Firstly sorry for the break! Been busy with few things. But here goes – the next instalment of our ANN series.
So far we have covered in the first and second posts:
a) To classify more complex and real world data which is not linearly separable we need more processing units, these are usually added in the Hidden Layer
b) To feed the processing units (i.e. the Hidden Layer) and to encode the input we utilise an Input Layer which has only one task – to present the input in a consistent way to the hidden layer, it will not learn or change as the network is trained.
c) To work with multiple Hidden Layer units and to encode the output properly we need an aggregation layer to collect output of the Hidden Layer, this aggregation layer is also called an Output Layer
d) The representation of the input and output can have a big influence on the performance of the neural network especially when it encounters noisy data
To the first point, while it is good to be able to add more hidden units and multiple hidden layers, we quickly come up against the problem of how to train such networks. This is not only a theoretical problem (e.g. vanishing gradient – see the first post) but also a computational one.
The Challenge:
- More hidden units mean complex features can be learnt from the data
- Multiple layers are difficult to train using standard back prop due to the vanishing gradient problem
- Multiple layers are also difficult to train because we need to distribute the training effort so that each layer is able to support the other layers at the end of the training (a hint: perhaps we need to look at independent training of each layer to delink them?)
- Adding more hidden units also increases the computational load especially if the training data set is massive, Stochastic Gradient Descent only partially solves the problem
The Solution:
- Add more hidden layers (i.e. more hidden units) to make the network deeper (thus the ‘deep’ in the ‘deep learning’)
- Use a combination of bottom-up and top-down learning to train this ‘deep’ network
- Use specialised libraries that support GPU based distributed data processing (e.g. Tensorflow, DL4J)
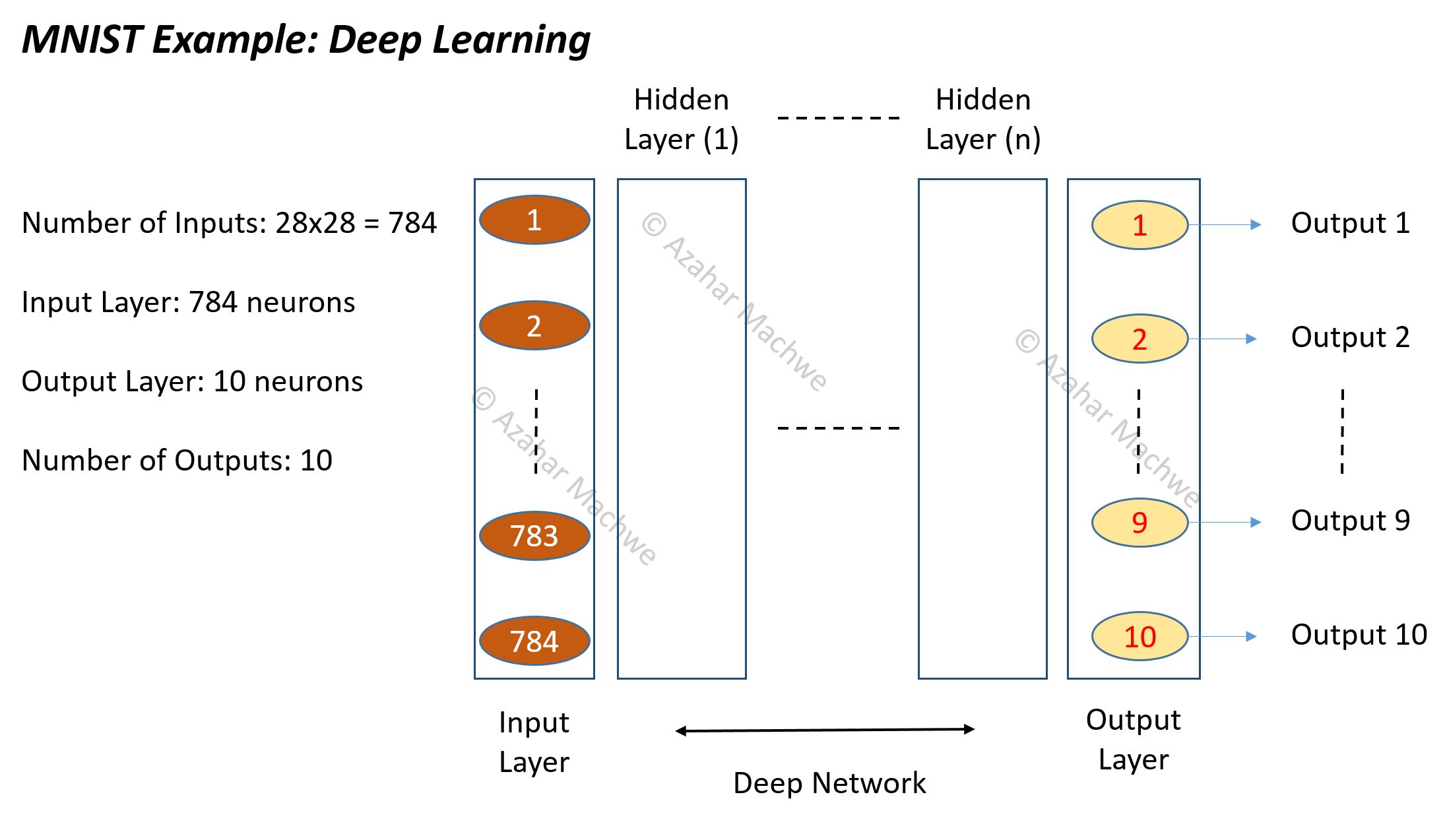
Image above shows a deep learning network setup for the MNIST data set where inputs are gray-scale images (of constant pixel count 28×28) of single handwritten digits (0 to 9) which need to be mapped to their corresponding number. Each pixel in the 28×28 image is normalised and treated as an input. This gives us a full input length of 784 neurons. There are 10 digits (0 to 9) as a possible output class so the full output length is 10.
We have previously tried shallow networks and gotten good performance of about 95% with 300 hidden units organised as a single hidden layer, compare this to deep learning networks which achieve 99.7%
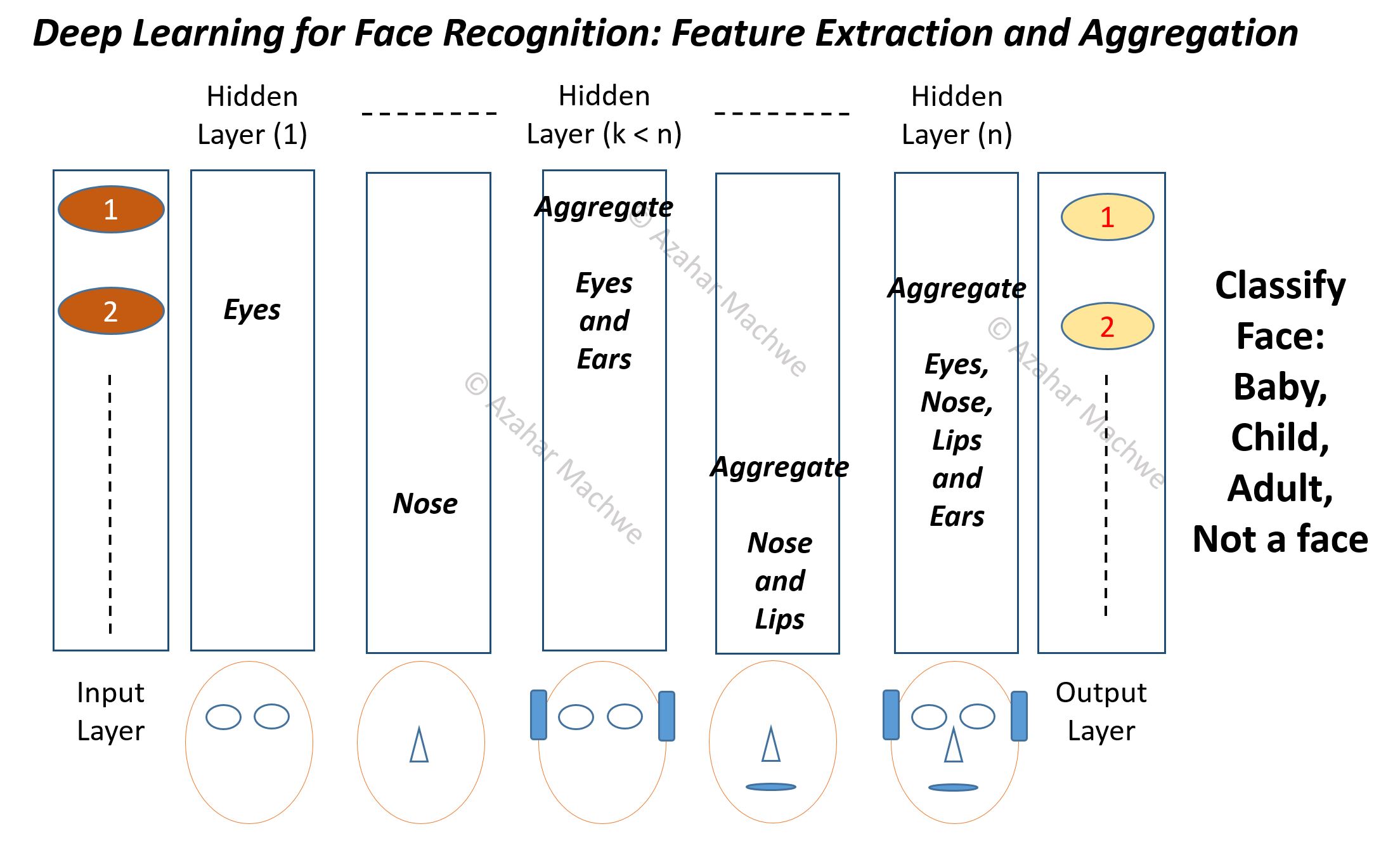
Deep learning works by distributing the ‘learning’ load across the hidden layers by ‘learning and aggregating’ smaller features to make larger features.
Image below shows how a Face Detector, which detects if an image contains a face of a child, baby or an adult, may distribute the feature learning and aggregation between the hidden layers.
The Building Blocks:
There are quite a few different types of ‘deep learning’ networks out there specialised for different application types (such as image tagging, document processing etc.). Some of them are not even ‘deep’ (e.g. Word2Vec) yet they incorporate novel training methods that allow them to deal with complex tasks (such as language translation) as if by magic.
I believe it will be more useful if I describe some of the common building blocks with reference to the ‘Deep Belief Network’ (Hinton et.al. 2006) as it is relatively simple (it has ‘boolean’ states in the hidden units instead of real valued ones).
The common building blocks include:
- One-Hot Encoding
- Softmax Layer
- Sigmoid and ReLU Activation Functions
- Restricted Boltzmann Machines (RBM)
- Distributed Layer-wise Unsupervised Training (Contrastive Divergence)
- Back-prop based Supervised Training (Fine Tuning)
One-Hot Encoding:
One-Hot Encoding is a really simple way of encoding outputs related to states.
The idea is that to represent S different states you need to have a S-bit binary string where for each state s in S only one bit in the binary string is set.
This can also be used to represent mutually exclusive classes and we have to pick one (for example a transaction cannot be both fraudulent and normal at the same time)
Let us assume we have a classifier which has to classify all inputs into one of 5 classes A, B, C, D, E.
How do we put this as an output for a neural network? Should we have just one output neuron and divide the possible output range between the 5 classes (e.g. 0-10 = Class A, 11-20 = Class B etc.), no that sounds weird especially because the output values could mean anything and nothing, also this complicates the training.
The easiest option in this case is to have one output per class, using one-hot encoding (thus a 5-bit output vector). When we train the model we simply require that the corresponding output value be significantly higher than all others so as to indicate that particular class.
One possible scheme:
A = [1,0,0,0,0]
B = [0,1,0,0,0]
C = [0,0,1,0,0]
so on..
Then if we get an output vector like:
[0.16, 0.23, 0.67, 0.03, 0.1]
we can be reasonably sure that our model is telling us the input belongs to Class C as for that class position 3 has the highest value in the label. One thing to note is that the output vector still does not tell us anything about how close two values in it are because these are just numeric values without a comparative scale (e.g. such as those found in case of probabilistic scores where all scores are compared to the value of 1 and the highest score wins).
This is where Softmax comes into the picture.
Softmax Layer:
The Softmax Layer is really straight forward to understand. It is usually found as the outermost layer of the network because it has the very important property of being able to convert ANY set of inputs into probability values such that all the values sum to 1 ( a very important property for probability values).
The softmax function is:
P(i) = e^(x(i))/Sum(e^(x(j)))
Where x(i) is the ith output that we want to convert to a probability value.
and Sum(P(i)) = 1
Below is the function in Java.
[codesyntax lang=”java”]
/**
* Softmax function
* @param input - to be converted to probabilities
* @return
*/
public static double[] softmax(double[] input) {
double prob[] = new double[input.length];
double sum = 0;
for (double val : input) {
sum += Math.exp(val);
}
if (sum == 0) {
throw new IllegalStateException("Sum cannot be zero");
}
for (int i = 0; i < input.length; i++) {
prob[i] = Math.exp(input[i]) / sum;
}
return prob;
}
[/codesyntax]
Example:
Assume there are 5 output units (thus length of output vector = 5) where each unit represents a class (as defined during the supervised learning phase e.g. Output Unit 1 = Class A; Output Unit 2 = Class B etc.).
For a certain input we get the following outputs (say using the Sigmoid function – see below) at Unit 1 -> 5:
[0.01, 0.23, 0.55, 0.29, 0.1]
While we can say score for Class C (Unit 3) = 0.55 looks like a good answer we cannot be 100% sure as this is not a probability value. Also Class D (Unit 4) = 0.29 is not that far off or is it? We can’t say for sure because we do not have a scale to compare against. Wouldn’t it be great if we could convert these to a probability value then we could compare them with each other and simply pick the largest value as the most probable class and ALSO provide our ‘confidence’ at the result?
If we use Softmax we get the following probability values:
[0.157, 0.195, 0.269, 0.207, 0.172]
(values are rounded to fit here so they may not exactly total to 1 – the problem with floating point arithmetic in Java)
The result is very interesting! Now we see Class C and D are just 6% away from each other (27% and 21% approx.). This is far closer than the original output vector. So while we can play it safe and choose Class C (the largest probability value) we will have to indicate somehow that we are not very sure about it as Class D came very close as well.
This can be converted to the following one-hot with a suitable confidence warning:
[0, 0, 1, 0, 0]
The interesting point about Softmax is that larger the scores, clearer is the separation between the probability values.
For example, if the output was (perhaps from ReLU units – see below):
[1, 2, 4, 3, 0]
we get probability score as: [0.032, 0.0861, 0.636, 0.234, 0.012]
This tells us there is a high probability that Class C is the correct class. The separation is now 40% between Class C and D.
Sigmoid and Rectified Linear Unit (ReLU) Activation Function:
The Sigmoid function ensures all output values are between 0 and 1. This allows us to use a probabilistic interpretation of the output. The closer the value is to 0 or 1 more confident we are about it. if the value is around 0.5 then we are not really sure.
It has the following form:
Sigmoid (x) = 1 / (1 + e^(-x))
One interesting property of the Sigmoid (which lends itself to back-prop training) is that its differential can be represented using Sigmoid:
Sigmoid'(x) = Sigmoid(x)(1-Sigmoid(x))
This also compares well with a Bernoulli Trial where Sigmoid(x) = P(x) and 1-Sigmoid(x) = Q (not x) = 1 – P(x).
This function is also used in ‘logistic regression’ where for a two class problem each class is represented by the edge values of the Sigmoid (0 and 1).
When we look at multi-class problems a common encoding follows the one-hot pattern where there is one sigmoid output per class which tells us how confident we are about that class. Remember it tells us NOTHING about how these compare with each other.
So if for 5 classes we have 5 sigmoid outputs where:
- a value close to 0 means we are very sure the input does not belong to the class
- a value close to 1 means we are very sure the input does belong to the class
we would still need something like a Softmax to compare these outputs with each other to choose a single class out of the 5 and reason about how confident we were about that choice.
The ReLU function comes from the behavior of a half-wave rectifier unit in electrical engineering where these units convert AC to DC. The function is VERY easy to model and process, there are no messy exponential terms. These allow just the right amount of non-linearity into a neural network thereby allowing us to handle non-linear classification tasks (more info here).
The function is:
ReLU(x) = max(0,x)
Its differential for x > 0 (required for back-prop) is a constant value of 1
The ReLU has several advantages including the fact that it is very easy to calculate and differentiate. If you see the difference it brings to the back-prop equations you will never want to even think about using Sigmoid.
The one problem with ReLUs is that once it is closed during a forward pass (i.e. x <=0) it will forever remain closed (even for backward passes). This is called the ‘dying ReLU problem’.
In the next post(s) we will cover Restricted Boltzmann Machines, Contrastive Divergence and Fine-tuning.
As usual – if I have made any mistakes do let me know!

4 Comments