The UK Government provides data for property transactions for all sales in England and Wales. This data is updated monthly and all the files can be found: https://www.gov.uk/government/statistical-data-sets/price-paid-data-downloads
The single CSV datafile (going back almost 30 years) is approximately 5gb.
I wanted to use this as a target to learn more about the cloud as it is not a ‘toy’ dataset. The idea is to do everything using cloud components and services. I decided to use GCP as it has a generous ‘free’ tier.
Also I wanted to automate as much of the deployment as I could using Terraform Infrastructure as Code (IaC). This makes maintaining the project a lot easier as well as making changes. One of the things to remember is that even with IaC there are many components that support ‘config change’ by tearing down and creating the resource again.
Terraform IaC
Terraform is at its core four things:
- A Language (HashiCorp Configuration Language) to describe configuration to be applied
- A Set of Providers that convert configuration described in the Terraform language to API commands for the target platform
- The ‘terraform’ command that brings together the Terraform config files and Providers
- Configuration state store
The first feature allows one language to describe all kinds of configurations (IaC). The second feature abstracts away the application of that config via Providers (adapters). The third feature allows us to interact with Terraform to get the magic to work. The fourth feature provides a ‘deployed’ state view.
A key artefact when applying config is what Terraform calls a ‘plan’ that explains what changes will be made.
Terraform interacts with target providers (like Google Cloud, AWS, Azure) using ‘provider’ code blocks and with components made available by those providers using ‘resource‘ code block. Each ‘resource’ block starts off with the resource-type it represents and its name.
One thing to remember is that a Provider (defined using the ‘provider’ code block) has no special way of interacting with the target provider. It is ultimately dependent on the APIs exposed by the target provider. If a provider forces you to use their UI for certain management scenarios then you won’t be able to use Terraform.
Also providers generally have their own IaC capabilities. For example the Google Cloud Deployment Manager and the AWS CloudFormation.
The Project (ver. 1)
Given that I am using the ‘free’ tier of Google Cloud and want to learn those capabilities step-by-step (while avoiding the ‘paid’ tier) I am building my cloud architecture using basic services such as Google Cloud Storage, BigQuery and Looker.
My cloud architecture v1 looks like this:
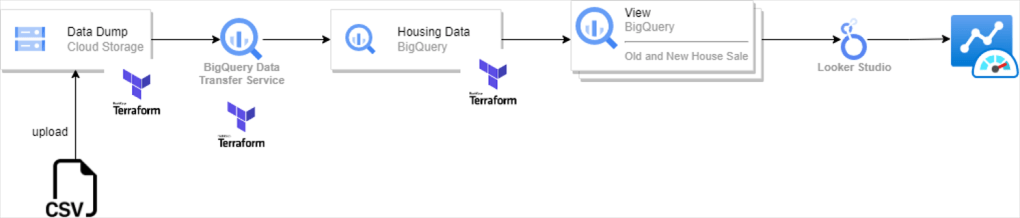
The CSV file containing the full housing data set gets uploaded to GCS bucket. From there a BigQuery Data Transfer Service parses the CSV file and injects it into a BigQuery table. We then run a set of saved queries to create views for our dashboard. Finally those views are consumed from a Looker Studio Dashboard.
The Terraform symbol in the figure indicates automated resource creation. In the current version I am auto-creating the GCS bucket, BigQuery Data Transfer Service and the BigQuery table. The CSV upload can also be automated by using the ‘google_storage_bucket_object’ resource.
The reason I started off with the above pieces of automation is because I found taking these steps again and again to be very frustrating – especially creating the Table in BigQuery as the schema is fairly complex as well as creating a data transfer job with correct parsing parameters.
The Implementation
The resulting dashboard can be seen here: https://datastudio.google.com/reporting/138a9b59-7cf6-4b04-9c19-fb744b1c7854
You can filter by property type: Terraced (T), Flat (F), Other (O), Semi-detached (S) and Detached (D). Then you can see how the combined old + new transactions signal splits if we see only the New Builds (top – right) or only the Resales (Old Builds in bottom – right).
The Terraform code is given below, items in <> need to filled in before running the script:
#using existing project - otherwise we can create a new project as well
provider "google" {
project = "<your project name>"
}
#setup bigquery dataset
resource "google_bigquery_dataset" "housing2" {
dataset_id = "housing_dump_2"
location = "us"
delete_contents_on_destroy = true
labels = {
env = "default"
}
}
#setup gcs bucket
resource "google_storage_bucket" "housing_bucket" {
name = "<your bucket name>"
location = "US-east1"
force_destroy = true
public_access_prevention = "enforced"
uniform_bucket_level_access = true
storage_class = "STANDARD"
}
# setup bigquery data transfer
# to parse CSV file in gcs bucket into bigquery table
resource "google_bigquery_data_transfer_config" "default" {
display_name = "mirror_data_dump"
destination_dataset_id = google_bigquery_dataset.housing2.dataset_id
data_source_id = "google_cloud_storage"
params = {
destination_table_name_template = "housing_data"
write_disposition = "MIRROR"
data_path_template = "gs://<gcs bucket>/<csv file name>"
file_format="CSV"
field_delimiter=","
quote = "\""
delete_source_files = "false"
skip_leading_rows = "0"
}
schedule_options {
disable_auto_scheduling = true
}
}
#create bigquery table with the correct schema to support data transfer
resource "google_bigquery_table" "default" {
dataset_id = google_bigquery_dataset.housing2.dataset_id
table_id = "housing_data"
deletion_protection = false
time_partitioning {
type = "DAY"
}
labels = {
env = "default"
}
schema = <<EOF
[
{
"name": "transaction_guid",
"mode": "NULLABLE",
"type": "STRING",
"description": "Transaction GUID",
"fields": []
},
{
"name": "price",
"mode": "NULLABLE",
"type": "INTEGER",
"description": "Price",
"fields": []
},
{
"name": "date_transfer",
"mode": "NULLABLE",
"type": "TIMESTAMP",
"description": "Date of Transfer",
"fields": []
},
{
"name": "postcode",
"mode": "NULLABLE",
"type": "STRING",
"description": "Postcode",
"fields": []
},
{
"name": "property_type",
"mode": "NULLABLE",
"type": "STRING",
"description": "D = Detached, S = Semi-Detached, T = Terraced, F = Flats/Maisonettes, O = Other",
"fields": []
},
{
"name": "old_new",
"mode": "NULLABLE",
"type": "STRING",
"description": "Old or New build",
"fields": []
},
{
"name": "duration",
"mode": "NULLABLE",
"type": "STRING",
"description": "\tRelates to the tenure: F = Freehold, L= Leasehold etc.",
"fields": []
},
{
"name": "PAON",
"mode": "NULLABLE",
"type": "STRING",
"fields": []
},
{
"name": "SAON",
"mode": "NULLABLE",
"type": "STRING",
"fields": []
},
{
"name": "Street",
"mode": "NULLABLE",
"type": "STRING",
"fields": []
},
{
"name": "Locality",
"mode": "NULLABLE",
"type": "STRING",
"fields": []
},
{
"name": "City",
"mode": "NULLABLE",
"type": "STRING",
"fields": []
},
{
"name": "District",
"mode": "NULLABLE",
"type": "STRING",
"fields": []
},
{
"name": "county",
"mode": "NULLABLE",
"type": "STRING",
"fields": []
},
{
"name": "ppd_category",
"mode": "NULLABLE",
"type": "STRING",
"description": "A = Standard Price Paid entry, includes single residential property sold for value.\nB = Additional Price Paid entry including transfers under a power of sale/repossessions, buy-to-lets",
"fields": []
},
{
"name": "record_status",
"mode": "NULLABLE",
"type": "STRING",
"fields": []
}
]
EOF
}
To run the above simply save it as a Terraform file (extension .tf) in its own folder. Make sure Terraform is installed, in the path and associated with your GCP account. Then run from the same directory as the .tf file:
terraform validate to validate the file
terraform plan to review the config change plan without deploying anything
terraform apply to apply config changes to selected Google Cloud project
terraform destroy to destroy changes made by apply

1 Comment