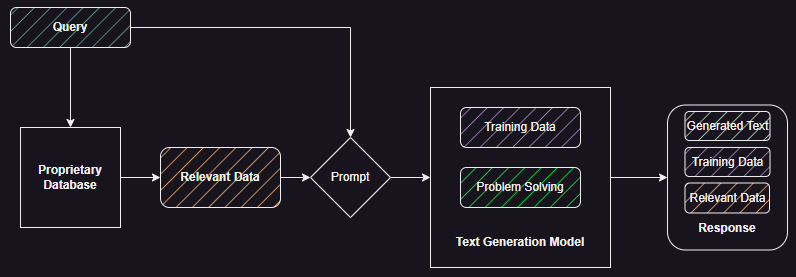
This post is about testing text-to-SQL generation capabilities with human in the loop. The broader use-case is around being able to talk with your data for generating insights.
The results will blow your mind!
So instead of creating dashboards around questions (e.g., which product had the highest sales in the previous 3 months?) you could ask any question and an automated system would go and query the right data to return a response in a human understandable way.
Model: For this post I am using the Defog text-to-SQL model (8 billion parameters) based on Llama-3 from Hugging Face: defog/llama-3-sqlcoder-8b. This is a relatively new model (mid-May 2024).
Infrastructure: the model is running locally and takes about 30gigs of RAM for the prompts I used. I use a SQLite 3 database as a backend.
Model Deployment: I have created a python flask web-server (read more here) that allows me to deploy any model once when the server starts and then access it via a web-endpoint.
Software: A python web-client for my model server that takes care of prompting, workflow, human-in-the-loop, and the integration with other components.
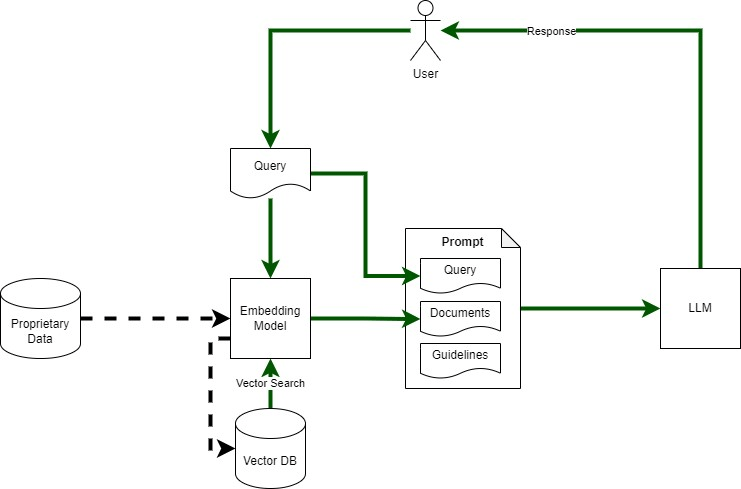
Figure 1 shows the flow of the main app and its interactions with the LLM and the SQL database.
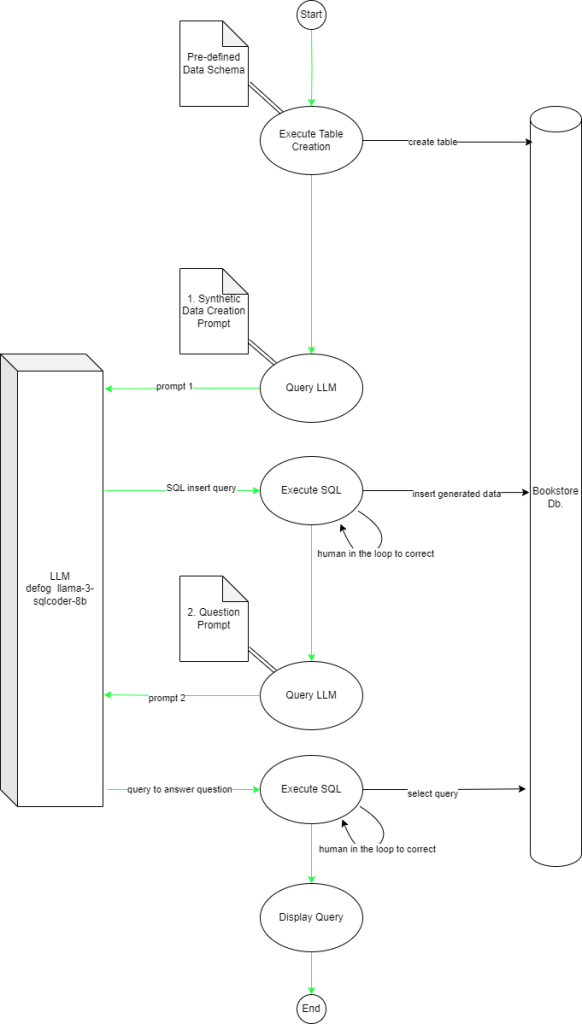
Challenges to overcome: This is a complex use-case that covers synthetic data creation based on schema, Insert, and Select use-cases against a multi-table database. This requires the LLM to:
- Understand the Data Definition (in SQL)
- Correctly generate synthetic data based on the definition
- Correctly generate the insert statements (in the correct order as the foreign keys have a not null clause)
- Understand the user’s question
- Convert the question into a valid SQL query with joins and other operations as required
Keep in mind that this is not a gazillion parameter GPT-4o or Gemini. This is not even the larger variant of the sqlcoder model with 34 billion parameters. This is the humble 8b parameter version!
The Schema: The schema simulates a book store with four tables – authors, books, inventory, and transactions. The relationships are as follows:
- Author (1) -> (*) Books
- Books (1) -> (1) Inventory
- Books (1) -> (1) Transactions
Synthetic data is generated for all the tables based on directions given in the first Prompt (prompt 1).
The question (Which Author wrote the most books?) requires a join between the Author and Books tables.
The Stages
Posting some snippets of the output here, the full code can be found on my Github repo.
Creating the Tables
A simple data definition (DDL) script that is run by the python client.
create table authors (author_id varchar(20) primary key not null, name text not null);
create table books (book_id varchar(20) primary key not null, name text not null, author_id varchar(20) not null, FOREIGN KEY(author_id) REFERENCES authors(author_id));
create table inventory (inv_id varchar(20) primary key not null, book_id varchar(20) not null, quantity int not null, FOREIGN KEY(book_id) REFERENCES books(book_id));
create table transactions(tx_id varchar(20) primary key not null, book_id varchar(20) not null, quantity_sold int not null, sale_date date not null, FOREIGN KEY(book_id) REFERENCES books(book_id));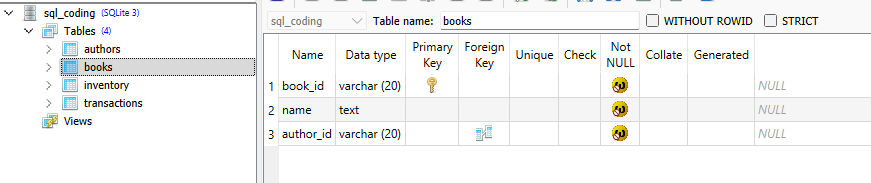
We can see the output above with the full structure of the books table. I am using SQLite Studio to view the structure and data only, all changes are made programmatically. This is still using python sqlite libraries so nothing magical yet.
Creating and Inserting Synthetic Data
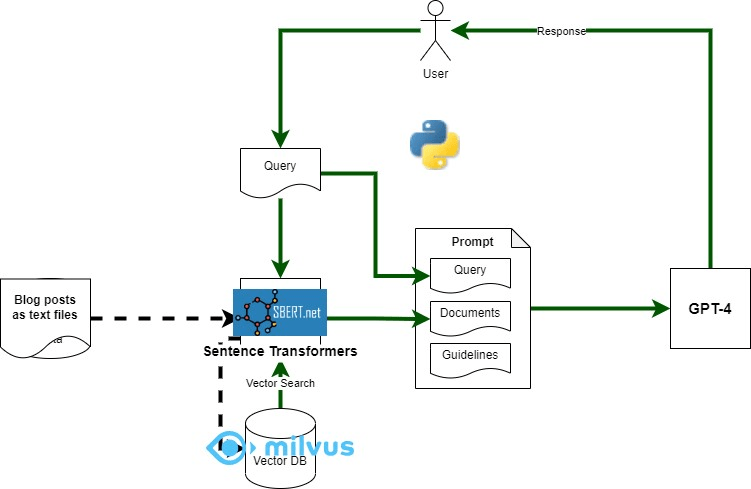
For the next step (creating and inserting synthetic data) we bring in the LLM (sqlcoder). The prompt used can be seen in Figure 2. The ddl placeholder just injects the above create SQL statements to provide information about the structure of tables and relationships between them. We also define the number of records per table and some other constratins.

The LLM returns the following response to the above prompt. We can see the constraints for number of records and number of books per author are respected.
INSERT INTO authors (author_id, name) VALUES ('a1', 'John Smith'), ('a2', 'Jane Doe'), ('a3', 'Bob Brown');
INSERT INTO books (book_id, name, author_id) VALUES ('b1', 'Book1', 'a1'), ('b2', 'Book2', 'a1'), ('b3', 'Book3', 'a2'), ('b4', 'Book4', 'a2'), ('b5', 'Book5', 'a3'), ('b6', 'Book6', 'a3'), ('b7', 'Book7', 'a1');
INSERT INTO inventory (inv_id, book_id, quantity) VALUES ('i1', 'b1', 5), ('i2', 'b2', 3), ('i3', 'b3', 4), ('i4', 'b4', 2), ('i5', 'b5', 6), ('i6', 'b6', 8), ('i7', 'b7', 9);
INSERT INTO transactions (tx_id, book_id, quantity_sold, sale_date) VALUES ('t1', 'b1', 2, '2022-01-01'), ('t2', 'b2', 1, '2022-01-02'), ('t3', 'b3', 3, '2022-01-03'), ('t4', 'b4', 4, '2022-01-04'), ('t5', 'b5', 5, '2022-01-05');Below we can see a screenshot from SQLiteStudio after the generated insert statements were run. We can see the SQL generator has clearly picked out the schema of each table and the relationships between them just from the data

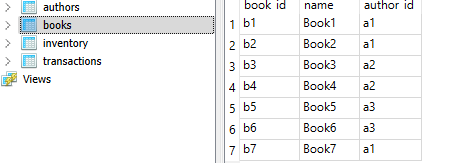
The stage is now set for us to move to ‘talking to your data’.
Asking A Few Questions
The first question we ask is: Tell me which author has written the most books?
If you are familiar with the Spider 1.0 challenge from Yale (for Text-to-SQL) this above question is a medium complexity one because the model has to correctly identify the need for a join and populate the current table and field names given the schema.
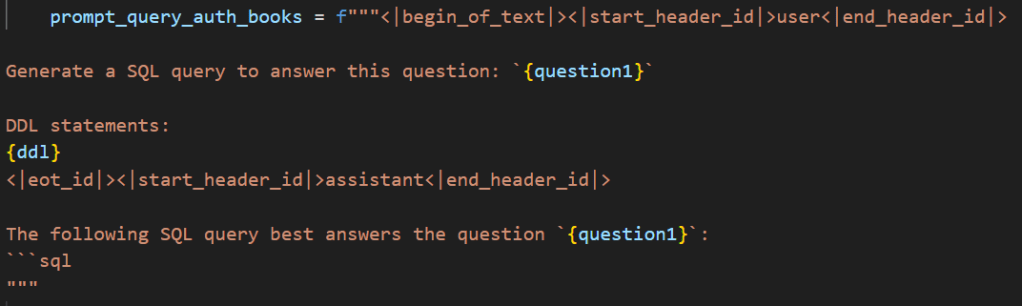
The prompt template is given below. The placeholder question1 is what we use for questions. In this case I created two separate prompts but the structure is exactly the same and we can easily convert it into a function that takes in a question as a string and outputs the filled template.
The entry below shows the SQL query generated by the model and the Query Output when that query is executed.
SQL Query:
WITH BookCounts AS (SELECT a.name, COUNT(b.book_id) AS book_count FROM authors a JOIN books b ON a.author_id = b.author_id GROUP BY a.name) SELECT name, book_count FROM BookCounts ORDER BY book_count DESC LIMIT 1;
Query Output: ('John Smith', 3)The Query output gives the correct answer.
The next question is: Tell me which books had the highest sales?
Now the key point about this query is that I am not talking about the book that sold the most, instead I am talking about the ‘books’. The model recognises this. We use the same template as above but just replace the text in the question1 placeholder with the above question.
SQL Query:
WITH TotalSales AS (SELECT b.book_id, SUM(t.quantity_sold) AS total_sales FROM transactions t JOIN books b ON t.book_id = b.book_id GROUP BY b.book_id) SELECT bs.book_id, bs.total_sales FROM TotalSales bs ORDER BY bs.total_sales DESC NULLS LAST LIMIT 5;
Query Output:
('b5', 6)
('b4', 4)
('b2', 3)
('b1', 2)
('b3', 1)The Query output once again gives the correct output. The model has interpreted the need to give the top n results. In fact the model has gone a step further and set n to ‘5’, so it returns the top 5 books in terms of sales using a join between the transaction and books table.
The final question is: Tell me which author has the most sales?
Looking at Spider 1.0 this would come in the Hard category.
This time I wanted to check a question that requires more than one join and a group operation. So in this case you need to join the transactions and books table and then group and join the result to the authors table to cater for the fact that a single author may have written multiple books.
SQL Query:
WITH TotalSales AS (SELECT b.author_id, SUM(t.quantity_sold) AS total_quantity_sold FROM transactions t JOIN books b ON t.book_id = b.book_id GROUP BY b.author_id), RankedAuthors AS (SELECT a.author_id, a.name, ts.total_quantity_sold, RANK() OVER (ORDER BY ts.total_quantity_sold DESC) AS sales_rank FROM authors a JOIN TotalSales ts ON a.author_id = ts.author_id) SELECT ra.name, ra.total_quantity_sold FROM RankedAuthors ra WHERE ra.sales_rank = 1;
Query Output:
('Jane Doe', 6)Once again the result is correct! Amazing stuff as promised! I have tried this demo more than 20 times and it worked flawlessly.
The code for the SQL LLM Server https://github.com/amachwe/gen_ai_web_server/blob/main/sql_coding_server.py
The code for the SQL LLM Server client: https://github.com/amachwe/gen_ai_web_server/blob/main/sql_coding_client.py
Have fun!