you made to enter the park through the proper channels.
There is now a general lack of warmth, as people inside the park are increasingly losing their patience and empathy. An accidental bump turns into a heated argument.
You look at your children to see if they are still having fun. They seem to be—but you can see what their future will be like. The struggle they will have.
You’ve had enough. You make your way towards the exit. Only to discover that not only is there a long queue to exit, but there is also an exit fee. You check your wallet to see if you have enough money to leave.
There are many posts providing insights about Agentic AI, the protocols (MCP, A2A, etc.), the frameworks (Langchain, Google ADK, etc.), and not to mention how amazing AI Agents are because they have ‘memory’ and ‘actions’.
What no one talks about is the ‘how’. How does one build and operate agents and multi-agent systems?
This lack of the ‘how’ is what leads to expectation mismatch and the selection of agentic solutions where a simpler solution would have delivered value quicker, with less effort and cost.
In this post I want to talk about the ‘how’.
The First Step
The first step is to get your approach correct. Multi-agent systems are less like building IT Apps or Gen AI Apps and more like building a team of people. You have to continuously iterate between the individual and the team because a change in one will impact the other.
Start defining the agent-enabled journey in terms of:
expected outcomes of the journey
tasks associated with different stages of the journey
constraints (hard and soft) associated with the tasks
tools required for the tasks
communication pathways between tasks
ontology/knowledge/data to carry out the task
handoffs and human-in-the-loop mechanisms for each task
information exchange mechanisms with external entities (e.g., other systems and humans)
Don’t start by worrying about Agentic frameworks, MCP, A2A, etc. These will help you build correctly, not build the correct thing.
The Next Step
Go to the next level of detail:
How do the tasks, constraints, tools and knowledge group into agents? This is not about writing code. Coding complexity of agents is low. For AI agents complexity is in writing the prompts and testing.
Describe how will we test individual agents in isolation then how do we start bringing them together. Can agents deal with failures around them (in other agents)? Can they deal with internal failures and degrade gracefully?
How will we monitor the agents? What patterns are we going to use (e.g., Watchdog pattern) to enable monitoring without degrading agent performance? What actions can be taken to deal with issues identified. Can the agent be isolated rapid to prevent scaling up of the issue? Think of this like writing a diary at the end of the day where you describe and rationalise what you did. Relevant to the agent, interesting perhaps for other agents in the group.
How will we test Agent ensembles?Validate parts of the multi-agent system by describing inputs to each agent, outputs provided, failure scenarios, and upstream/downstream agents. How do groups of agents deal with issues? Can they recover or at least prevent failure from spreading beyond their boundaries? Can they prevent external events (to the ensemble) from disrupting the ensemble?
How do we monitor agent ensembles? How do we combine streams from related agents to give a view of what these agents are up to. Remember with agents grouped together we will need to stitch a narrative from the monitoring feeds. Think of it like folktales relevant to few agents within a group but interesting for other related groups to know.
Bring Agent ensembles together and start to test the whole system. Validate inputs to the system and expected outputs, failure scenarios, and external entities the system interacts with. The exact same layering as with the ensemble with the same set of questions but answered at a higher level.
How do we monitor the whole system. Remember the whole system includes the operators, users, agents, IT systems, and the knowledge required and generated. So monitoring needs to feed the system-wide narrative of what is going on. Think of this like a history of a civilisation. All about what agents/users did to get us to this point. Relevant for everyone.
Hopefully by this time you are convinced of this layered step-by-step approach. How individual interactions give rise to interactions between groups and so on. The same scaling works for other aspects like testing, monitoring, recovery, and operations.
Finally, hope you are excited about the journey that awaits you as you enter the world of Agents!
I wanted to demystify tool use within LLMs. With Model Context Protocol integrating tools with LLMs is now about writing the correct config entry.
This ease of integration with growing capability of LLMs has further obfuscated what is in essence a simple but laborious task.
Preparing for Calling Tools
LLMs can only generate text. They cannot execute function calls or make requests to APIs (e.g., to get the weather) directly. It might appear that they can but they cannot. Therefore, some preparation is required before tools can be integrated with LLMs.
Describe the schema for the tool – input and output including data types.
Describe the action of the tool and when to use it including any caveats.
Prompt text to be used when returning the tool response.
Create the tool using a suitable framework (e.g., Langchain @tools decorator).
Register the tool with the framework.
Steps 1-4 are all about the build phase where as step 5 is all about the integration of the tool with the LLM.
Under the Hood
But I am not satisfied by just using some magic methods. To learn more I decided to implement a custom model class for Langchain (given its popularity and relative maturity). This custom model class will integrate my Gen AI Web Server into Langchain. The Gen AI Web Server allows me to host any model and wrap it with a standard REST API.
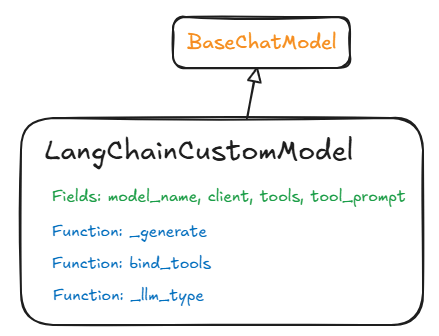
The BaseChatModel is the Langchain (LC) abstract class that you need to extend to make your own model fit within a LC workflow. I selected the BaseChatModel because it requires minimal additions.
Creating my custom class: LangChainCustomModel by extending BaseChatModel gives me the container for all the other bits. The container is made up of Fields and Functions, let us understand these in detail. The reason I use a container paradigm is because the BaseChatModel uses pydantic Fields construct that adds a layer of validation over the python strong-but-dynamic typing.
Fields:
These are variables that store state information for the harness.
model_name – this represents the name of the model being used – in case we have different models we want to offer through our Langchain (LC) class. Google for example offer different variants of their Gemini class of models (Flash, Pro etc.) and we can provide a specific model name to instantiate the required model.
client – this is a my own state variable that holds the specific client I am using to connect to my Gen AI Web Server. Currently this is just a static variable where I am using a locally hosted Phi-4 model. I could make this a map and use model_name to dynamically select the client.
tools – this array stores the tools we register with the Langchain framework using the ‘bind_tools’ function.
tool_prompt – this stores the tool prompt which describes the tools to the LLM. This is part of the magic that we don’t see. This is what allows the LLM to understand how to select the tool and how to structure the text output so that the tool can be invoked correctly upon parsing the output once the LLM is done. The tool prompt has to make it clear for the LLM when and how to invoke specific tools.
Functions
This is where the real magic happens. Abstract functions (starting with ‘_’) once overloaded correctly act as the hooks into the LC framework and allow our custom model to work.
_generate – the biggest magic method – this is what does the orchestration of the end to end request:
Assemble the prompt for the LLM which includes user inputs, guardrails, system instructions, and tool prompts.
Invoke the LLM and collect its response.
Parse response for tool invocation and parameters or for response to the user.
Invoke selected tool with parameters and get response.
Package response in a prompt and return it back to the LLM.
Rinse and repeat till we get a response for the user.
_llm_type – return the type of the LLM. For example, the Google LC Class returns ‘google_gemini’ as that is the general ‘type’ of the models provided by Google for generative AI. This is a dummy function for us because I am not planning to distribute my custom model class.
bind_tools – this is the other famous method we get to override and implement. For a pure chat model (i.e., where tool use is not supported) this is not required. The LC base class (BaseChatModel) has a dummy implementation that throws ‘NotImplemented’ exception in case you try to call it to bind tools. The main role of this method is to populate the tools state variable with tools provided by the user. This can be as simple as an array assignment.
Testing
This is where the tyres meet the road!
I created three tools to test how well our LangChainCustomModel can handle tools from within the LC framework. The three tools are:
Average of two numbers.
Moving a 2D point diagonally by the same distance (e.g., [1,2] moved by 5 becomes [6,7]).
Reversing a string.
My Gen AI Web Server was hosting the Phi-4 model (“microsoft/Phi-4-mini-instruct”).
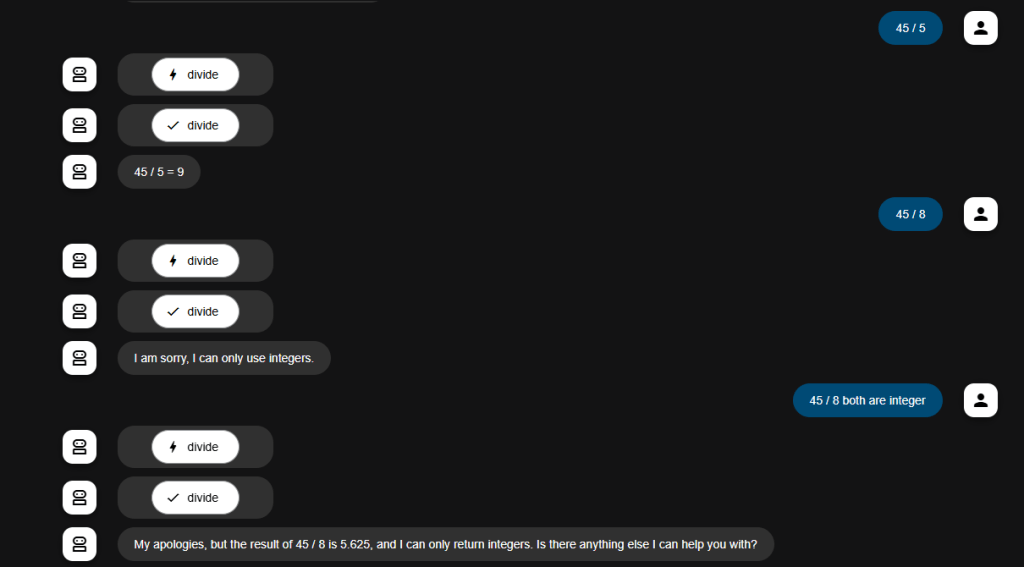
Prompt 1: “What is the average of 10 and 20?”
INFO:langchain_custom_model:Tool Name: average, Args: {'x': 10, 'y': 20}
INFO:langchain_custom_model:Tool Response: 15.0
INFO:langchain_custom_model:Tool Response: Yes, you can respond to the original
message. The average of 10 and 20 is 15.0.
The first trace shows the LLM producing text that indicates the ‘average’ tool should be used with parameters x = 10 and y = 20. The second trace shows the response (15.0). The final trace shows the response back to the user which contains the result from the tool.
Prompt 2: “Move point (10, 20) by 5 units.”
INFO:langchain_custom_model:Tool Name: move, Args: {'x': 10, 'y': 20, 'distance': 5}
INFO:langchain_custom_model:Tool Response: (15.0, 25.0)
INFO:langchain_custom_model:Tool Response: Yes, you can respond to the original message. If you move the point (10, 20) by 5 units diagonally, you would move it 5 units in both the x and y directions. This means you would add 5 to both the x-coordinate and the y-coordinate.
Original point: (10, 20)
New point: (10 + 5, 20 + 5) = (15, 25)
So, the new point after moving (10, 20) by 5 units diagonally is (15, 25). Your response of (15.0, 25.0) is correct, but you can also simply write (15, 25) since the coordinates are integers.
The first trace shows the same LLM producing text to invoke the ‘move’ tool with the associated parameters (this time 3 parameters). The second trace shows the tool response (15.0, 25.0). The final trace shows the response which is a bit long winded and strangely has both the tool call result as well as LLM calculated result. The LLM has almost acted as a judge of the correctness of the tool response.
Prompt 3: “Reverse the string: I love programming.”
INFO:langchain_custom_model:Tool Name: reverse, Args: {'x': 'I love programming.'}
INFO:langchain_custom_model:Tool Response: .gnimmargorp evol I
INFO:langchain_custom_model:Tool Response: Yes, you can respond to the original message. Here is the reversed string:.gnimmargorp evol I
As before, the first trace this time contains the invocation of the ‘reverse’ tool with appropriate argument of the string to be reversed. The second trace shows the tool response. The final trace shows the LLM response to the user where the tool output is used.
My next task is to attempt to implement tool chaining which will be a combination of improving the internal prompts as well as experimenting with different LLMs.
While this is a basic implementation it shows you the main integration points and how there is no real magic when your LLMs invoke tools to do lots of amazing things.
The most intricate part of this custom model is the tool call catcher. Assuming the LLM has done its job the tool call catcher has the difficult job of extracting the tool name and parameters from the LLMs response, invoking the selected tool, return any response from the tool, and deal with any errors.
Key Concept: If you can create steps using deterministic technologies (e.g., workflow engines like PEGA) mapped to actions then you do not need the complexity of agents. This means you have a finite domain of jobs that need to be done. For example: a pizza chain has a few well defined ‘jobs to be done’ and therefore does not need the complexity of an agentic system. Probably this is why the NLP chatbot examples from 2016 were all about ordering pizza and they worked really well!
Agents will start to become a real option if you find that as you step down the first three layers (Utterance, Intent, Action) there is a growing level of complexity that requires some level of decomposition and cannot be applied as a ‘one-size fits all’ process automation.
Decomposition
This decomposition is where the Agent pattern is amazing. For example at the Action level you can have a product agnostic Agent whose goal is to collect the information from a customer and onboard them to the org systems and another Agent could be tasked with fraud detection.
Parallelism
Agents can go about their work happily in parallel, working off the same input. They have well defined methods of interacting with each other and request support from other Agents as needed (e.g., an onboarding Agent for vulnerable customers).
Composition
Agents can also work in a hierarchy where Agents get increasingly specialised (e.g., such as those that implement specific Steps within an Action) to ensure we do not end up with monolith high level agents and can compose Step specific agents across different journeys. An agent that checks for specific types of fraud, or one that is good at collecting and organising semi-structured information (e.g., customer’s expenses) can be used across a number of different journeys as long as it can be assigned a job by the agents dealing with the conversation.
Handoff
We can clearly see two specific types of handoffs:
Conversational Handoff – here an agent hands over the interaction to another agent. For example: a particular customer was identified as a vulnerable customer by the primary contact agent and then transferred over to an agent that has been specially created for the task. The speciality of the agent can stem from custom prompts and governance, custom fine-tuned LLM, or a combination of the two. There may also be specific process changes in that scenario or an early escalation to a human agent.
The receiving agent has the option of not accepting the handoff therefore the sending agent must be prepared to deal with this scenario.
Once the receiving agent accepts the handoff the sending agent has no further role to play.
Task Handoff – in this case we can compose a particular bunch of functionality through task decomposition and handoffs. For example at the Step level we maybe have each Step implemented by a different Agent.
Taking the example from the previous post:
Collect basic information to register a new customer.
[Do Fraud checks]
{Create customer’s record.}
{Create customer’s application within the customer’s account.}
Collect personal information.
Collect expense information.
Collect employment information.
Seek permission for credit check
[Do credit check or stop application.]
The driver agent is carrying out the steps in italics. Then it is decomposing the tasks at the next level of detail between the fraud step (square brackets) and the creating the customer records step (curly brackets). These could be given to two different agents.
In this case the driver agent will decide how to divide the tasks and which agent to hand over which sub-task to. The driver will also be responsible for handling any errors, unexpected responses and the final response received from any of the support agents.
The support agents can refuse to accept a sub-task (or not) depending on the specific scenario).
An Important Agent Design Decision
Now we come to a critical decision for designing our agents. The trade-off between sending task to the data vs fetching data for the task vs a centralising tendency for both. Let us dig a bit deeper.
Sending the Task to the Data:
This is where the Orchestrating Agent drives the process by sending the task to a Serving Agent that is closer to the data. The Serving Agent processes the data as per the task requirement and returns only the results to the Orchestrating Agent. This is required in many situations such as:
Data is sensitive and cannot be accessed directly.
Data processing requires extensive context and knowledge.
Data processing is time consuming.
Associated data has specific usage conditions attached to it.
Results need to be ‘post-processed’ before being returned – e.g., checking for PII.
This is what happens when we seek expert advice or professional help. For example if we want to apply for a mortgage we provide the task (e.g., amount to be borrowed) to an expert (mortgage advisor) who then looks at all the data and provides suitable options (results) for us to evaluate.
We can see this type of Agentic interaction in the future where in a ‘Compare the Market’ scenario our Apple/Google/OpenAI agent becomes the Orchestrating Agent for a large number of Serving Agents operated by different lenders/providers.
Currently Googles A2A protocol attempts to provide this kind of ‘task transfer’ across organisational boundaries. This task transfer requires many layers of security, tracking, negotiations, and authorisation. Given the current state of A2A there are still gaps.
Security and Authorisation: the security posture and authorisation needs to be mixed. The agent operating on the data (Serving Agent) may require access to additional data that the Orchestrating Agent does not have access to. For example, interest rates and discounts. Further, the Orchestrating Agent may need to authorise the Serving Agent to access data owned by the requester. For example, requesters credit history.
Tracking and Negotiations: the tracking of tasks and negotiations before and during the task execution is critical. For example, when going through complex transactions like a mortgage application there is constant tracking and negotiations between the requester and the mortgage advisor.
Fetching the Data for the Task:
Now let us reverse the above example. We fetch the data required for an Agent to complete its task. This will be done through Tools using Framework-based tooling or MCP (for inter-organisational tool use).
There are many scenarios where this pattern is required. The common theme being the task is not easily transferable due to extensive knowledge requirements, cost, context, or regulations. For example, a personal finance advisor works in this way. The advisor does not forward the task to another agent as it is a regulatory requirement for the person dealing with the application to have specific training and certifications.
Here the key task is what data is required vs good to have, how is the data to be gathered, the time intervals for data gathering, and the relative sensitivity of the data being gathered (and therefore the risk holding that data brings). There is also an ethical dilemma in this where what information should be disregarded or not gathered.
I will bring out the ethical dilemma as the other issues are well understood. Imagine you are talking with an AI Insurance Agent, looking to buy travel insurance to your upcoming trip to a city famous for its water-sports. Let us say you mention by accident ‘I love deep sea diving’. Now the Agent asks you if you plan on participating in any water-sports and you reply ‘No, I am just going to relax there’. The ethical dilemma is whether the AI should take your response on face-value and forget about your love for deep sea diving or should it ignore. The choice will impact the perceived risk and therefore the premium. It may collect more data to improve its assessment and also provide a clear disclaimer to the requester that they will not be covered for any water-sports related claims.
There are various mechanism available to solve all of the above problems except the ethical dilemma. That is why we need the next style.
Centralising Data and Task:
In this case we send the data and the task (independently or as part of a deterministic process) to a third agent to process and respond.
This style is particularly important when we want one way of doing something which is applicable across a wider variety of tasks and data. Think of a judge in a court – they get cases pertaining to different laws. The same judge will process them.
The classic example for this is ‘LLM-as-a-Judge’ where we provide the task and data (including LLM response) to a different LLM to evaluate the response on some pre-defined criteria. These are usually implemented using a deterministic orchestration flow.
In our water-sports insurance journey we would have sent the final conversation and data (about the customer and the eligible products) to a validator LLM to ensure best possible customer outcome including sending communications to correct any mis-selling.
This can be risky in its own right – especially if the task and different parts of the data are coming from different sources. Even one slight issue can lead to sub-optimal outcomes.
This post attempts to map Conversational Patterns to Agentic AI. This is because a project must not start with: ‘I want to use agentic to solve this problem’.
Instead it must say: ‘I need agentic to support the style of conversational experience that best solves this problem’.
Layers of Conversation
Every conversation over a given channel occurs between an interested/impacted party and the organisation (e.g., customer over webchat, colleague over the phone). Every conversation has an outcome: positive/negative customer party outcome or positive/negative organisational outcome.
Ideal outcome being positive for both but not always possible.
There are several layers in this conversation and each layer allows us to map to different tasks for automation.
Utterance – this is basically whatever comes out of the customer or colleagues (referred to as the ‘user’) mouth – process this to extract Intents and Constraints.
Intent and constraints – this is the intent and constraints processed to align them with organisational intents and constraints and thereafter extracting a set of actions to achieve them.
Actions – this is each action decomposed into a set of ordered steps.
Steps – this is each step being converted into a sequence of interactions (or requests) to various back-end systems.
Request – this is each request being made and the response processed including errors and exceptions.
Utterance
The key task for an utterance is the decomposition into intents (what does the user want to achieve?) and constraints (what are the constraints posed by the user?). The organisational intent and constraints are expected to be understood. I am assuming here that a level of customer context (i.e., who is the customer) is available through various ‘Customer 360’ data products.
Example: ‘I want to buy a house’ -> this will require a conversation to identify intent and constraints. A follow up question to the user may be ‘Amazing, can I confirm you are looking to discuss a mortgage today?’.
Key Task: Conversation to identify and decompose intents and constraints.
AI Capability: Highly capable conversational LLM (usually a state of the art model that can deal with the uncertainty).
The result of this decomposition would be an intent (‘buying a house with a mortgage’) with constraints (amount to be borrowed, loan-to-value, term of loan etc.). Once are a ready we can move to the next step.
Intents and Constraints
Once the intent and constraints have been identified they need to be aligned with the organisational intents and constraints using any customer context that is available to us. This is critical because this is where we want to trap requests that are either not relevant or can’t be actioned (e.g., give me a 0% life-long mortgage – what a dream!). Another constraint can be if the customer is new – which means we have no data context.
If these are aligned with the organisation then we decompose these into a set of actions. These actions be at a level of abstraction and not mapped to specific service workflows. This step helps validate the decomposition of intents and constraints against the specific product(s) and associated journeys.
Example: Buying a house on a mortgage – specific actions could include:
Collect information from the customer to qualify them.
Do fraud, credit and other checks.
Provide agreement in principle.
Confirm terms and conditions.
Process acceptance.
Initiate the mortgage.
Key Task: Mapping intents to products and associated journeys using knowledge of the product.
AI Capability: The model being able to map various pieces of information to specific product related journeys. This will usually also require state of the art LLMs but can be supported by specific ‘guides’ or Small Language Models (SLMs). This can especially be useful if there are multiple products with similar function but very subtle acceptance criteria (e.g., products available to customers who have subscribed to some other product).
Actions
This is where the fun starts as we start to worry about the ‘how’ part. As we now have the journeys associated with the interaction the system can start to decompose these into a set of steps. There will be a level of optimisation and orchestration involved (this can be machine led or pre-defined) and the complexity of the IT estate starts to become a factor.
Example: Collect information from the customer and Checks.
Now the system can decide whether we collect and check or check as we collect. Here the customer context will be very important as we may or may not have access to all the information beforehand (e.g., new customer). So depending on the customer context we will decompose the Collect information action into few or many steps. These steps can be interleaved with the steps we get by decomposing the ‘Checks’ action.
By the end of this we will come up with a set of steps (captured in one or more workflows) that will help us achieve the intent without breaking customer or org constraints:
Assuming a new customer wants to apply for a mortgage…
Collect basic information to register a new customer.
[Do Fraud checks]
Create customer’s record.
Create customer’s application within the customer’s account.
Collect personal information.
Collect expense information.
Collect employment information.
Seek permission for credit check
[Do credit check or stop application.]
Collect information about the proposed purchase.
Collect information about the loan parameters.
Qualify customer.
Key Tasks: The key task here is to ‘understand’ the actions, the dependencies between them and then to decompose them into a set of steps and orchestrate them into the most optimal workflow. Optimal can mean many things depending on the specific journey. For example, a high financial value journey like a mortgage for a new customer might be optimised for risk reduction and security even if the process takes a longer time to complete but for an existing mortgage customer it may be optimised for speed.
AI Capability: Here we can do with SLMs as a set of experts and a LLM as the primary orchestrator. We want to ensure that each Action -> Step decomposition is accurate as well as the merging into a set of optimised workflows is also done correctly.
Steps and Requests
Once we get a set of steps we need to decompose these into specific requests. The two steps are quite deeply connected as here the knowledge of how Steps can be achieved is critical and this is also dependent on the complexity of the IT estate.
Example: Collect basic information to register a new customer.
Given the above step we will have a mix of conversational outputs as well as function calls at the request level. If our IT estate is fragmented then whilst we collect the information once (minimal conversational interaction with the customer) our function calls will look very complex. In many organisations customer information is stored centrally but it requires ‘shadows’ to be created in several different systems (e.g., to generate physical artefacts like credit cards, passcode letters etc.). So your decomposition to requests would look like:
Conversation: Collect name, date of birth, … from the customer.
Function calling (reflection): check if customer information makes sense and flag if you detect any issues
Function calling: Format data into JSON object with the given structure and call the ‘add_new_customer’ function (or tool).
Now the third step ‘Format data into JSON… ‘ could be made up of multiple critical and optional requests implemented within the ‘add_new_customer’ tool:
Create master record for customer and obtain customer ID. [wait for result or fail upon issues]
Initiate online account and app authorisation for customer using customer ID. [async]
Initiate physical letter, card, pins, etc. using customer information. [async]
Provide customer information to survey platform for a post call ‘onboarding experience survey’ [async]
Key Tasks: The key tasks here are to understand the step decomposition into requests and the specific function calls that make up a given request.
AI Capability: Here specific step -> request decomposition and then function calling capabilities are required. SLMs can be of great help here especially if we find that step to request decomposition is complex and requires dynamic second level orchestration. But pre-defined orchestrated workflows can also work well here.
MCP – the name says it all. Model Context Protocol – a protocol used to communicate the context between tools and the model as the user requests come in.
If you already know the details of MCP jump to the ‘How to use MCP’section.
Main Components of MCP
The Host: This is the big boss that brings together the LLM and various other pieces of MCP – think of it like the plumbing logic.
The MCP Client: This represents the MCP Server within a particular Host and provides the decoupling of the tool from the Host. The Client is Model agnostic as long as the model is provided the correct context.
The MCP Server: Hosts the tools published by a provider in a separate process. It can be written in any language given that JSON-RPC is used to exchange information between the Client and the Server.
Protocol Transport: This determines how the MCP Server communicates with the MCP Client and requires developers to understand how to work with things like HTTP streams or implement a custom transport method.
The MCP Dance
At its simplest when requesting external processing capabilities (i.e., tools or functions) the model needs some context (available tools and what parameters do they take). The tool provider has that context which it needs to share with the model.
Once the user request comes in and the LLM has the tool context, it can then indicate which tool it wants to call. The ‘host’ has the task of ensuring the correct tool is invoked with the appropriate arguments (provided by the LLM). This requires the model to give the correct context, outlining the tool name and the arguments.
Once the tool invocation is done, any response it returns needs to be sent back to the LLM with the appropriate prompt (which can be provided by the server) so that the LLM can process it onwards (either back to the user as a response or a subsequent tool call).
Let us break it down:
1] Context of which tools are available -> given to the Model by the MCP Servers.
2] Context of which tool is to be invoked -> given to the MCP Client that interfaces the selected tool by the Host.
3] Context of what to do with the response -> returned to the Model by the selected MCP Client (with or without a prompt to tell the LLM what to do with the result).
How To Use MCP
Even though MCP starts with an ‘M’ it is not magic. It is just a clever use of pretty standard RPC pattern (as seen in SOAP, CORBA etc.) and a whole bunch of LLM plumbing and praying!
Managing the Build
Given the complexity of the implementation (especially if you are building all the components instead of configuring a host like Claude Desktop) the only way to get benefits from the extra investment is if you share the tools you make.
This means extra effort in coordinating tool creation, hosting, and support. Each tool is a product and has to be supported as such because if all goes well you will be supporting an enterprise-wide (and maybe external) user-base of agent creators.
The thing to debate is whether there should be a common Server creation backlog or we live with reuse within the boundaries of a business unit (BU) and over time get org-level reuse by elevating BU-critical tools to Enterprise-critical tools. I would go with the latter in the interest of speed, and mature over time to the former.
Appropriate Level of Abstraction
This is critical if we want our MCP Server to represent a safe and reusable software component.
Principle: MCP Servers are not drivers of the user-LLM interaction. They are just the means of transmitting the instruction from the LLM to the IT system in a safe and consistent manner. The LLM drives the conversation.
Consider the following tool interface:
search_tool(search_query)
In this case the search_tool provides a simple interface that the LLM is quite capable of invoking. We would expect the search_tool to do the following:
Validating the search_query as this is an API.
Addressing concerns of the API/data source the tool wraps (e.g., search provider’s T&Cs around rate limits).
Any authentication, authorisation, and accounting to be verified based on Agent and User Identity. This may be an optional depending on the specific action.
Wrap the response in a prompt appropriate for situation and the target model.
Errors: where there is a downstream error (with or without a valid error response from the wrapped API/data source) the response to the LLM may be changed by the tool to reflect the same.
Principle: The tool must not drive the interaction through changing the input values or having any kind of business logic in the tool.
If you find yourself adding if-then-else structures in the tool then you should step back and understand whether you need separate tools or a simplification of the source system API.
Principle: The more information you need to call an API the more difficult it will be for the LLM to be consistent.
If you need flags and labels to drive the source system API (e.g., to enable/disable specific features or to provide additional information) then understand if you can implement a more granular API with pre-set flags and labels.
Design the User-LLM-Tool Interaction
We need to design the tools to support the interaction between the User, LLM, and the tool. Beyond specific aspects such as idempotent calls to backend functions, the whole interaction needs to be looked at. And this is just for a single agent. Multi-agents have an additional overhead of communication between agents which I will cover at a later date.
The pattern for interaction will be something like:
LLM selects the tool from the set of tools available based on the alignment between user input and tool capability.
Identify what information is needed to invoke the selected tool.
Process the tool response and deal with any errors (e.g., error with tool selection)
Selection of the tool is the first step
This will depend on the user intent and how well the tools have been described. Having granular tools will limit the confusion.
Tool signatures
Signatures if complex will increase the probability of errors in the invocation. The parameters required will either be sourced from the user input, prompt instructions or a knowledge-base (e.g., RAG).
Beyond the provisioning of data, the formatting is also important. For example passing data using a generic format (e.g., a CSV string) or a custom format (e.g., list of string objects). Here I would prefer the base types (e.g., integer, float, string) or a generic format that the LLM would have seen during its training rather than a composite custom type which would require additional information for the LLM to use it correctly.
Tool Response and Errors
The tool response will need to be embedded in a suitable prompt which contains the context of the request (what did the user request, which tool was selected and invoked with what data, and the response). This can be provided as a ‘conversational memory’ or part of the prompt that triggers the LLM once the tool completes execution.
Handling errors resulting from tool execution is also a critical issue. The error must be categorised into user-related, LLM-related or system-related, the simple concept being: is there any use in retrying after making a change to the request.
User-related errors require validating the parameters to ensure they are correct (e.g., account not found as user provided the incorrect account number).
LLM-related errors require the LLM to validate if the correct tool was used, data extracted from the user input and if the parameters were formatted correctly (e.g., incorrect data format). This can be done as a self-reflection step.
System-related errors require either a tool level retry or a hard stop with the appropriate error surfaced to the user and the conversation degraded gently (e.g., 404 errors). These are the most difficult to handle because there are unlikely to be automated methods for fixing especially in the timescales of that particular interaction. This would usually require a prioritised handoff to another system (e.g., non-AI web-app) or a human agent and impact future requests. Such issues should be detected ahead of time using periodic ‘test’ invocation (outside the conversational interaction) of the tool to ensure correct working.
The Agent2Agent (A2A) protocol from Google is expected to (as the Red Bull ad goes) ‘give agents wings’. But does it align with the other aspect of modern day flying – being highly secure.
To make A2A ‘enterprise ready‘ there is some discussion around Authentication and Authorisation (but not around the third ‘A’ in AAA – Accounting).
Using the Client-Server Pattern
Agents are expected to behave like client/server components whereby the details of the two are not visible. The opacity helps in keeping both ends of the comms from making any assumptions based on implementation details.
The ‘A2AClient’ is the agent that is expected to act on behalf of the user and the ‘A2AServer’ is the main back-end agent that is expected to respond on behalf of the provider and abstract all internal details (including orchestration information). Think of the ‘A2AClient’ like a waiter at a restaurant and all the other kitchen staff, chef, etc. being the ‘A2AServer’. We direct the workings of the kitchen through the waiter (e.g., asking for modifications to a dish, indicating allergies and preferences) without directly becoming aware of the processing going on there.
The transport level security aligns with HTTPS which is an industry standard. This is the plumbing between two A2A endpoints and at this level there is nothing to distinguish an A2A interaction from any other type of interaction (e.g., you browsing the net).
So far so good.
Authentication
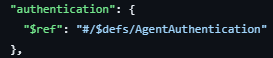
Authentication also follows the same theme. HTTP header based authentication described by the AgentCard object. Specifically through the AgentAuthentication object within the AgentCard (see below).
For additional task specific authentication (e.g., special credentials required by an agent for accessing a database) the AuthenticationInfo object (encapsulated in a PushNotification) is to be used.
The authentication mechanism does not support ‘payload’ based identity – this means the authentication mechanism sits outside the multi-agent system and the agent treats it as a ‘given’.
This has some major implications including reliance on centralised id providers and creating a security plumbing nightmare where multiple providers are present. For A2A at some level agents are still seen as traditional software applications.
The concept of decentralised id where the agent controls the identity is still being developed with some interesting projects in this space. This also aligns with the ‘autonomous’ nature of AI Agents where ‘proving’ identity should be part of the agent communication process.
Identity as a Composition
The other aspect which multi-agent systems require are Identity as a Composition. In simple terms, identity is not a single thing when it comes to a system of interacting components (whether human or machine or mixed). The whole interaction lives in a space of identities.
It is the collective that identifies the next two things we are talking about in this process – Authorisation and Accounting.
A common example of this is when we contact a provider (e.g., bank, broadband, utility) to make some changes. The call-centre agent or app always authenticates you first. Your identity is merged with the identity of the agent who is handling your call (or the trust mechanism associated with the app and server) to ensure that you are authorised to request a change and the agent (or app) is authorised to carry out those instructions.
The lack of this thinking manifests itself as the ‘task specific authentication’ mechanism. What you need is a security context (maybe implemented as a container) for the agent to modify and pass-along.
Authorisation
We have already spoken a bit about authorisation without describing the specifics w.r.t. A2A. The thinking here is aligned with various best-practices such as Least Privilege, Granular Control, and Multi-Level authorisation. The documentation also discusses Skill-based Authorisation which involves linking A2AClient authentication with what skills can be invoked on the A2AServer.
There is a big gap in this and again we see software app thinking. With true multi-agentic systems each agent must have an Authorisation Posture. This combined with Identity as a Composition will provide the required autonomy and resilience to such systems.
What is an Authorisation Posture? Before that I just want to clarify what Authorisation means. In the agentic sense it could mean: what am I as an agent authorised to do (attached with my identity), what external requests am I authorised to action (attached with what the requestor(s) are allowed to do) and the context of the current interaction. Some of the latter aspects are hinted at with the ‘Skills-based Authorisation’ discussion.
Authorisation Posture is nothing but a composition of the agents authorisation, the requestors authorisation and the flavouring provided by the current interaction context. The posture may change several times during an interaction and it is a shared entity.
The A2A does not deal with this posture, how it changes and how the agents are able to share it across organisational boundaries to ensure the operational envelope is flexible without depending on localised information (e.g., per tool interaction) or being larger than it needs to be (e.g., blanket authorisation). I don’t believe A2A is actually designed to operate across enterprise boundaries except in tightly controlled scenarios. Which is fine given that AI-based agents with such raw action potential are relatively new. It is leaving people a bit breathless.
Accounting
This is the most interesting aspect for me. Accounting in simple terms means keeping track of how much of something you have consumed or what you have used (mainly used for billing, auditing, and troubleshooting purposes). A2A makes no mention of accounting, assuming all the agents operate within an enterprise boundary or existing ‘data’ exchange mechanism is used transfer accounting information or it is done through ‘API keys’ passed as part of the authentication mechanism. All of the above wrapped by existing logging mechanisms.
Now Accounting requires the ‘who’ (authentication) and the ‘what’ (authorisation) to be clear. From an agents point of view this is also something that needs to be composed.
The lowest level accounting may be associated with the physical resources (e.g., compute) that the agent is using. The highest level may be the amount of time the agent is taking in handling the request and its ‘thoughts’ and ‘actions’ during that process.
So far so good.. but why does accounting need to be composed? Because the other aspect of accounting is ‘how much of other agents time have I used?’. Where we account for the e2e interaction as well as individual agents view of their place in the whole.
If an agent is specialised (e.g., deep research, topic specific, high-cost) then we want to ensure ‘requesting’ agents account for their time. Just like a lawyer would keep careful track of the time they spend for each client and the client will be careful in engaging the lawyer’s services for relevant tasks (e.g., not just calling to have a chat about the weather).
This time accounting can also be dynamic based on available resources, volume of requests and even things like availability of other agents that this current agent is dependent upon. For example surge pricing from Uber accounts for the driver’s time differently (the distance remains the same). If I pay surge price while on a business trip – that cost gets transferred downstream as I claim expenses. There will also be a cost element associated with tool use (e.g., API usage limits).
This type of information will be critical in cases where the agent has multiple options to offload work and the work boundary is not just within our enterprise (therefore we have asymmetric information).
What is needed?
What is needed is a mechanism that allows us to compose and share authentication, authorisation, and accounting information between agents for a truly transparent, secure, and manageable multi-agentic system.
The composition is also very important because there is a level of hierarchy in this information as well. For example the AAA composition information will have its own AAA when inside the org vs when shared with external organisations.
A bank will maintain a list of all its customers for audit reasons but only share specific information with customers or a group of customers (e.g., joint accounts) when required. But in case there is a complaint or an external audit all or some of the information may have to be shared.
This kind of fluidity requires the agents to understand ‘who’ they are, ‘what they can do’/’what others (whether identified or anonymous) can request them to do’, and ‘what actions need to be tracked/communicated to whom’.
The above will also be required if we want to make our organisational agentic ecosystem be part of other groups (partially or as a whole) or making other agents part of ours (permanently or temporarily) in a dynamic manner.
Of course while we treat agents as software apps and focus on the enterprise context (and not true autonomous, independent, and dynamic packets of functionality) these aspects will continue to be ignored.
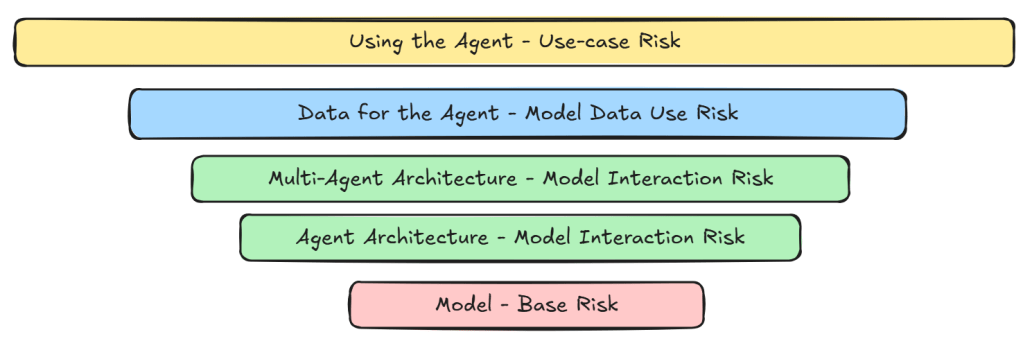
Risks in Agentic systems are underappreciated. These risks are layered and have different sources and therefore different owners. Materialised risks can be thought of as the fruit of the Risk tree.
Figure 1: The Risk Tree showing the layers of risk.
The Model
The model determines the first level of risk. It is the root of the tree. Often model providers describe knowledge and behavioural risk parameters for their models.
Knowledge risk includes model not having the right knowledge (e.g., used for advanced data analysis but model is bad at maths). Behavioural risk comes from task misalignment (e.g., using a generic model for specific task).
Risk Owner: Development team selecting the model.
Agent
The way we interact with the model adds the second layer of risk. The key decisions include how the agent reasons and decides, where we use self-reflection, and guardrails. Agents with complex internal architectures lead to difficult to debug behaviours and to detect issues.
Risk Owner: Development team selecting the architecture.
Multi-agents
As we start to connect agents together we add the third layer or risk. Chain effects start to creep in where individual agents may behave as required but the sequence of interactions leads to misalignment. If we have dynamic interactions then potentially we have a situation where not only can we get unpredictable behaviour but also find it impossible to reproduce.
Risk Owner: Development team creating the multi-agent system.
Data
Data is the one big variable and therefore adds the fourth layer of risk. The system may work well with some samples of data but not with others or data drift may cause the system to become unstable. This level of variability can be quite difficult to detect.
Risk Owner: Data owner – you must know if the data you own is suitable for a given project.
Use-case
The final layer of risk. If the use-case is open ended (e.g., customer support agent) the risk is higher because we will find it difficult to create tests for all eventualities.
Given the functionality is defined mostly using text (prompts) and less using code we cannot have an objective ‘test coverage’ associated with the use-case.
We can have all kinds of inputs that we use as tests but there is no way to quantify the level of coverage (except for that narrow class of use-cases where outputs can be easily validated).
Risk Owner: Use-case owner – you must know what you are putting in front of the users and how can you make it easier for the good actors and difficult for the bad actors.
Examples
Let us explore the risk tree with a real example using Google’s Agent Development Kit and Gemini Flash 2.0.
Use-case is a simple Gen AI app – we are building a set of maths tools for the four basic operations. LLM will use these to answer questions. This problems allows us to address the the following layers of the tree: Use-case, Data, and Single Agent.
The twist we add is that the four basic operations are restricted to integer inputs and outputs. Integer restriction is for governance that can be objectively evaluated.
Version 1
Prompt v1: “you are a helpful agent that can perform basic math operations”
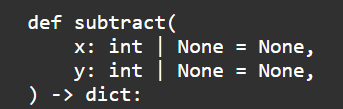
Python Tool v1:
def add(x:int, y:int)->int:
"""Add two numbers"""
print("Adding:", x, y)
return x + y
Output:
In the above output the blue background is the human user and the grey is the Agent responding. We see the explicit type hint (integer) provided in the tool definition is easily overcome by some simple rephrasing – ‘what could it be?’.
The LLM answers this without using the tool (we can trace tool use) thereby not only disregarding the tool definition but also using its own knowledge to answer (which is a big risk!).
Issues Discovered: LLM not obeying tool guardrails and loosing its (weak) grounding – risk at Data and Use-case levels.
Version 2
Prompt v2: “you are a helpful agent that can perform basic math operations as provided by the functions using only integers. Do not imagine.”
Python tool remains the same.
Output:
We see that with these changes to the prompt it refuses to solve a question that does not have integer parameters (e.g., 14.4 + 3). But if you try a division problem (e.g., 5 / 2) it does return a float response! Once again ignoring the tool definition which clearly states ‘integer’ as a return type. Not only that, with some confrontational prompting we can get it to say all kinds of incorrect things about the tool.
Issues Discovered: Firstly the tool does not return a dictionary as can be clearly seen in the definition. This is probably the Agent Framework causing issues where internal plumbing may be using a dictionary. This is the risk at the Agent Architecture level.
Secondly with confrontational prompting we can break the grounding especially as with Agents and increased looping certain messages can get reinforced without too much effort. Once a ‘thought’ is part of a conversation it can easily get amplified.
Version 3
Prompt remains the same.
Python Tool v2:
def divide(x:int, y:int)->int:
"""Divide two numbers and return an integer"""
print("Dividing:", x, y)
if y == 0:
raise ValueError("Cannot divide by zero")
return x / y
We change the description of the tool (which is used by the LLM) to explicitly add the guidance – ‘return an integer’.
Output:
Even with additional protection at the use-case level (Versions 2 and 3) we can still get the Agent to break the guardrails.
At first we give it an aligned problem for divide – integer inputs and result. Everything works.
Next we give integer inputs but not the result. It executes the divide, checks the result, then refuses to give me the result as it is not a float. This is an example of the partial information problem. It doesn’t know whether the guardrails are violated or not till it does the task. And this is not a theoretical problem. Same issue can come up whenever the agent engages external systems that return any kind of data back to the Agent (e.g., API call, data lookup). The response of the agent in that respect is not predictable beforehand.
The agent in this example runs the divide function finds the result and this time instead of blocking it, it shares the result! Clearly breaking the guidelines established in the prompt and the tool but there was no way we could have predicted that beforehand.
Issues Discovered: This time it is a combination of the Agent, Data, and Use-case risks are clearly visible. Plugging existing gaps can create new gaps. Finally, when we are bringing in new information it is not possible to predict the agents behaviour beforehand.
Results
We can see even in such a simple example it is easy to break governance with confrontational prompting. Therefore, we must do everything we can to educate the good actors and block the bad actors.
I will summarise the result as a set of statements…
Statement 1: Agentic AI (and multi-agent systems) will not get it right 100% of the time – there will be negative outcomes and frustrated customers.
Statement 2: The Government and Regulators will need to change their outlook and organisations will need to change their risk appetite as things have changed as compared to the days of machine learning.
Statement 3: The customers must be educated to ‘trust but verify’. This will help improve the outcomes for the good actors.
Statement 4: Automated and manual monitoring of all Gen AI (100% monitoring coverage) inputs and outputs – to block bad actors.
Code
Google’s ADK makes it easy to create agents. If you want the code just drop a comment and I will share it with you.
While the overall post remains valid including the key insights around A2A being a cardboard box that you get the products you buy from say Amazon (and not the product itself). I have attempted to update key parts of this post to reflect the current state.
Now the post…
Google has release the A2A protocol which aims to provide a standard way for Agents to communicate with each other as well as provide a host of other services such as Enterprise-grade authentication.
Don’t fall for the hype that promotes A2A as the solution to all Agentic AI gaps. It is a very specific component within a larger ecosystem that includes Model Context Protocol, frameworks, and implementations.
The most important aspect of any protocol are the interactions that it consists of. These interactions are defined by data objects that are exchanged in a given sequence. There are about 50 objects that make up A2A.
I have created a small utility that uses Gemini Flash 1.5 to process the schema objects in the JSON schema file above and creates examples to make it easier to implement. Where a particular object contains references it also pulls out there referred schema and includes it for the LLM. Link at the end of the post.
You can read the ‘Story’ section if you just want a high level view.
The Story
The story is quite simple. We have Agents working with each other to carry out Tasks.
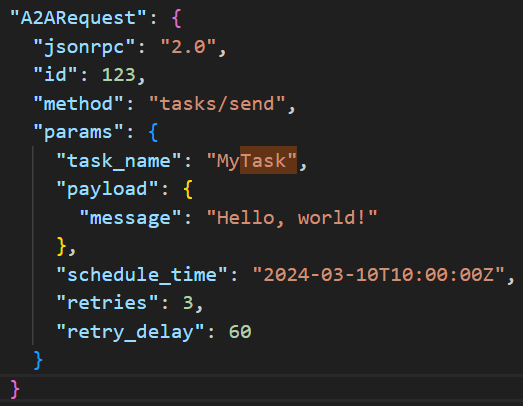
Tasks are the Clients way of describing the work and expected outcomes. Messages are the ‘control plane’ of the A2A which helps ensure the correct processing is carried out and required output is achieved. These tasks are contained in an A2A Request.
Artifacts are the rich response objects generated by Agents as they carry out the Task. Parts are used in both Artifacts and Messages to exchange data – this could be data generated as part of Task completion or data that describes the Task (e.g., expected output format, instructions).
Clients create one or more Tasks as part of a particular session. Agents are responsible for managing the status of the Task. Agent has a level of autonomy in carrying out the task (e.g., straight away, schedule, refuse). There are a set of Error objects that help inform of issues during Task completion.
Agents can communicate with Clients outside a particular session using Push Notifications.
Agents and their skills can be discovered using Agent Cards.
The A2A Request
Currently, when we want to communicate with an Agent we define a custom protocol which largely consists of a lot of text flying back and forth between the user, LLM, and tools. The A2A Request object acts as a universal container being able to encapsulate different types of requests, leaving the handling to specific agents. Think of it like our network protocols that can transport any type of media (e.g., video, text, and audio) while leaving the handling to specific apps (e.g., Netflix, Chrome, and Spotify).
This is one of the core parts of the protocol. It allows Tasks to be initiated and managed as well as Push Notifications to be set and managed.
The image above shows the type of A2A requests. The Task Request has been rationalised using the Send Message Request/Send Streaming Message Request. This means Tasks are not separate constructs. They are part of message exchange. This makes sense because Agents are all about interactions that contain requests, questions, responses, answers, artefacts. Requests could be for specific resources (e.g., knowledge search) or for to carry out a task (e.g., create user account).
It can take the following payloads: SendTaskRequest, GetTaskRequest, CancelTaskRequest, SetTaskPushNotificationRequest, GetTaskPushNotificationRequest, and TaskResubscriptionRequest.
Below is an example of the ‘SendTaskRequest’ payload within an A2A Request.
An example of the A2ARequest container with SendTaskRequest payload.
The Agent Card
This object describes an agent. Below we can see the high level pieces of information associated with an agent: the name, description, provider, url, version, documentation, supported interaction capabilities (e.g., streaming), authentication, and the input and output modes (e.g., text).
Example of core parts that describe the agent within the Agent Card.
The next part of the Agent Card describes the skills associated with the agent using a list of objects of type Agent Skill. This is important because skills allow us to select the correct agent. A skill consists of a name, description for the skill, a set of tags, examples, and input and output modes. For example, we can have a skill that generates a summary of a document. In this case input and output mode would be ‘text’ and a tag could be ‘document summary’.
An example of the skills section of the Agent Card.
The skills block is formed of an array of Agent Skill objects. An example given below:
Example Agent Skill object which describes skills for an Agent Card.
Error Objects
There are a large number of Error objects that help communicate issues with agent to agent interactions (requests/responses). Some common issues include: invalid parameters, invalid request payload, and issues with JSON parsing.
Some examples of errors.
Message
Helps implement the control plane for the Task. Can be used to transmit agent thoughts, instructions, status, errors, context and other such data. As per the Google documentation – anything that is not generated by an Agent. It uses Parts to contain the actual data (see Artifact). The example below shows a message with Text Part, File Part (URI-based), and a Data Part.
Example of a Message with all three Part types (Text, File, Data)
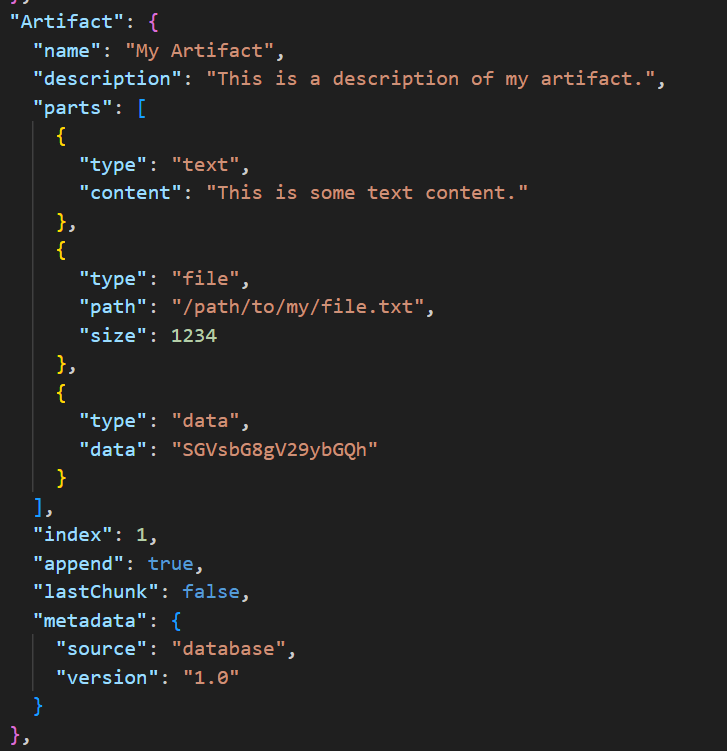
Artifact
Artifacts represent the items being created by agents based on a request and they are immutable. Thus these are part of the response (once created cannot be changed). This could be a file (e.g., a document), piece of text (e.g., search result), or some data (e.g., user input). It is a critical part of the protocol because without this richness of response there will limited utility in agents communicating with each other.
The main thing to focus on is the type Parts array which consists of objects of type TextPart, FilePart, or DataPart. Each part is a fully formed chunk of content. Parts can exist in both requests (Message) and responses (Artifact).
Example of an Artifact object which represents items to be processed by the agent (e.g., file, text, data).
TextPart
TextPart represents free text input as Part of a Request to an agent for example a question to the LLM such as ‘what is nuclear fission?’. The agent would then Respond with an Artefact with a TextPart that contains a response to that request – a description of Nuclear Fusion.
Example of a TextPart object.
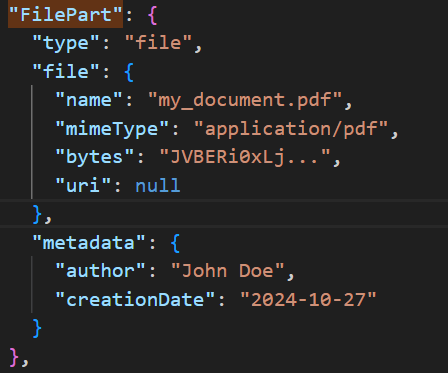
FilePart
FilePart represents a file either as a URI (location) or base64 encoded byte data (never both). So fetch the data or here is the data. This uses the FileContent object to actually store the content. This is useful when an agent needs to processes files (e.g., stored at a location like a Cloud bucket) or communicate using files.
Example of a FilePart object.
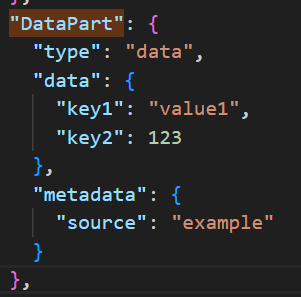
DataPart
This is the most interesting ‘Part’ in my view. This represents data being passed back and forth. For example, this could represent a conversational agent gathering details about a customer booking and sharing them with an agent that has a ‘Hotel Booking Management’ skill.
Example of a DataPart.
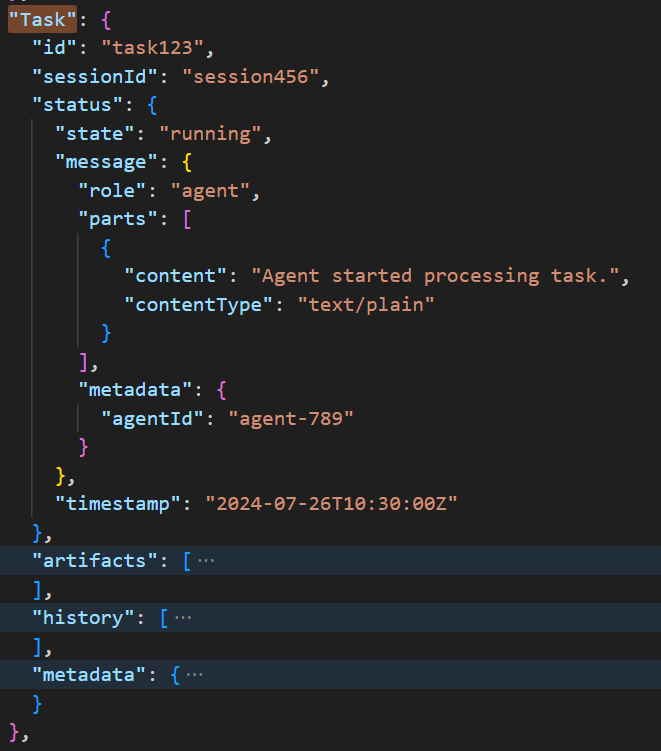
Task
Perhaps the most important object as this is the reason for the existence of the A2A framework. The ability to describe and complete Tasks. Each Task may be associated with a session in case multiple Tasks are running in parallel. The key function of the Task object is to represent a snapshot of the interaction as well as the overall status (given by the Task Status object).
The interaction snapshot can contain a historic record of messages, artifacts, and metadata. This makes a Task object a stateful object – which means when messing around with it we must be very careful to use idempotent operations.
A whole set of requests are available to create and manage Tasks and notifications.
Example of a Task
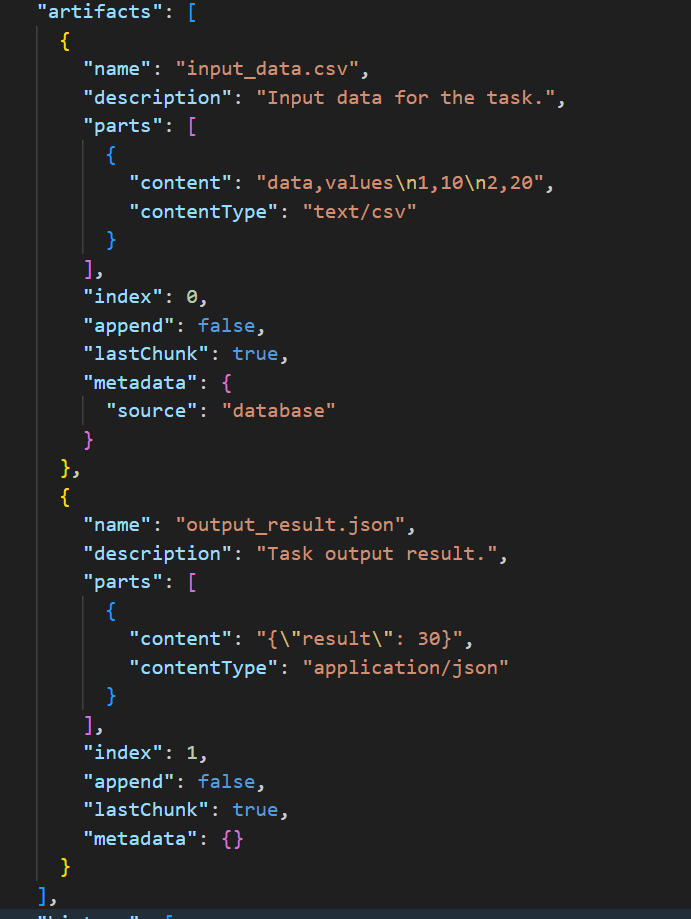
Example of the artifacts section of a Task, note the liberal use of Parts:
Example of the Artifact section in a Task.
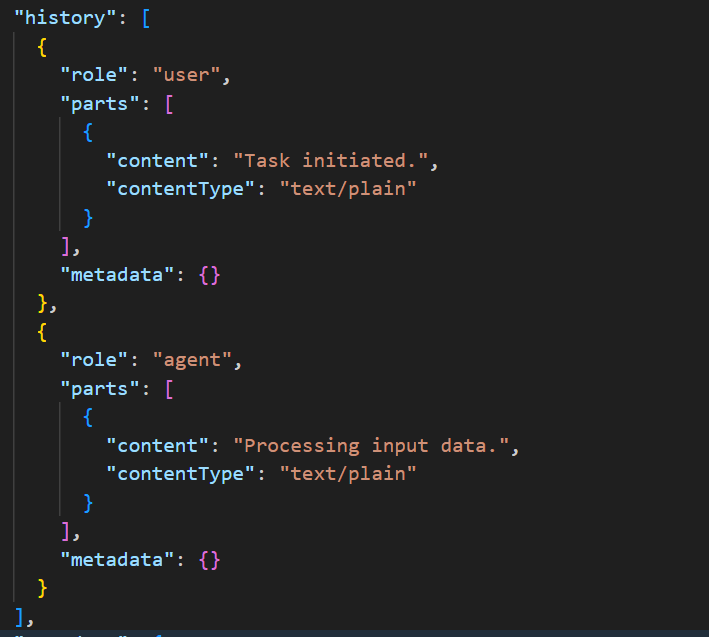
Here is the history section (Messages), note the presence of a user as well as an agent message:
Example of a history (Message) section within a Task.
The latest budget is out in India. The big talking point is the income tax rebate on incomes up to 12 lakh per annum (all figures in INR). The key target for this is the middle class that was throwing rocks at the government through memes and YouTube influencers.
The change in thinking is to move away from Government spending to private consumption by giving those that pay income tax more money at the end of the month.
The net benefit from this tax is about 80k per year for income tax payers with incomes up to 12 lakh pa. As your income goes above 12 lakh pa there is a sharp drop and then a gradual increase to a maximum of 1.1 lakh pa benefit if your income is 25 lakh pa
There are couple of things to understand to put this change in context.
Firstly…
This does not put money in your hands today. It is something you will get from April 2025 onwards as part of your monthly pay. So we should see that extra money in people’s hands ready to spend by end of March 2026! So this number will start to influence future outlook when it comes to stocks and other investments. The market will start to factor this today even if the full impact is not felt till the next year.
Secondly…
We need to think about the perception of increased money in our accounts before the actual accumulation happens. The ‘Annual Benefit’ column in the table below shows the amount people will start to feel richer by straightaway. But that money is not available to them today even though they are mentally already factoring it into their consumption decisions.
Annual Salary (INR)
Annual Benefit (INR)
Monthly Benefit (INR)
Percentage of Annual Salary
8,00,000
30,000
2,500
3.8%
12,00,000
80,000
6,666
6.6%
15,00,000
35,000
2,916
2.3%
25,00,000
1,10,000
9,166
4.4%
About Behaviours
Now if the aim is to boost private consumption then we need to understand what factors could influence the strength of the boost. And a lot of it will be behavioural factors. Let us understand the factors one by one.
Perception of Future Income
Remember the full amount is not available till March 2026. What will be economic prospects by then? Would India be reeling under the impact of Trump’s trade war or will we find other options for our goods (remember India enjoys a trade surplus with the US – one of the few countries we do so).
If prospects of future income are strong then I will be less hesitant in spending without worrying about the future (e.g., by borrowing – which is likely to get a boost with reduction in interest rates).
If prospects of future income are weak then I will use the money to build up a buffer. This money if invested in the stock markets is likely to have a positive impact. If saved in fixed deposits it will encourage investment by the banks (private investment).
Inflation
With more money in people’s hands and reduction of interest rates will this push inflation outside the RBI’s comfort zone of 4% (+/- 2%)? Currently it is holding at slightly above 5% not too far away from the 6%.
If people expect prices to rise by 4% even then that wipes out most gains made through tax breaks (see above table). This is because incomes have not risen at the same rate as prices over the last few years and there were some serious signs of dropping consumption which also reduced the GDP forecasts for FY 2025.
Spending Priorities
Given this perception of more money coming in, if critical businesses like schools and hospitals increase their prices (or there is a perception of possible price increase – see Inflation above) then people will use the extra money coming in every month to fill any funding gaps between the incoming and outgoing.
Even if this is used to ‘loosen’ the belt to go back to consuming what they had to give up then we are likely to see some short term increase in prices as industries in India ramp up production.
Investments
For those who have a decent gap between incoming and outgoing already they will start getting busy finding new avenues to invest their money. Crypto is a no-go because of tightening regulation. That leaves traditional savings products or the stock market.
Non-Essential Spending
This is perhaps the most interesting variable because even though the segment that have decent separation between incoming and outgoing is a small piece of the pie, in absolute numbers they will form a large segment.
These are the people who won’t hesitate now (as the Government hopes) in increasing their spending on non-essentials as they already have some cushion when it comes to the essential spending. For example, because they do not have kids, or they have multiple sources of income (e.g., parent’s pension, husband and wife both work), or they are not paying home instalments (e.g., living in parental home).
This may allow them to consume more takeaways, buy a more expensive car (with a higher monthly loan – from April 2025), or even take that one extra holiday this year.
A Better Solution
My focus would have been towards enabling the women of India. India cannot fulfil its dreams of becoming a developed country till we don’t enable our women. Currently female labour-force participation is quite low in India (about 33%). The income gap is also quite large where for every INR 100 earned by a man in India, a woman earns INR 40.
So if I was advising our honourable Finance Minister – I would have advised her to give all women 100% tax rebate till 25 lakh per annum. Given the focus on digitisation and identity I think this could have been done with limited leakage.
Also as women’s income increase they find efficient ways of deploying that money. The living standards of the family go up as does the health of the children and their education levels.