We know GPT stands for Generative Pre-trained Transformers. But what does ‘Chat’ mean in ChatGPT and how is it different from GPT-3.5 the OpenAI large language model?
And the really interesting question for me: Why doesn’t ChatGPT say ‘Hi’?
The Chat in ChatGPT
Any automated chat product must have the following capabilities, to do useful work:
- Understand entity (who), context (background of the interaction), intent (what do they want) and if required user sentiment.
- Trigger action/workflow to retrieve data for response or to carry out some task.
- Generate appropriate response incorporating retrieved data/task result.
The first step is called Natural Language Understanding and the third step is called Natural Language Generation. For traditional systems the language generation part usually involves mapping results from step (1) against a particular pre-written response template. If the response is generated on the fly without using pre-written responses then the model is called a generative AI model as it is generating language.
ChatGPT is able to do both (1) and (3) and can be considered as generative AI as it does not depend on canned responses. It is also capable of generating a wide variety of correct responses to the same question.
With generative AI we cannot be 100% sure about the generated response. This is not a trivial issue because, for example, we may not want the system to generate different terms and conditions in different interactions. On the other hand we would like it to show some ‘creativity’ when dealing with general conversations to make the whole interaction ‘life like’. This is similar to a human agent reading off a fixed script (mapping) vs allowed to give their own response.
Another important point specific to ChatGPT is that unlike an automated chat product it does not have access to any back-end systems to do ‘useful’ work. All the knowledge (upto the year 2021) it has is stored within the 175 billion parameter neural network model. There is no workflow or actuator layer (as yet) to ChatGPT which would allow it to sequence out requests to external systems (e.g. Google Search) and incorporate the fetched data in the generated response.
Opening the Box
Let us now focus on ChatGPT specifics.
Chat GPT is a Conversational AI model based on the GPT-3.5 large language model (as of writing this). A language model is an AI model that encapsulates the rules of a given language and is able to use those rules to carry out various tasks (e.g. text generation).
The term language can be understood as the means of expressing something using a set of rules to assemble some finite set of tokens that make up the language. This applies to human language (expressing our thoughts by assembling alphabets), computer code (expressing software functionality by assembling keywords and variables) as well as protein structures (expressing biological behavior by assembling amino-acids).
The term large refers to the (175 billion) number of parameters within the model which are required to learn the rules. Think of a model like a sponge, complex language rules like water. More complex the rules, bigger the sponge you will need to soak it all up. If the sponge is small then rules will start to leak out and we won’t get an accurate model.
Now a large language model (LLM) is the core of ChatGPT but it is not the only thing. Remember our three capabilities above? The LLM is involved in step (3) but there is still step (1) to consider.
This is where the ChatGPT model comes in. The ChatGPT model is specifically a fine-tuned model based on GPT-3.5 LLM. In other words, we take the language rules captured by GPT-3.5 model and we fine tune it (i.e. retrain a part of the model) to be able to answer questions. So ChatGPT is not a chat platform (as defined by the capability to do Steps 1-3 above) but a platform that can respond to a prompt in a human-like way without resorting to a library of canned responses.
Why do I say ‘respond to a prompt’? Did you notice that ChatGPT doesn’t greet you? It doesn’t know when you have logged in and are ready to go, unlike a conventional chatbot that chirps up with a greeting. It doesn’t initiate a conversation, instead it waits for a prompt (i.e. for you to seed the dialog with a question or a task). See examples of some prompts in Figure 1.

This concept needing a prompt is an important clue in how ChatGPT was fine tuned from the GPT-3.5 base model.
Fine Tuning GPT-3.5 for Prompts
As the first step the GPT-3.5 is fine-tuned using supervised learning on a prompt sampled from a prompt database. This is quite a time consuming process because while we may have a large collection of prompts (e.g.: https://github.com/f/awesome-chatgpt-prompts) and a model capable of generating a response based on a prompt, it is not easy to measure the quality of the response except in the simplest of cases (e.g. factual answers).
For example if the prompt was to ‘Tell me about the city of Paris’ then we have to ensure that the facts are correct as well as their presentation is clear (e.g. Paris is the capital of France). Furthermore we have to ensure correct grouping and flow within the text. It is also important to understand where opinion is presented as a fact (hence the second limitation in Figure 1).
Human in the Loop
The easiest way to do this is to get a human to write the desired response to the sampled prompt (from a prompt dataset) based on model generated suggestions. This output when formatted into a dialog structure (see Figure 2) provides labelled data for using supervised learning to fine-tuning the GPT-3.5 model. This basically teaches GPT-3.5 what a dialog is.
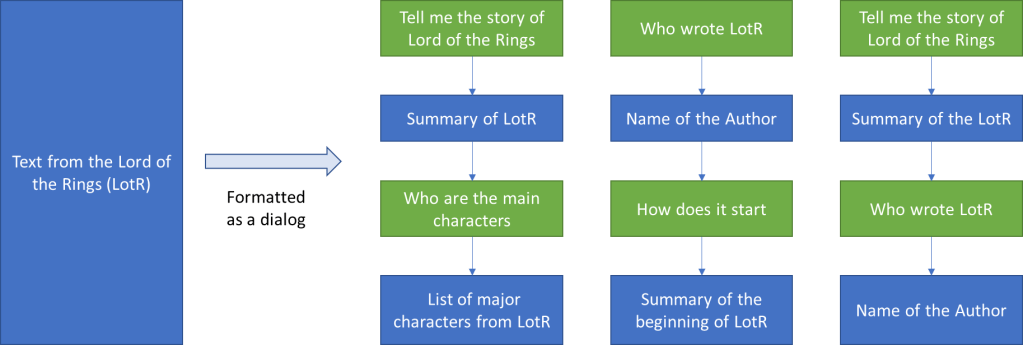
But this is not the end of Human in the Loop. To ensure that the model can self-learn a reward model is built. This reward model is built by taking a prompt and few generated outputs (from the fine-tuned model) and asking a human to rank them in order of quality.
This labeled data is used to then create the reward function. Reward functions are found in Reinforcement Learning (RL) systems which also allow self-learning. Therefore there must be some RL going on in ChatGPT training.
Reinforcement Learning: How ChatGPT Self-Learns
ChatGPT uses the Proximal Policy Optimization RL algorithm (https://openai.com/blog/openai-baselines-ppo/#ppo) in a game-playing setting to further fine-tune the model. The action is the generated output. The input is the reward value from the Reward function (as above). Using this iterative process the model can be continuously fine-tuned using simple feedback (e.g. ‘like’ and ‘dislike’ button that comes up next to the response). This is very much the wisdom of the masses being used to direct the evolution of the model. It is not clear though how much of this feedback is reflected back into the model. Given the public facing nature of the model you would want to carefully monitor any feedback that is incorporated into the training.
What is ChatGPT Model doing?
By now it should be clear that ChatGPT is not chatting at all. It is filling in next bit of text in a dialog. This process starts from the prompt (seed) that the user provides. This can be seen in the way it is fine-tuned.
ChatGPT responds based on tokens. A token is (as per my understanding) a combination of up to four characters and can be a full word or part of one. It can create text consisting of up to 2048 tokens (which is a lot of text!).
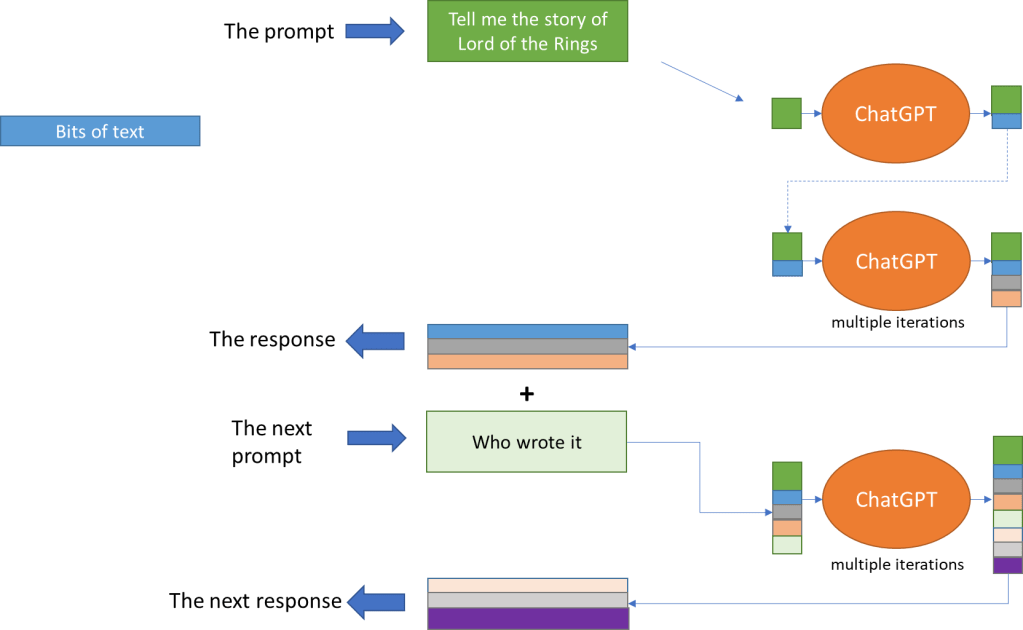
The procedure for generating a response (see Figure 3) is:
- Start with the prompt
- Take the text so far (including the prompt) and process it to decide what goes next
- Add that to existing text and check if we have encountered the end
- If yes, then stop otherwise go to step 2
This allows us to answer the question: why doesn’t ChatGPT say ‘Hi’?
Because if it seeded the conversation with some type of greeting then we would by bounding the conversation trajectory. Imagine starting with the same block in Figure 3 – we would soon find that the model starts going down a few select paths.
ChatGPT confirms this for us:

I hope you have enjoyed this short journey inside ChatGPT.