Most automatic game playing involves some sort of algorithm or model that can manage and use limited resources to attain the goal of the game without human guidance. The limited resource may be lives (e.g. Super Mario), playing pieces (e.g. Chess), number of turns or time. Usually we choose one or more actions which use one or more resources (e.g. using our turn move a piece in Chess). To train the model usually the same game is played multiple times to build up the knowledge. See this post for a more detailed description of automated game playing.
The automated game player’s (AGP) primary task is to balance exploration of the state space of the game with exploiting (i.e. taking specific actions) to ‘win’ the game.
Exploration
The exploration task deals mainly with finding information about the state space, the value associated with each state and how actions influence state transitions. This allows us to select the optimum actions in the Exploitation stage. Exploration is not just about about movement actions. The AGP may want to spend a turn ‘exploring’ a new action like extracting a resource or attacking an enemy and assessing the corresponding reward.
Exploitation
Exploitation is about using the information we have gained from exploration and choosing one or more actions. Since exploitation also uses up resources we want to balance information gathering with information use. For example, in many games there is a choice between ‘fight or flee’, the AGP could adopt a policy of ‘flee’ all the time or it could choose to explore the fight action and update its policy to be a mixture of both or it could find that exploring the fight action led to much better outcomes therefore it may decide to have a pure fight policy. But in a game there are limited opportunities to choose what to do, potentially infinite state space and state transitions that are not deterministic. Lets pick these apart one at a time using the Knights and Dragon game.
State Space and State Transition from the Knights and Dragon Game
State pace is a set of values that can be used by AGP to reason about the game environment. State space can directly represent the game (e.g. chess grid with players pieces) or indirectly (e.g. field of view in first-person games like Doom).
To explain this we can look at the Knights and Dragon game. The game is now a simple 10×10 grid with green squares representing farmland. There are two knights and a dragon. The dragon is controlled by a set of simple rules: detect nearby players, move towards closest player then attack closest player if in range.
The knights are controlled by the AGP. The knights don’t know anything about the state space to begin with. They have the following actions available: rest, grow food, search for food, attack, move (up, down, left, right) based on the current state.
The state space for a knight is made up of the following six values: knight’s health (max 10), knight has food (Boolean 1/0), current position of the knight (x and y), food on the current tile (max 10), dragon’s health (max 30).
Actions transition the knights from one point in the 6d space to another point. For example take a knight with state space: (10,1,5,5,10,30). If the knight takes a ‘search for food’ action then it moves to (10,1,5,5,8,30) because that action extracted 2 food from the current cell (represented by the 10 in the first point).
In general the state transition for Knight 1 in current state S1 taking action ‘move’ can be defined as a mapping.
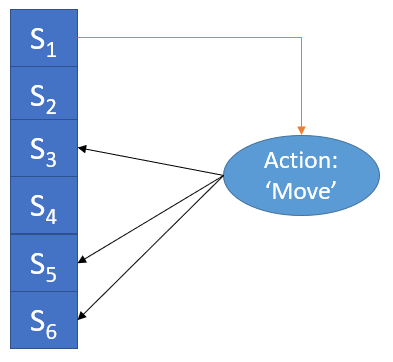
The picture above shows the one-to-many nature of state transitions in this game where S1 to S6 are states in the game. Taking the ‘move’ action when in state S1 can take us to states S3, S5 or S6. This is due to the dynamic nature of the cell state (representing the food resource).
Initially Knight 1 has no idea about state transition mappings. Therefore there is no option but to explore and build up the state transition map before the AGP has enough information to start exploiting.
State Value
As the state transition map is built up we need a way to attach a value to each state so that we can start exploiting it in selecting the best action to take. In the current environment the reward is simply survival at the end of each turn. Each Knight gets +1 reward if they end their turn with full health (= 10). We can use Monte-Carlo or Temporal Difference (TD)methods to iteratively build up the value of each state.
Since in this case we do not have 1-1 mapping between ‘before’ and ‘after’ states, the AGP cannot directly evaluate the utility of taking an action. If there was 1 to 1 mapping then the value of taking an action would be same as the value of the ‘after’ state. One way of finding a combined value of an action is to take an average of the value of the states [S1, …, Sn] reachable by taking that action. For example, going back to Figure 1, if we have built up State values for S1, S2,.., S6 using TD method then when we are in State S1 we can evaluate the utility of taking the ‘Move’ action by averaging State values of S3, S5 and S6 because so far the AGP has learnt these three possible next states associated with this current state and action.
The expression so far I used above is important to explain. Typically the AGP has only one task – to ‘win’. The AGP should not need to know every state transition to ‘win’ because that would be quite difficult for anything but the simplest of games. Therefore, as AGP plays and discovers more of the transitions it will reach a point where it will be able to ‘win’ by utilizing what it has explored. Before that point the AGP can only decide based on what transactions have been explored. After that point there is no real incentive to explore unless the reward function is modified.
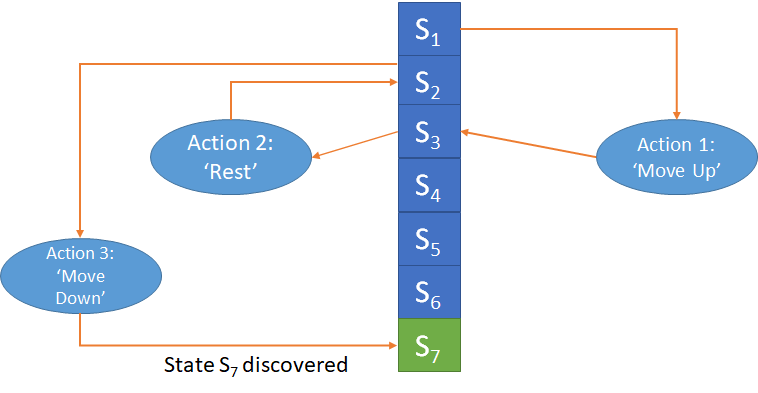
Looking at Figure 2, we may find that ‘winning’ requires the AGP to transition to State S7 – which at this point we are not aware of as we have not come across a combination of current state and action that takes us to S7. Once we discover S7 (in this example from S2 taking the ‘Move Down’ action) we will quickly build up its value using methods like TD.
Another important element for the AGP is memory. If the AGP forgets the state information between each game then we will be forever exploring and never reach a state where we can exploit, unless the games are long enough to build up transition mapping every time we play. But that would like learning from scratch the different strategies of Chess every time we start to play.
Sample of three states with corresponding state values:
(10, 1, 10, 30, 1, 1): 9.6557
(10, 0, 10, 30, 1, 1): 7.9430
(10, 1, 8, 30, 1, 1): 7.9784
TD Update Equation:
V(s) <- V(s) + a*{(R + g*V(s')) - V(s)}
V(s): Value of current state (s)
V(s'): Value of new state (s')
R: reward when transitioning to new state (s')
a: alpha - constant
g: gamma - reward discount
Above we can see a sample of three states with corresponding state values. Also the TD Update Equation is provided. All state values are initialised to 0. Reward (R) is +1 for every step that ends with full health. Over time, as we explore more of the state transitions, the state values converge. We keep following the chain of states till we reach a terminal states defined as:
- Failure: Health of any Knight drops to 0
- Success: Knights survive 250 turns each
Results
To see the exploration vs exploitation in action we can run some easy experiments with our Knights. We start without any state information. We prioritise exploration by ensuring all actions are tried from the current state.
Once the AGP finishes exploring all the actions for a state, the next time it encounters that state it will start using estimated next state value to select the action. This estimation becomes more accurate as the state values converge over games.
We can tune this by adding a probability that the highest valued action will be disregarded and another action is chosen randomly.
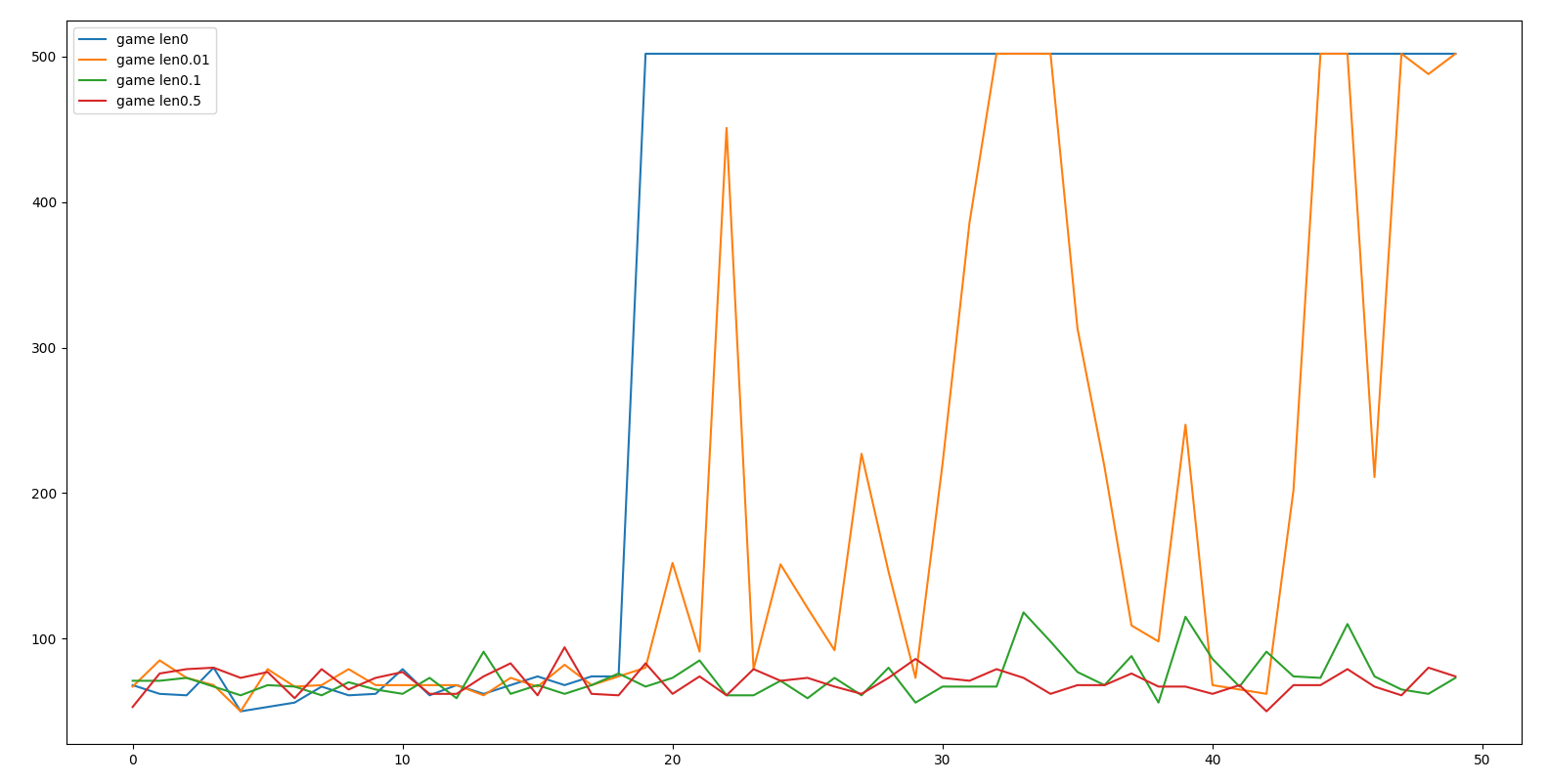
In Figure 3 we can see different probabilities of disregarding the highest valued action and how it impacts the game outcome. The game length in number of turns is given on the Y axis and number of games on the X axis. Whenever game length reaches 500 we assume that the AGP (controlling the Knights) won the game.
No Randomness: In the case where we never disregard the highest value action (blue line) we see after exploring and learning the state transitions (around the 19th time it plays the game) the AGP discovers a good solution and continues to exploit it. Following this discovery all the games reach the full 500 turns required to win.
1% Chance of Ignoring Highest Value Action: In this case we discard the highest value action 1% of the time (orange line). We see that the learning approaches the winning tactic but the randomness does not allow the AGP to settle into a winning routine.
10% and 50% Change of Ignoring Highest Value Action: As expected in this case (red and green lines) the learning is completely overshadowed by the randomness and AGP does not settle into any winning routine.
Finally, the winning tactic
So what is this winning tactic that the Knights have converged on? The winning tactic is to ignore all the actions except grow food and search for food. This is a farmer strategy where the Knights settle down and don’t move, don’t get close enough for the dragon to detect them. Its a perfect loop where following this strategy ensures all games are won. That is why we see the perfect success record (blue line) once this strategy is ‘discovered’. No other state value will come close to beating this.

Code:
Code can be found at: https://github.com/amachwe/pgame/tree/mdp
rl1.py – contains the state transition building logic and the ‘brain’ for the AGP: https://github.com/amachwe/pgame/blob/mdp/rl1.py
player_ga.py – contains a simple fully informed version of the ‘brain’ where we can workout the exact consequence of taking an action as the transition functions are available: https://github.com/amachwe/pgame/blob/mdp/player_ga.py
I have not cleaned the code but if you are interested I will be happy to explain the basics! Just leave a comment.
